





Python3 parse.urlencode() 与parse.unquote()
URL编码与解码
一.parse.urlencode() 与parse.unquote()
urllib 和urllib.request都是接受URL请求的相关模块,但是提供了不同的功能。两个最显著的不同如下:
1.urllib 仅可以接受URL,不能创建 设置了headers 的Request 类实例;
2.但是 urllib 提供 urlencode 方法用来GET查询字符串的产生,而urllib.request 则没有。(这是 urllib 和urllib.request 经常一起使用的主要原因)
3.编码工作使用urllib的parse.urlencode()函数,帮我们将key:value这样的键值对转换成"key=value"这样的字符串,解码工作可以使用urllib的parse.unquote()函数。(注意,不是urllib.request.urlencode() )
例子一
#导入parse模块
from urllib import parse
import urllib.request
url = 'https://www.baidu.com/s?'
#定义一个字典
wd ={"wd":"传智播客"}
# urlencode() 接受的参数是一个字典
pw=parse.urlencode(wd)
print(pw)
wd1 ={"wd1":"传"}
pw1=parse.urlencode(wd1)
print(pw1)
wd2={"wd2":"智"}
pw2=parse.urlencode(wd2)
print(pw2)
wd3={"wd3":"播"}
pw3=parse.urlencode(wd3)
print(pw3)
wd4={"wd4":"客"}
pw4=parse.urlencode(wd4)
print(pw4)
# 通过parse.unquote()方法进行解码,把 URL编码字符串,转换回原先字符串。
print(parse.unquote("wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2"))
运行的结果:
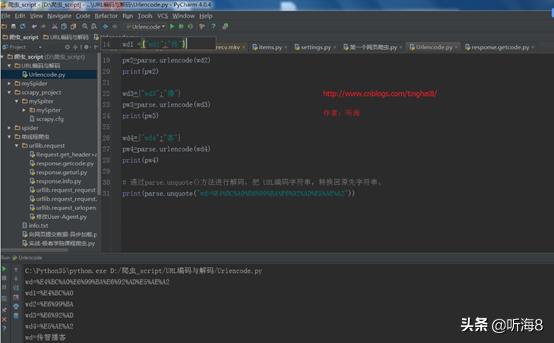
wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2
wd1=%E4%BC%A0
wd2=%E6%99%BA
wd3=%E6%92%AD
wd4=%E5%AE%A2
wd=传智播客
二.URL编码与解码工具
http://tool.chinaz.com/Tools/urlencode.aspx
URL编码与解码
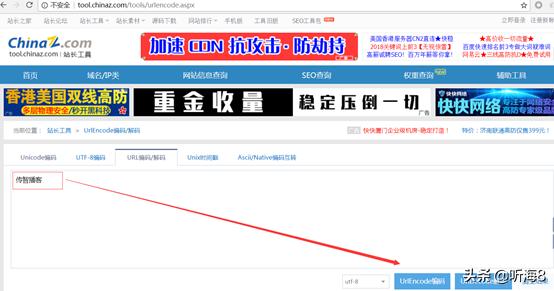
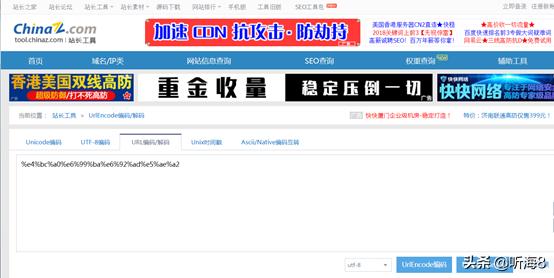
三.一般HTTP请求提交数据,需要编码成 URL编码格式,然后做为url的一部分,或者作为参数传到Request对象中。
Get方式
urllib库与urllib.request库的结合应用
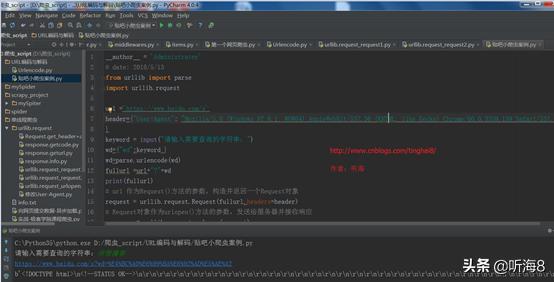
例子一:贴吧小爬虫案例
from urllib import parse
import urllib.request
url ='https://www.baidu.com/s'
header={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"
}
keyword = input("请输入需要查询的字符串:")
wd={"wd":keyword }
wd=parse.urlencode(wd)
#拼接完整的URL
fullurl =url+"?"+wd
print(fullurl)
# url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request(fullurl,headers=header)
# Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
html = response.read()
print(html)
运行结果:
例子二:批量爬取贴吧页面数据
第一步:先观察贴吧各页之间的规律
第一页:http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0
第二页: http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=50
第三页: http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=100
从中得出分页之间的规律:pn = (page - 1) * 50
步骤分析:
简单写一个小爬虫程序,来爬取百度贴吧的所有网页。
先写一个main,提示用户输入要爬取的贴吧名,并用parse.urlencode()进行转码,然后组合url,假设是lol吧,那么组合后的url就是:http://tieba.baidu.com/f?kw=lol
# 模拟 main 函数
if __name__ == "__main__":
kw = input("请输入需要爬取的贴吧:")
# 输入起始页和终止页,str转成int类型
beginPage = int(input("请输入起始页:"))
endPage = int(input("请输入终止页:"))
url = "http://tieba.baidu.com/f?"
