





随着数据时代和 AI 时代的到来,几乎所有的企业都在建设自己的大数据系统。为了提高数据处理能力,突破单机在计算与资源上的瓶颈,诸如 Hadoop、Spark、Flink 等分布式计算框架和基于 HDFS 的分布式存储系统成为大多数选择。实际工作中,大部分时间我们都在研发、部署和维护批处理、流处理程序,完成相应的业务需求,但是相信很多人都遇到过这样的事情:
- 需要对一批数据做探索性分析,所谓探索性即尚且没有明确的思路,需要不断的尝试,这时你无法形成完整方案写到代码文件、打包、正式部署。
- 临时有个任务需要验证一下,特别针对研发人员,你为这个任务写个正式代码文件、打包、部署显然过于繁琐,并且很多线上环境是不允许随便传代码的。
这里的问题就是,如何在分布式计算框架之上实现交互式运行代码?Notebook 显然成为首选。Notebook 是一类基于 Web 的交互式数据分析工具,比较流行的有 Jupyter、Zeppelin 等。Jupyter 是基于 Python 的,前身是 IPython,在单机数据分析上表现非常优异,特别是结合 pandas 库。而 Zeppelin 则以插件的形式对大多数分布式计算引擎提供了友好的支持,尤其是 Spark。
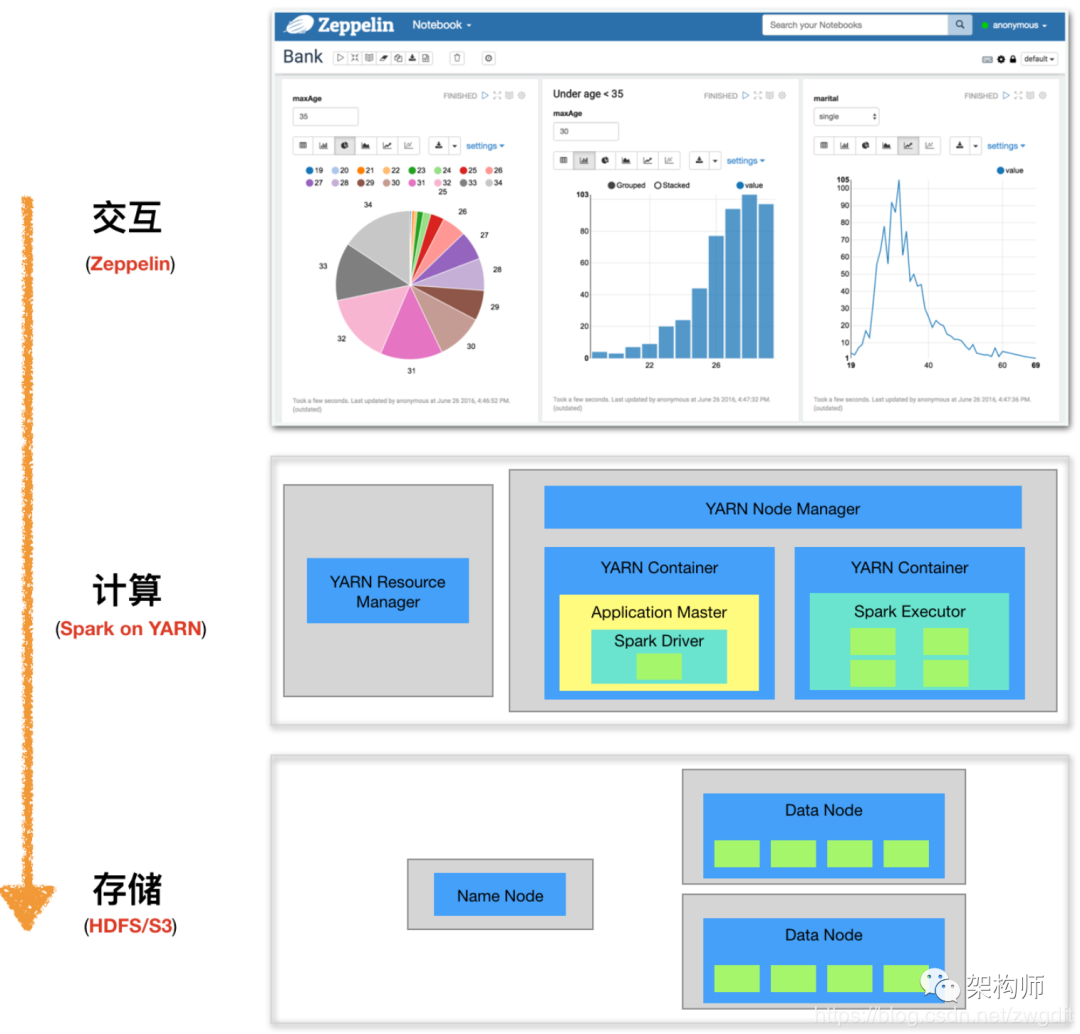
介绍 Zeppelin 的基本概念
介绍如何在 Zeppelin 中通过 Spark 进行数据分析
探讨如何为 Zeppelin 下的 Spark 配置资源
探讨 Zeppelin 与 Spark 进行交互的原理
基本概念
Zeppelin 的核心概念可归为两类:一类与执行引擎相关,一类与 Web UI 相关。
