






Spark 是一个非常好的计算平台,支持多种语言,同时基于内存的计算速度也非常快。整个开源社区也很活跃。
但是Spark在易用性上面还是有一些美中不足。 对于刚接触的人来说,上手以及环境搭建还是有一些困难。 另外,如果希望将结果绘制成图表分享给别人,还需要很长一段路程。
目前已经有一些解决方案:
- 【TBD】Jupyter Notebook
- 使用很广泛,但是看起来主要还是以前ipython-notebook的增强版。
- 目前笔者对其了解不多
- Spark 母公司DataBricks提供的DataBricks Community Edition, 里面自带Spark集群 + Notebook。
- 易用性、功能性都很不错。缺点是集群架设在AWS之上,无法跟自己本地的Spark 集群连在一起
- Apache Zeppelin
- 这是一个刚刚从Incubation转正的项目
- 但是已经在各大公司均有采用,比如美团、微软等等
- 本文主要就是介绍如何在本地搭建一个Zeppelin 使得Spark更易用,同时可以很方便的将自己的工作成功展示给客户
借用别人的一个效果图镇楼^_^

注意:
- Zeppelin自带Spark实例,您无需自己构建一个Spark 集群就可以学习Zeppelin
- Zeppelin 当前(2016年8月19日)最新版本0.6.1, 只兼容2.0+
1)如果您本地有Spark 集群并且版本是1.6.1 + Scala 2.10 , 请下载Zeppelin 0.6.0的版本
2)如果官网的速度比较慢,可以参考下面的方式到百度盘下载
链接: http://pan.baidu.com/s/1ctBBJo 密码: e68g
1、 下载
如果您需要的是0.6.0的版本,可以参考上面百度盘的下载链接。
如果您需要的是0.6.1+的版本,可以直接到官网下载, 里面的Mirror下载速度一般还不错
2、 安装
版本: Zeppelin 0.6.0 + 自建Spark集群(1.6.1)
感觉Zeppelin还是不太成熟,并开箱就用,还需要不少人工调整才能正常工作
1)解压之后,首先需要从模板创建一个新的zeppelin-env.sh, 并设置SPARK_HOME. 比如:
- 1export SPARK_HOME=/usr/lib/spark
如果是基于Hadoop 或者 Mesos 搭建的Spark 集群,还需要进行另外的设置。
2)从模板创建一个新的zeppelin-site.xml,并将之前的8080端口改到比如8089,避免与Tomcat等端口冲突
- <property>
- <name>zeppelin.server.port</name>
- <value>8089</value>
- <description>Server port.</description>
- </property>
3)替换jackson相关类库
a)默认自带的是2.5.*, 但是实际使用的时候指定的是2.4.4
b)并且可能2.4.4 与 2.5.* 并不完全兼容。
c)因此需要使用2.4.4 替换2.5.* , 有下面3个jar需要替换:
- jackson-annotations-2.4.4.jar
- jackson-core-2.4.4.jar
- jackson-databind-2.4.4.jar
d)这真的是非常坑人的一个地方。。。
做完上诉几步之后,就可以启动啦:
启动/停止命令:
- bin/zeppelin-daemon.sh stop/start
启动之后,打开http://localhost:8089 就可以看到Zeppelin的主界面啦