key = parse.urlencode({"kw" : kw})
# 组合后的url示例:http://tieba.baidu.com/f?kw=lol
url = url + key
print(url)
tiebaSpider(url, beginPage, endPage)
接下来,我们写一个百度贴吧爬虫接口,我们需要传递3个参数给这个接口, 一个是main里组合的url地址,以及起始页码和终止页码,表示要爬取页码的范围。
def tiebaSpider(url, beginPage, endPage):
"""
作用:负责处理url,分配每个url去发送请求
url:需要处理的第一个url
beginPage: 爬虫执行的起始页面
endPage: 爬虫执行的截止页面
"""
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
filename = "第" + str(page) + "页.html"
# 组合为完整的 url,并且pn值每次增加50
fullurl = url + "&pn=" + str(pn)
print(fullurl)
print(filename)
#print fullurl
# 调用loadPage()发送请求获取HTML页面
html = loadPage(fullurl, filename)
# 将获取到的HTML页面写入本地磁盘文件
writeFile(html, filename)
写一个爬取网页的函数loadPage
def loadPage(url, filename):
'''
作用:根据url发送请求,获取服务器响应文件
url:需要爬取的url地址
filename: 处理的文件名
'''
print("正在下载" + filename)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"
}
request = urllib.request.Request(url, headers = headers)
response = urllib.request.urlopen(request)
return response.read()
最后如果我们希望将爬取到了每页的信息存储在本地磁盘上,我们可以简单写一个存储文件的接口。
def writeFile(html, filename):
"""
作用:保存服务器响应文件到本地磁盘文件里
html: 服务器响应文件
filename: 本地磁盘文件名
"""
print "正在存储" + filename
with open(filename, 'w') as f:
f.write(html)
print "-" * 20
完整的程序实现:
__author__ = 'Administrator'
# date: 2018/5/13
from urllib import parse
import urllib.request
def loadPage(url, filename):
'''
作用:根据url发送请求,获取服务器响应文件
url:需要爬取的url地址
filename: 处理的文件名
'''
print("正在下载" + filename)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"
}
request = urllib.request.Request(url, headers = headers)
response = urllib.request.urlopen(request)
return response.read()
def writeFile(html, filename):
"""
作用:保存服务器响应文件到本地磁盘文件里
html: 服务器响应文件
filename: 本地磁盘文件名
"""
print("正在存储" + filename)
with open(filename, 'w') as f:
f.write(html)
print("-" * 20)
def tiebaSpider(url, beginPage, endPage):
"""
作用:负责处理url,分配每个url去发送请求
url:需要处理的第一个url
beginPage: 爬虫执行的起始页面
endPage: 爬虫执行的截止页面
"""
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
filename = "第" + str(page) + "页.html"
# 组合为完整的 url,并且pn值每次增加50
fullurl = url + "&pn=" + str(pn)
print(fullurl)
print(filename)
#print fullurl
# 调用loadPage()发送请求获取HTML页面
html = loadPage(fullurl, filename)
# 将获取到的HTML页面写入本地磁盘文件
writeFile(html, filename)
# 模拟 main 函数
if __name__ == "__main__":
kw = input("请输入需要爬取的贴吧:")
# 输入起始页和终止页,str转成int类型
beginPage = int(input("请输入起始页:"))
endPage = int(input("请输入终止页:"))
url = "http://tieba.baidu.com/f?"
key = parse.urlencode({"kw" : kw})
# 组合后的url示例:http://tieba.baidu.com/f?kw=lol
url = url + key
print(url)
tiebaSpider(url, beginPage, endPage)















 3613
3613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









