





上一篇我们以马云的微博为例,介绍了如何使用requests将马云的所有微博爬下来(传送门:马云这些年在微博上都说过些什么——小白python爬虫实战(1)),爬下来之后,我们最终想要得到的是一个像下图一样的词云↓

那么词云该怎么做呢?
还是以上篇文章爬出来的马老板的全部微博文本jackma.txt为例。
先从最朴素的词云开始:

像上图这样的词云,还没有特定的图案和花里胡哨的展示方式,这是怎么做出来的呢?
老样子,先直接——
上! 代! 码!
import collections # 词频统计import jieba # 结巴分词import wordcloud # 词云生成import matplotlib.pyplot as plt # 图像展示# 文件路径path_txt = 'E:/你的文件路径/jackma.txt'# 打开txt文件text = open(path_txt, encoding="utf-8").read()# 文本分词,精确模式seg_list_exact = jieba.cut(text, cut_all=False)object_list = []# 自定义去除词remove_words = [u'的', u'给', u'和', u'并', u'是', u'你', u'人', u'不', u'去', u'都', u'才', u'又', u'那', u'从', u'过', u'中', u'做', u'了', u'但', u'们', u'在', u'也', u'很', u'让', u'他', u'被', u'啥', u'我', u'有', u'等', u'对', u'及', u'年', u'后', u'万', u'把', u'时', u'来', u'为', u'啊', u'能', u'或', u'会', u'说', u'这', u'要', u'就', u'还', u'而', u'着', u'到', u'好', u'最', u'多', u'上', u'想', u'看']# 循环读出每个分词,将不在去除词中的分词添加到列表for word in seg_list_exact: if word not in remove_words: object_list.append(word)# 对分词进行词频统计word_counts = collections.Counter(object_list) # 获取前100最高频的词word_counts_top100 = word_counts.most_common(100)print(word_counts_top100) # 输出检查# 词云设置wc = wordcloud.WordCloud( # 设置字体格式防止乱码 font_path='C:/Windows/Fonts/simhei.ttf', # 设置背景颜色 background_color="white", # 设置最多显示词数 max_words=200, # 设置字体最大值 max_font_size=100)# 生成词云wc.generate_from_frequencies(word_counts)# 显示词云plt.imshow(wc)# 关闭坐标轴plt.axis('off')# 图像显示plt.show()(※关注 呔塔 公众号后台回复 “词云” 获取本篇完整代码。)