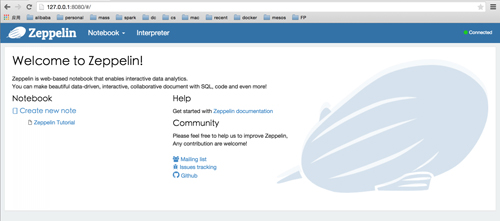
3. 配置Spark解释器
Spark Interpreter的配置非常简单,可以直接参考下图的配置方式:
4. 几点使用经验
Zeppline自带比较详细的Tutorial, 各位看自带的notebook tutorial 可能效果更好。 但是我在第一次使用的时候,遇到了不少坑,在此记录下来,给大家做个参考:
(1) 任务提交之后不会自动停止
当Zeppelin 提交任务之后,可以看到Spark Master UI 上面,当前任务即使执行完成了,也不会自动退掉
这是因为,Zeppelin 默认就像人手工运行了spark-shell spark://master-ip:7077 一样, 除非手动关闭shell命令,否则会一直占用着资源
解决办法就是将spark 解释器(interpreter) 重启
手动的重启办法:
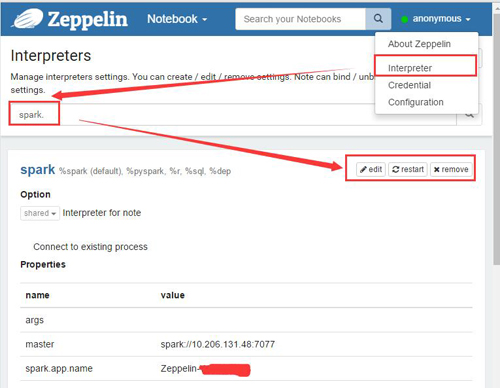
1.打开Interpreter界面,搜索到Spark部分并点击重启
2.推荐: 调用Restful API 进行重启。
a.可以通过Chrome的Network 监控看一下点击restart之后具体调用的API的情况。如下图:
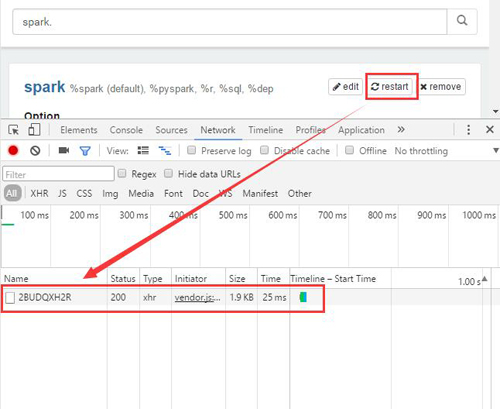
b.这个ID(2BUDQXH2R)在各自的环境可能各不相同。另外这个API是PUT的方式,可以直接使用下面的python代码在UI上自动重启
- %python
- import requests
- r = requests.put("http://IP:8089/api/interpreter/setting/restart/2BUDQXH2R")
- print r.text
(2) 异常提示:Cannot call methods on a stopped SparkContext
比如我们在Spark Master UI 上面将当前job kill 之后,在Zeppelin这边重启执行任务就会遇到这个异常信息。
解决办法很简单: 重启解析器
(3) 不要主动调用 sc.stop()
这是官方明确说明的:scala 的spark-shell 自动初始化了SparkContext / SqlContext 等等
不能自己调用sc.stop() 之后重启创建一个SparkContext
可能笔者水平原因,尝试自己创建新的sc 之后,各种奇奇怪怪的问题
(4) 关于python module
Python Interpreter可以使用当前Zeppelin所在机器的python 所有的model
同时支持python 2 与 python 3
这是一个很有用的功能,比如我使用spark将数据计算完成之后,生成了一个并不太大的csv文件。这个时候完全可以使用Pandas强大的处理能力来进行二次处理,并最终使用Zeppelin的自动绘图能力生成报表
与Tableau之类的BI工具相比功能差了一些,不过各有所长。Zeppelin 对程序员来说可以算是非常方便的一个工具了。 对日常的一些简单报表的工作量大大减小了
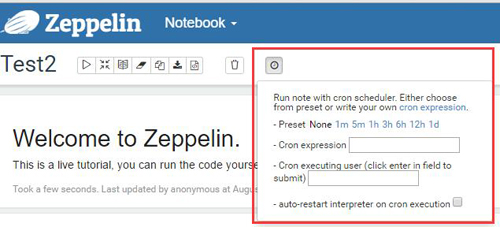
(5) 可以设置自动运行时间
在整个Note的最上端,可以设置当前notebook 定期执行。 而且注意: 还可以设置执行完成之后自动重启interpreter 参考下图:
本文作者:rangerwolf
来源:51CTO















 2927
2927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









