






业务上经常存在一种现象,需要批量往表中插入多条数据,但在执行过程中,很可能因为唯一键冲突,而导致批量插入失败。
因此需要事先判断哪些数据是重复的,哪些是新增的。
比较常用的处理方法就是找出已存在的数据,并将其与不存在的数据区分开,已存在的数据一条条的更新。不存在的数据则批量更新。
这种方法会导致代码逻辑复杂,同时严重降低代码效率。
为了应对这种业务场景,MySQL有一种专有语法(insert into ... on duplicate key update)批量插入并更新唯一键数据
CREATE TABLE`user_card` (
`id`int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT ‘主键‘,
`uid`int(10) DEFAULT ‘0‘ COMMENT ‘用户ID‘,
`grade_id`int(10) DEFAULT ‘0‘ COMMENT ‘等级ID‘,
`name`varchar(255) DEFAULT ‘‘ COMMENT ‘姓名‘,
`money` decimal(10,2) DEFAULT ‘0.00‘ COMMENT ‘余额‘,PRIMARY KEY(`id`),UNIQUE KEY `uid_gid` (`uid`,`grade_id`) --业务上的唯一键
) ENGINE=MyISAM AUTO_INCREMENT=6 DEFAULT CHARSET=utf8 ;
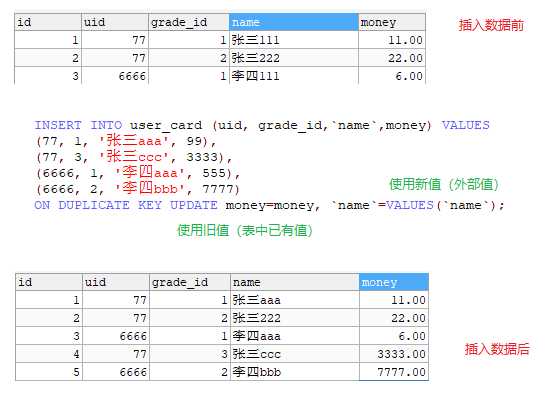
如上图所示,批量插入的数据,遇到已存在记录(根据唯一键,创表语句中的 UNIQUE KEY 判断)时,自动更新已有的数据。
如果表中有多个唯一键(可以是单列索引或复合索引),则任意一个唯一键(UNIQUE KEY)冲突时,都会自动更新数据。
通过 on duplicate key update 语法,可以指定哪些字段进行更新,哪些字段不进行更新。
所有操作均由SQL处理,不需要额外程序代码分析,能够大幅提高程序执行效率。
原文:https://www.cnblogs.com/funsion/p/11432758.html














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