Zeppelin 本身并不提供任何数据处理功能,而是充分利用第三方执行引擎。为了能够灵活的接入这些执行引擎,Zeppelin 引入了 Interpreter 的概念。一个 Interpreter 对应一种执行引擎,用户可以根据需要来使用相应的功能。以 Spark 为例,其有 Spark(Scala)、pySpark、SparkSQL、SparkR 多种执行方式,每一种都有一个与之对应的 Zeppelin Interpreter,而这些 Interpreter 就构成了 Spark Interpreter Group。
在 Zeppelin 的 Web UI 上,可以根据需要创建自己的 Note,一个 Note 即一个新的文档,用于编辑与执行代码、可视化结果等。在 Note 中,为了便于管理,通常会将代码分段,每个片段只做一个功能,称为 Paragraph。在 Paragraph 中,需要首先指定该片段所用的 Interpreter,然后根据该 Interpreter 对应的编程语言来编写代码。比如在下右图中,指定了 pyspark 的 Interpreter,就需要用 Python 来编写代码。
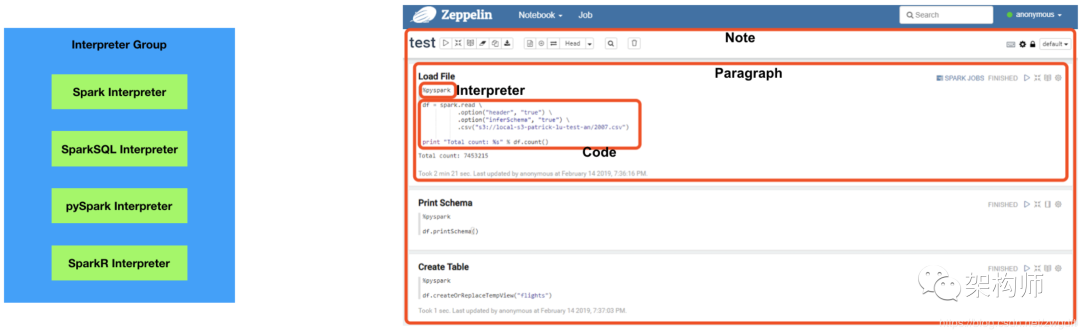
使用方法
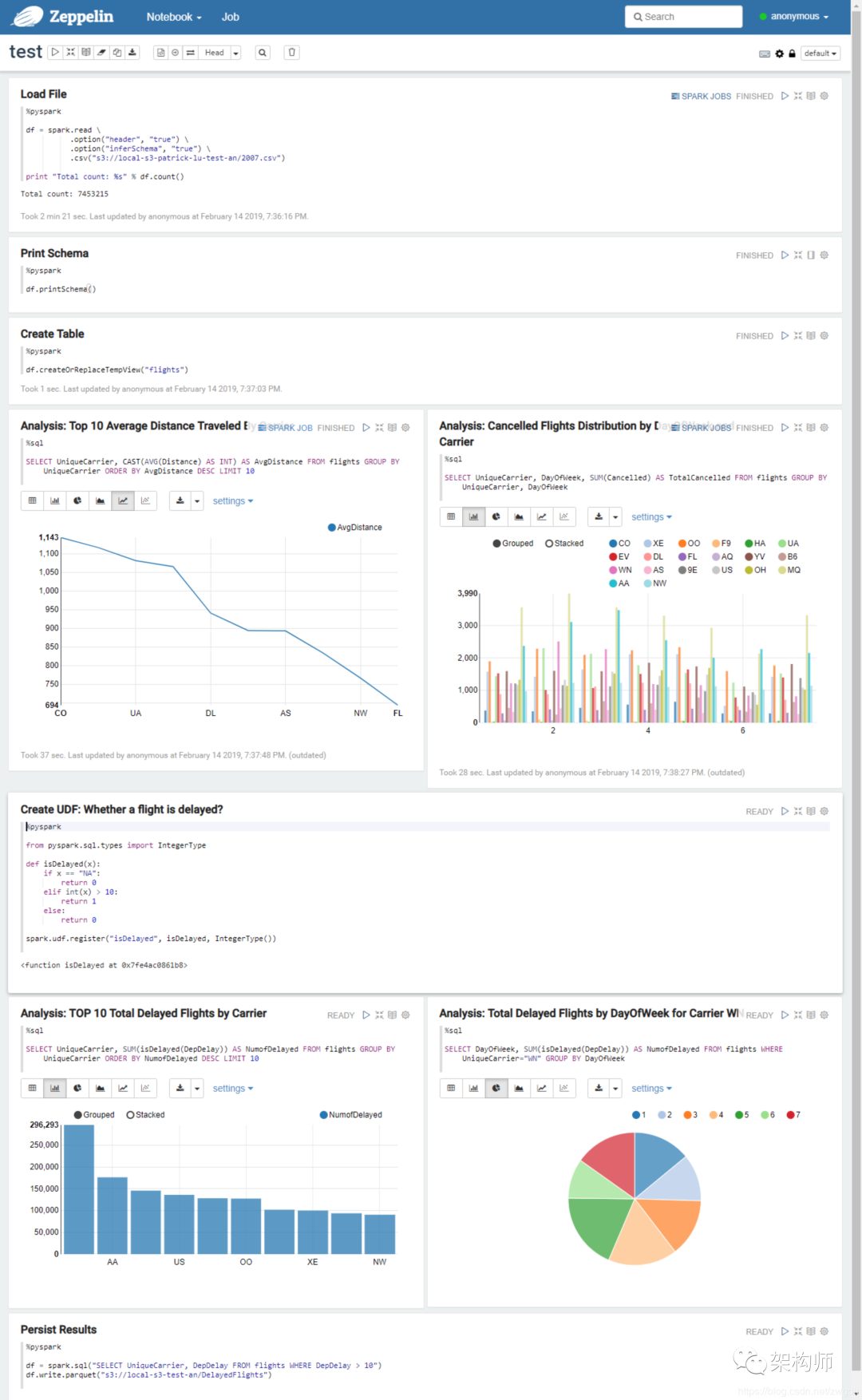
本节以一个示例来介绍如何在 Zeppelin 中使用 Spark SQL 进行数据分析,使用的数据来源于 2007 年美国航班延误信息,文件为 CSV 格式,约 745 万条数据。如需练习,请先下载数据并上传到 HDFS/S3 中。该示例主要包括以下几部分内容:第一,加载数据到 Spark 中。使用 pyspark (Interpreter)将 CSV 数据文件加载到 Spark 中,允许其根据 Header 自动推导 Schema,生成一个 DataFrame。需要说明的是,第一次运行时,会启动 Spark,从而花费一定的时间。
