





大佬原话:深入理解一个技术的工作机制是灵活运用和快速解决问题的根本方法,也是唯一途径。对于HDFS来说除了要明白它的应用场景和用法以及通用分布式架构之外更重要的是理解关键步骤的原理和实现细节。
HDFS是一个分布式文件系统,用于存储和管理文件。
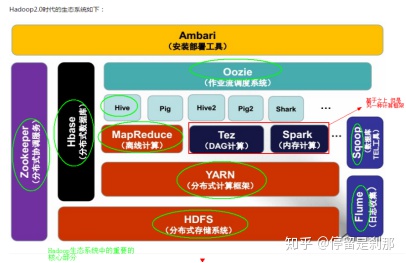
一、HDFS的功能模块及原理
1.1 HDFS中的文件在物理上是分块存储(block)
-- 文件被切分成固定大小的数据块block
• 默认数据块大小为128MB (hadoop2.x),可自定义配置
• 若文件大小不到128MB ,则单独存成一个block
-- 一个文件存储方式
• 按大小被切分成若干个block ,存储到不同节点上
• 默认情况下每个block都有3个副本
-- Block大小和副本数通过Client端上传文件时设置,文件上传成功后副本数可以变更,Block Size不可变更
文件的各个Block的存储管理由datanode节点承担,datanode是HDFS集群从节点,每一个Block都可以在多个datanode上存储多个副本
2.1.1 HDFS组成成员:DataNode(DN)
• 本地磁盘目录存储数据(Block),文件形式
• 同时存储Block的元数据(md5值)信息文件
• 启动DN进程的时候会向NameNode汇报Block信息
• 通过向NN发送心跳保持与其联系(3秒一次),如果NN 10分钟没有收到DN的心跳,则认为其已经lost,并copy其上的block到其它DN
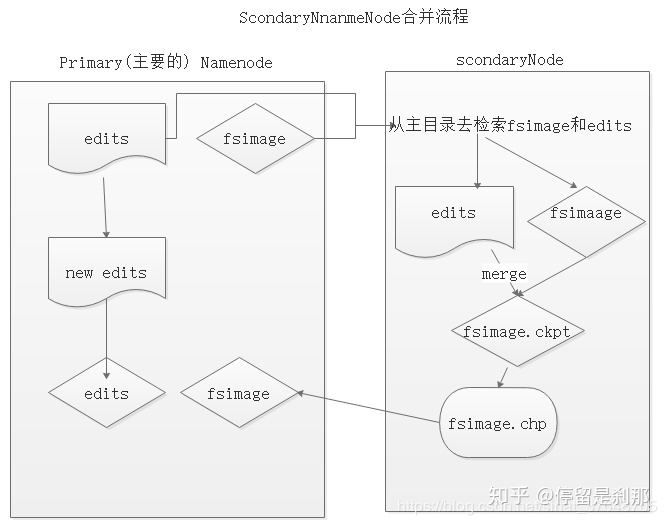
2.1.2 HDFS组成二把手:SecondaryNameNode(SNN)
– 它的主要工作是帮助NN合并edits log文件,减少NN启动时间,它不是NN的备份(但可以做备份)。
– SNN执行合并时间和机制
•A、根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒。
•B、根据配置文件设置edits log大小 fs.checkpoint.size 规定edits文件的最大值默认是64MB
首先是NN中的Fsimage和edits文件通过网络拷贝,到达SNN服务器中,拷贝的同时,用户的实时在操作数据,那么NN中就会从新生成一个edits来记录用户的操作,而另一边的SNN将拷贝过来的edits和fsimage进行合并,合并之后就替换NN中的fsimage。之后NN根据fsimage进行操作(当然每隔一段时间就进行替换合并,循环)。那么通过SNN合并之后的新的fsimage和edits log会被推送到NN中并且替换原来的fsimage和edits log,这样NN 里面隔段时间就是新的数据。
2.1.3 HDFS组成一把手:NameNode(NN)
1、NameNode主要功能:接受客户端的读写服务。
2、NameNode保存metadata(元数据,除了文件内容之外的都是元数据)信息包括:
• 文件owership(归属)和permissions(权限)
• Block保存在哪个DataNode信息(由DataNode启动时上报,不保存在磁盘)
3、NameNode的metadate信息在启动后加载到内存:
1)metadata存储到磁盘文件名为“fsimages”(NN主要根据fsimage来进行数据操作,SNN利用其进行合并)
2)Block位置信息不会保存到fsimage
3)edits记录对metadata的操作日志
4、fsimage是元数据在磁盘中存储的一份数据的文件名,当我们操作一份数据的时候,并不是马上在fsimage中进行修改,而是由edits来记录操作日志,之后在某个时间让edits与fsimage合并。
当删除一个文件的时候其实并不是马上删除,而是在edits log中记录,到一定时间与fsimage通过SNN进行合并的时候进行删除。由于涉及大多的IO和消耗CPU,所以在NN中不做数据操作的合并,而是让另一个机器的CPU去计算实现SNN根据时间来不断合并各个NN,这样用户体验感比较好,速度也是比较快。















 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









