





淘宝登录
爬数据的前提是要先登录,那么先来说怎么使用python3+selenium登录淘宝的。
一、登录前的准备工作
关于一开始做登录时,一直会出现滑块,这个滑块怎么滑都通过不了,后来才知道是淘宝有对selenium这个框架做了反爬限制。然后这时候就去网上寻找大量淘宝登录的代码,试了无数的代码都不行,最后发现了这个宝藏文章 淘宝爬虫之自动登录。
关于上面那个文章我来总结一下最重要的两个点。
1.需要修改chromedriver里面的一个变量名,我们只需要将这个变量名改成其他的就好了(chromedriver就是谷歌浏览器的驱动,对于不同系统有着不同的并且不同版本的chromedrive,这是下载chromedrive驱动的地址http://chromedriver.storage.googleapis.com/index.html),我下载的是76.0.3809.68版本的,大家可以下载自己需要的版本,下载好chromedrive之后修改chromedriver里面的信息。
perl -pi -e 's/cdc_/dog_/g' /path/to/chromedriver
//替换完成后查找下,如果查找不到说明替换成功了
perl -ne 'while(/cdc_/g){print "$&n";}' /path/to/chromedriver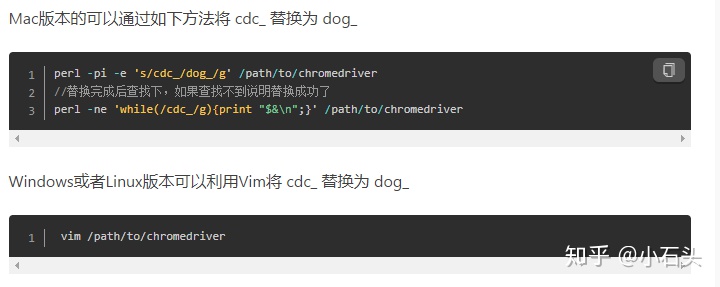
我是用nodepad++打开chromedrive.exe 把cdc_全部替换成了dog_