运行上面代码后弹出窗口中即显示生成的词云
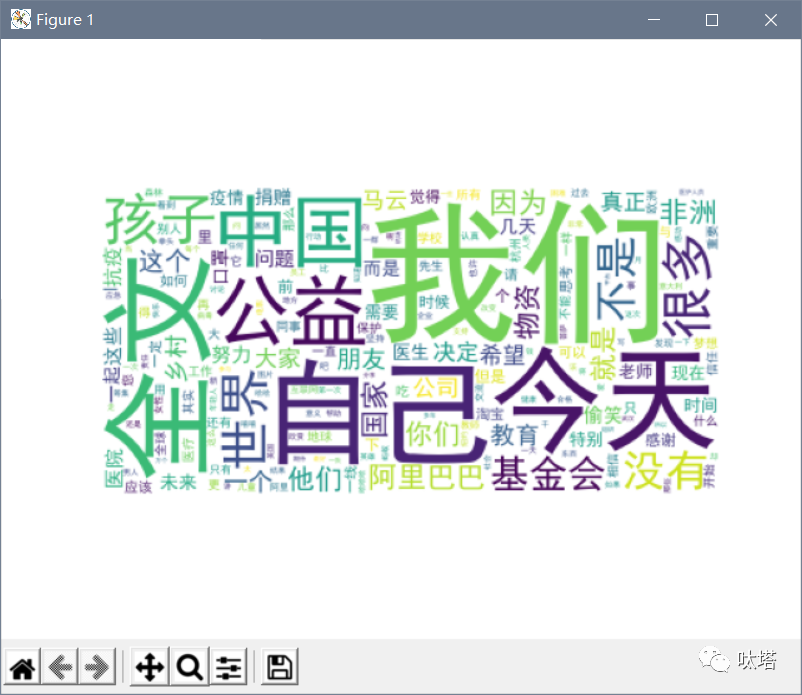
如果想要将词云保存为图片,既可以在弹出窗口的底部点击文件小图标进行图片另存为,也可以在代码末尾再加一行保存为图片的代码:
wc.to_file('jackma.png')同样的,这里也可以自定义路径,若无指定路径则默认图片生成在工程文件夹下。
上面这串代码是如何实现生成词云的呢?
这里主要用到四个库,它们分别用来进行分词、词频统计、生成词云和展示图像。
import collections # 词频统计import jieba # 结巴分词import wordcloud # 词云生成import matplotlib.pyplot as plt # 图像展示首先将txt文本通过jieba进行分词切割成一个一个的词语,再通过词频统计计算出每个词语出现的次数,然后就能生成对应的词云。
需要注意的是,在jieba分词的过程中,有很多停止词是我们不需要出现在词云中的,比如说“的”、“也”、“啊”诸如此类的词语,为了将这些词语过滤掉,我们需要设定去除词,可以使用专门的停止词包。这里我们自定义了一个去除词词库,在实际应用过程中方便灵活更改。
自定义去除词库之后,用一个for循环将这些不需要的词筛出来,然后就可以对剩下的词汇进行词频统计了。
object_list = []# 自定义去除词remove_words = [u'的', u'给', u'和', u'并', u'是', u'你', u'人', u'不', u'去', u'都', u'才', u'又', u'那', u'从', u'过', u'中', u'做', u'了', u'但', u'们', u'在', u'也', u'很', u'让', u'他', u'被', u'啥', u'我', u'有', u'等', u'对', u'及', u'年', u'后', u'万', u'把', u'时', u'来', u'为', u'啊', u'能', u'或', u'会', u'说', u'这', u'要', u'就', u'还', u'而', u'着', u'到', u'好', u'最', u'多', u'上', u'想', u'看']# 循环读出每个分词,将不在去除词中的分词添加到列表for word in seg_list_exact: if word not in remove_words: object_list.append(word) # 对分词进行词频统计word_counts = collections.Counter(object_list)进行完词频统计,就可以着手生成词云,生成词云前可以对诸如字体大小、背景颜色之类的进行设置,注意需要指定字体文件,不然容易乱码。
# 词云设置wc = wordcloud.WordCloud( # 设置字体格式防止乱码 font_path='C:/Windows/Fonts/simhei.ttf', # 设置背景颜色 background_color="white", # 设置最多显示词数 max_words=200, # 设置字体最大值 max_font_size=100)然而,上面代码生成的词云太朴素了,如何让词云花里胡哨起来像下面一样呢?