第二,创建 Table。根据 DataFrame 创建临时表,为后面使用 Spark SQL 进行分析做准备。
第三,使用 Spark SQL 进行数据分析与可视化。通过sql (Interpreter) 可直接使用 SQL 语言进行数据分析,默认是将数据结果以表格的形式打印出来,可根据需要选择相应的图形进行可视化。
第四,编写自己的 UDF。所谓 UDF,就是自定义的函数,可将一个或多个列的值作为输入,完成特定的计算功能。可根据需要定义相应的 UDF 函数,并注册到 Spark 中,之后即可在 SQL 中使用。
第五,将分析结果保存下来。通过 sql 分析的结果会直接返回到 UI 上,如果希望将其保存下来,则需要通过 pyspark 将结果输出到 DataFrame 中,从而调用相应的保存函数,将数据保存到相应格式的文件中,比如 Parquet。
资源配置
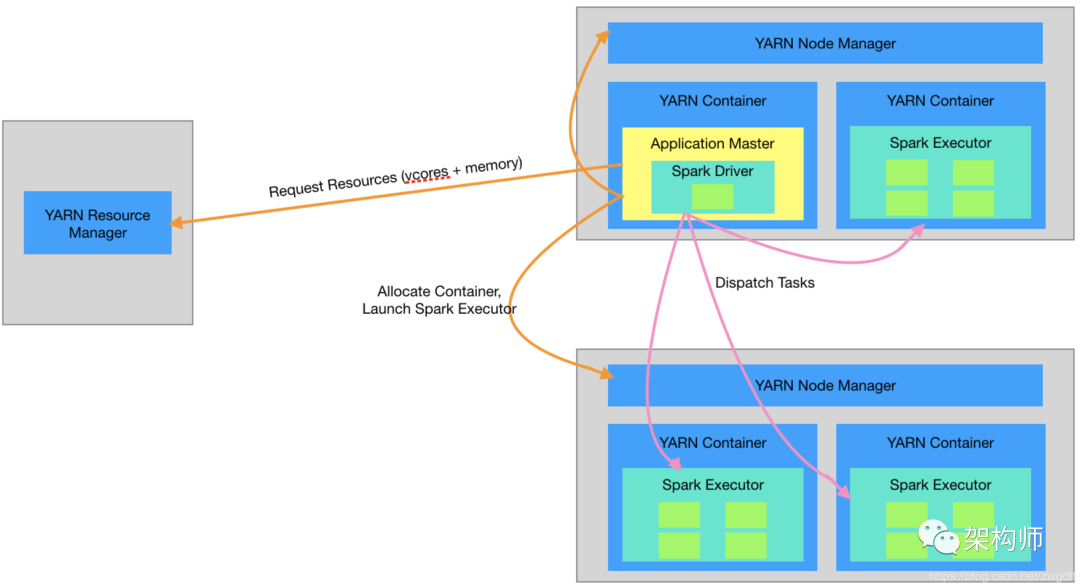
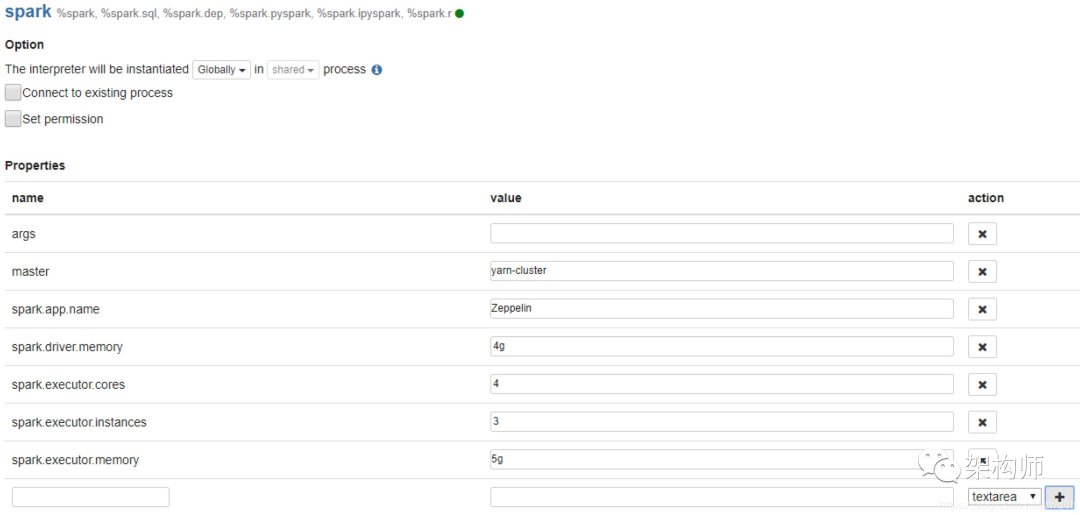
使用 Spark 作为计算引擎,自然要根据数据规模和计算性能来分配合适的资源,避免出现 OOM、执行慢等问题。如何充分利用有限集群资源进行数据计算,是我们在使用 Spark 过程中需要考虑的重要问题,而这个问题又可以拆分为两个子问题:如何把集群资源都分配掉,如何把分配的资源都用起来。这些与 Spark 相关的话题就不在这里展开叙述,笔者将另起博文来谈。本节主要结合上述的第一个子问题来谈谈 Zeppelin 下 Spark 的资源配置问题,主要为两块内容:一个是概括性的聊一聊怎么分配资源,另一个是如何将拟定的参数透过 Zeppelin 设置到 Spark 中。