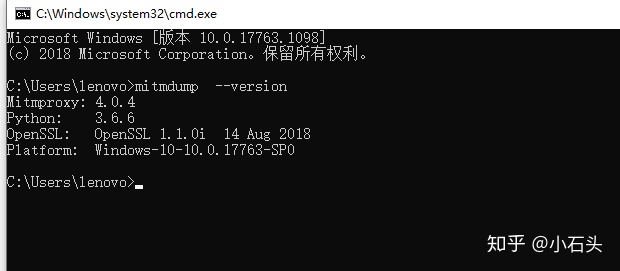
2.针对navigator.webdriver 通过mitmproxy做中间人代理将对应的屏蔽代码注入到原网站中从而达到规避检测目的,就是需要启一个代理程序,这个需要安装一下mitmproxy包,安装mitmproxy包的方式也比较简单直接运行 pip install mitmproxy就行,但是安装这个包的 window 系统需要首先安装 Microsoft Visual C++ V14.0以上 才行。所以系统要是没有Microsoft Visual C++ V14.0需要先安装一下,可以在Microsoft Visual C++ V14.0下载直接下载即可,安装完了,在命令行进行安装 mitmproxy就可以了。window可以在命令行打mitmdump --version 查看是否安装成功
二、开始写登录代码和代理代码
1.首先针对navigator.webdriver 通过mitmproxy做中间人代理将对应的屏蔽代码注入到原网站中从而达到规避检测目的,新建一个HttpProxy.py文件,代码如下:
# -*- coding:UTF-8 -*-
TARGET_URL = 'https://g.alicdn.com/secdev/sufei_data/3.8.1/index.js'
INJECT_TEXT = 'Object.defineProperties(navigator,{webdriver:{get:() => false}});'
def response(flow):
if flow.request.url.startswith(TARGET_URL):
flow.response.text = INJECT_TEXT + flow.response.text
print('注入成功')
if 'um.js' in flow.request.url or '115.js' in flow.request.url:
# 屏蔽selenium检测
flow.response.text = flow.response.text + INJECT_TEXT2.再新建一个startproxy.py文件,直接运行这个py文件就可以启动9000端口的代理,对应的监听网址在http://127.0.0.1:9020/,代码如下:
# -*- coding:UTF-8 -*-
from mitmproxy.tools._main import mitmweb
mitmweb(args=['-s', './HttpProxy.py', '-p', '9000', '--web-port', '9020'])3.把我们之前下载的chromedrive.exe,放在这个文件夹下,最后就是淘宝的登录代码了,命名为login.py,代码如下:
# -*- coding:UTF-8 -*-
import time
from datetime import date, timedelta
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver import ActionChains
from selenium.webdriver.chrome.options import Options
import platform
import os
TB_LOGIN_URL = 'https://login.taobao.com/member/login.jhtml'
class Login:
def __init__(self, account, password):
self.browser = None
self.account = account
self.password = password
def open(self, url):
self.browser.get(url)
self.browser.implicitly_wait(20)
def start(self):
# 1 初始化浏览器
self.init_browser()
# 2 打开淘宝登录页
self.browser.get(TB_LOGIN_URL)
time.sleep(1)
# 3 输入用户名
self.write_username(self.account)
time.sleep(1.5)
# 4 输入密码
self.write_password(self.password)
time.sleep(1.5)
# 5 如果有滑块 移动滑块
if self.lock_exist():
self.unlock()
# 6 点击登录按钮
self.submit()
# 7 登录成功,直接请求页面
print("登录成功,跳转至目标页面")
time.sleep(3.5)
def switch_to_password_mode(self):
"""
切换到密码模式
:return:
"""
if self.browser.find_element_by_id('J_QRCodeLogin').is_displayed():
self.browser.find_element_by_id('J_Quick2Static').click()
def write_username(self, username):
"""
输入账号
:param username:
:return:
"""
try:
username_input_element = self.browser.find_element_by_id('fm-login-id')
except:
username_input_element = self.browser.find_element_by_id('TPL_username_1')
username_input_element.clear()
username_input_element.send_keys(username)
def write_password(self, password):
"""
输入密码
:param password:
:return:
"""
try:
password_input_element = self.browser.find_element_by_id("fm-login-password")
except:
password_input_element = self.browser.find_element_by_id('TPL_password_1')
#
password_input_element.clear()
password_input_element.send_keys(password)
def lock_exist(self):
"""
判断是否存在滑动验证
:return:
"""
return self.is_element_exist('#nc_1_wrapper') and self.browser.find_element_by_id(
'nc_1_wrapper').is_displayed()
def unlock(self):
"""
执行滑动解锁
:return:
"""
if self.is_element_exist("#nocaptcha > div > span > a"):
self.browser.find_element_by_css_selector("#nocaptcha > div > span > a").click()
bar_element = self.browser.find_element_by_id('nc_1_n1z')
ActionChains(self.browser).drag_and_drop_by_offset(bar_element, 258, 0).perform()
if self.is_element_exist("#nocaptcha > div > span > a"):
self.unlock()
time.sleep(0.5)
def submit(self):
"""
提交登录
:return:
"""
try:
self.browser.find_element_by_css_selector("#login-form > div.fm-btn > button").click()
except:
self.browser.find_element_by_id('J_SubmitStatic').click()
time.sleep(0.5)
if self.is_element_exist("#J_Message"):
self.write_password(self.password)
self.submit()
time.sleep(5)
def navigate_to_target_page(self):
pass
# def init_date(self):
# date_offset = 0
# self.today_date = (date.today() + timedelta(days=-date_offset)).strftime("%Y-%m-%d")
# self.yesterday_date = (date.today() + timedelta(days=-date_offset-1)).strftime("%Y-%m-%d")
def init_browser(self):
self.downloadPath = os.getcwd()
CHROME_DRIVER = os.path.abspath(os.path.dirname(os.getcwd())) + os.sep + 'chromedriver' + os.sep
if platform.system() == 'Windows':
CHROME_DRIVER = os.getcwd() + os.sep + 'chromedriver.exe'
if platform.system() == 'Linux':
CHROME_DRIVER = os.getcwd() + os.sep + 'chromedriver'
"""
初始化selenium浏览器
:return:
"""
options = Options()
# options.add_argument("--headless")
# prefs = {"profile.managed_default_content_settings.images": 2}
prefs = {"profile.managed_default_content_settings.images": 2, 'download.default_directory': self.downloadPath}
# 1是加载图片,2是不加载图片
options.add_experimental_option("prefs", prefs)
options.add_argument('--proxy-server=http://127.0.0.1:9000')
options.add_argument('disable-infobars')
options.add_argument('--no-sandbox')
self.browser = webdriver.Chrome(executable_path=CHROME_DRIVER, options=options)
self.browser.implicitly_wait(3)
self.browser.maximize_window()
def is_element_exist(self, selector):
"""
检查是否存在指定元素
:param selector:
:return:
"""
try:
self.browser.find_element_by_css_selector(selector)
return True
except NoSuchElementException:
return False
account = 'youraccount'
# 输入你的账号名
password = 'yourpassword'
# 输入你密码
Login(account,password).start()代码结构如下

最后是演示视频
知乎视频www.zhihu.com如果还有什么不明白的地方,或者出现bug了,欢迎评论留言哦!我看到了会解答的,记得点个喜欢方便以后需要的时候好找到!!!
有些人在安装mimtproxy这个包的时候出问题了,主要是由于python版本的问题,换成3.7及以上的就可以了,安装完后记得给浏览器安装一下CA证书哦















 1795
1795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