这里我们将词云做成了蚂蚁集团logo的样子,要实现上述效果,在上面代码的基础上首先要再引入两个库,用于文件数据处理与图像数据处理。
import numpy as np # 数据处理from PIL import Image # 图像处理既然要让词云形成特定的形状,首先要引入一张图片,作为词云的背景图,这里我们用的就是蚂蚁集团的logo。
mask = np.array(Image.open(r'C:\Users\Desktop\AntGroup.jpg'))
接下来我们只需要在词云设置中加上一行,设定好上面引入的mask作为背景就可以了。
mask=mask运行程序,我们得到了下面这样的词云,它的形状已经是背景图片的蚂蚁集团logo样式了,然而颜色还没有设定。
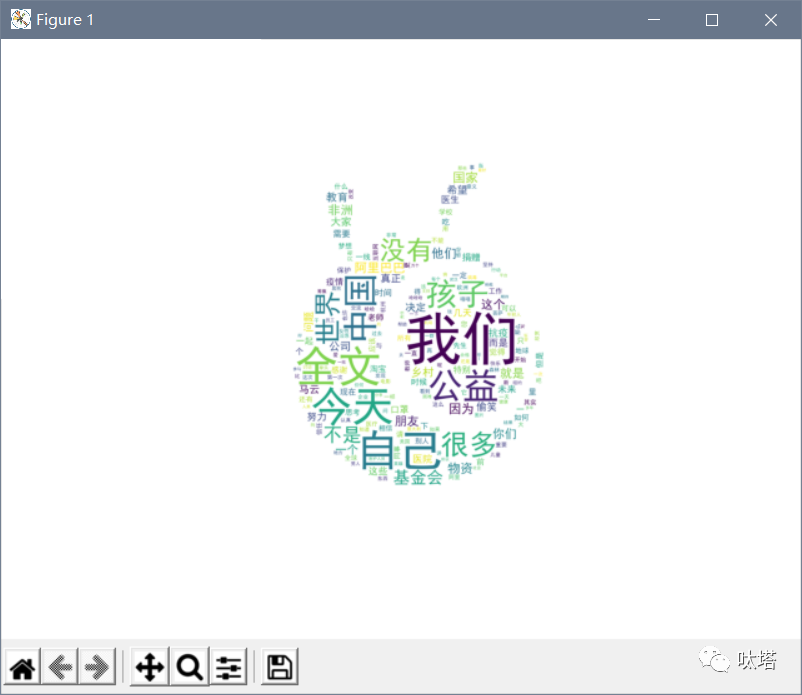
将词云颜色设置成背景图样式,只需在生成词云前获取背景图颜色方案,并将方案给词云即可。
# 获取背景图颜色方案image_colors = wordcloud.ImageColorGenerator(mask)# 将背景图颜色方案给词云wc.recolor(color_func=image_colors)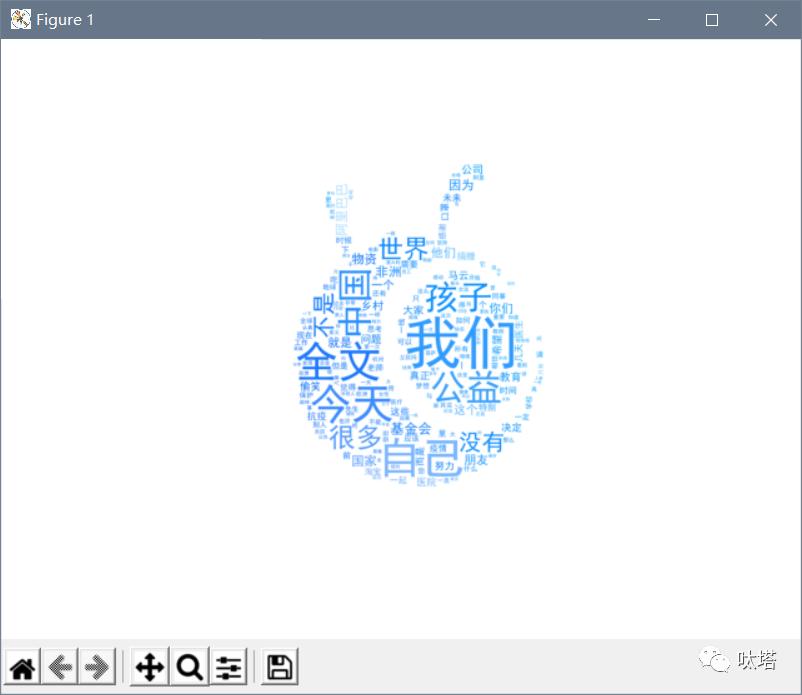
以上就是用python制作词云的基本方法,至于词云究竟要做出怎样的style,就看各位小伙伴各显神通了。
关注 呔塔 公众号后台回复 “词云” 获取本篇完整代码。
戳文末二维码,关注呔塔公众号,这里有杂记、爬虫和数据可视化。
↓↓↓
















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