资源的分配主要考虑 CPU 和内存,前者决定了并行计算能力,后者决定了数据的存取速度。以 Spark on YARN Cluster 为例,由 YARN 负责系统资源调度,Spark Driver 负责任务的调度,将任务分发到各个 Executor 中执行。在资源分配上,需要分别考虑到这三个角色:YARN 可调度的资源有多少?单台机器上的资源并不能都交给 YARN 来调度,因为 OS 等其他系统也需要占用一定的资源,具体可调度的资源由 yarn.nodemanager.resource.cpu-vcores 和 yarn.nodemanager.resource.memory-mb 来配置。
为 Spark Driver 分配资源。内存是 Driver 需要关注的重点。如果 Spark 的 Action 会导致大量的数据需要返回到 Driver 中,就要考虑增加内存。比如,将大量执行结果收集过来,又或者加载的 Parquet 文件有大量的 Partition 信息需要缓存。
为 Spark Executor 分配资源。任务分发到 Executor 中执行时,可并行执行的个数取决于整体 Executor 有多少个 vcore,即(Executor 个数 * 单个 Executor 的 vcore 数),而任务执行过程中所消耗的内存也由 Executor 来承担。
工作原理
有了上面的认识,基本可以较好的使用 Zeppelin 了。但是,工程师的好奇心不会就此停止。在 Zeppelin 的 Web UI 中编写的代码,是如何提交到 Spark 中执行的?所谓 Interpreter 究竟是怎么工作的?要搞清楚这些问题,阅读源码自然是最佳途径。从ZeppelinRestApi.runParagraph到Paragraph.jobRun再到Spark Interpreter,一路读下去即可。本节将对相关工作原理做一个简单的介绍,源码部分读者可以根据个人兴趣选择性阅读。
如下图所示,整个系统分为三块:Zeppelin Web Client、Zeppelin Server 和 Spark,前两个为 Zeppelin 的前后端模块,第三个为计算引擎。要搞清楚整体的工作原理,需要搞清楚两个问题:第一,这三者之间是如何通信的?第二,Interpreter 是如何被调用的?
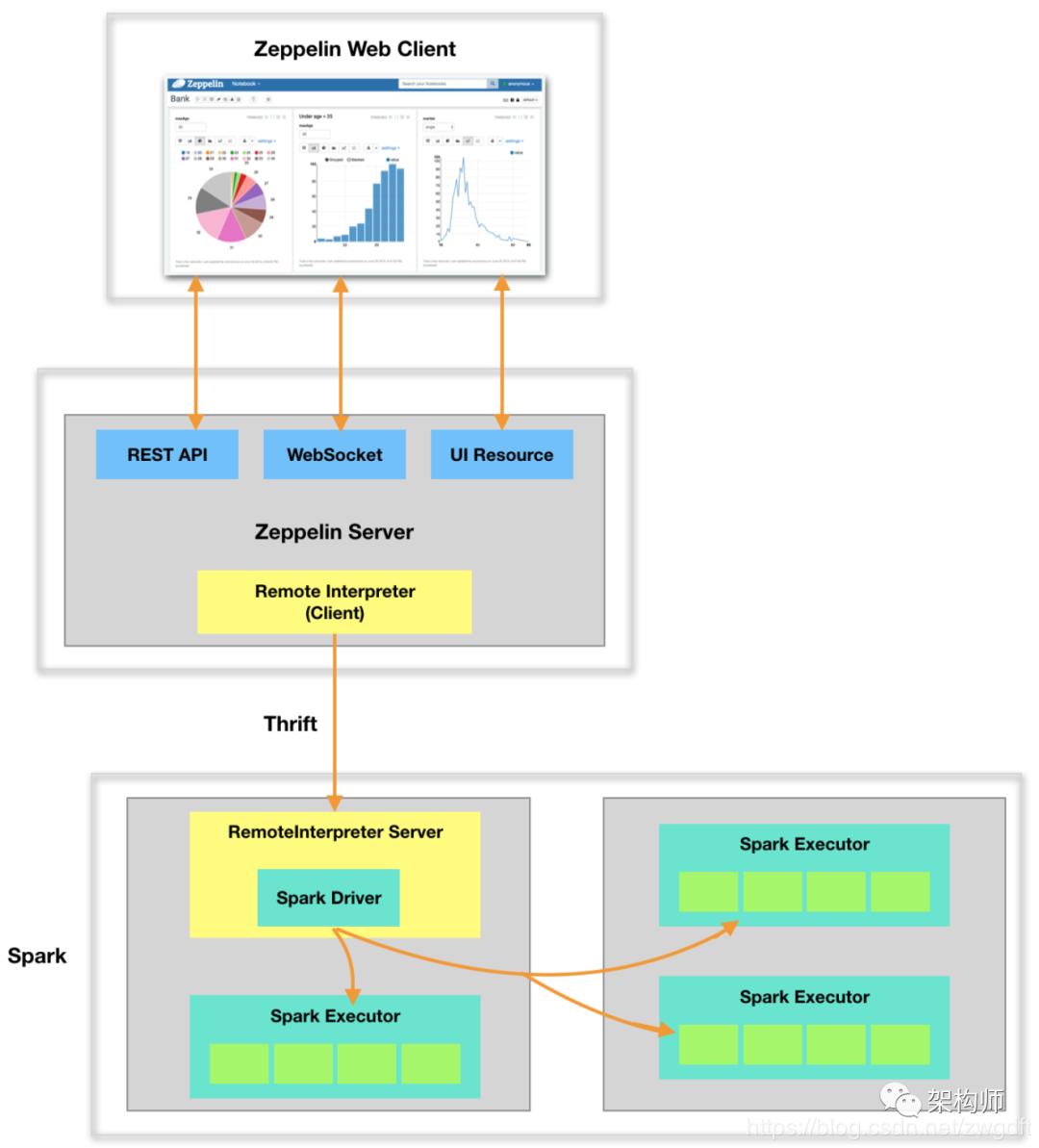
在 Spark 中,Driver 负责任务的调度。在 Zeppelin Web Client 上编写的代码片段只有传送到 Driver 进程中,才能得以执行。首先,Zeppelin Web Client 通过 REST API 与 Server 端进行交互,Server 收到后将其提交到任务队列中顺序执行。其次,Zeppelin Server 与 Spark Driver 是不同的进程,并且很可能不在同一台机器上,要实现这样的交互,自然少不了 RPC 通信,这里采用了 Thrift。Spark Driver 所在的进程本身是一个 Thrift Server 进程,由 Zeppelin Server 发起 RPC 调用,将相关信息传递过来。
每一个计算引擎都有自己对应的 Interpreter 类,实现了 interpret(String st, InterpreterContext context) 方法,用于执行具体代码。对于每一个 Paragraph 的执行,都会根据 NoteId 和 Interpreter 名字来获取对应的 Interpreter 实例。如果是第一次执行,便会根据配置创建对应的 Interpreter Group 及相关的 Interpreter 实例。在 Zeppelin Server 中,Interpreter 是由 RemoteInterpreter 来代理的(代理模式),其集成了 Thrift Client 相关接口,用于 RPC 调用。第一次执行时,Zeppelin Server 会启动 Spark,Spark 的主进程(Driver)入口是 RemoteInterpreterServer,其集成了 Thrift Server 相关接口,用于 RPC 调用。在 RPC 调用中,会获取对应的 Interpreter 实例来完成具体执行。
结束语
坦白地说,笔者并不是 Zeppelin 高手,只是在工作中遇到了文章开头提到的问题时才开始使用 Zeppelin,而在使用过程中又遇到些问题并加以解决,后来因为个人兴趣看了些源码,于是才有了这篇博文。期望对感兴趣的朋友有所帮助。作者:Mr-Bruce
原文:
https://blog.csdn.net/zwgdft/article/details/86417429
如有侵权或不周之处,敬请劳烦联系若飞(微信:1321113940)马上删除,谢谢!
·END·
架构师我们都是架构师!

关注架构师(JiaGouX),添加“星标”
获取每天技术干货,让我们一起成为牛逼的架构师
微信技术群请加若飞微信:1321113940 进群
投稿、合作邮箱:admin@137x.com














 1703
1703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









