





作者 | 张奎
字符编码相关问题是软件开发过程中的常见问题,本文对字符编码的概念进行了介绍,并针对字符编码的常见问题给出了解释。
字符编码概念
下面以一个例子来引入对字符编码的介绍,汉字“柯”采用不同编码格式编码的结果如下表所示:

DEMO
在我的世界中只有三个字“你,我,他”,我将这三个字组成的集合称之为“捣蛋字符集”,下面来给“捣蛋字符集”编码,编码可以有很多的方式:方法 1:1->‘我’,2->‘你’,3->‘他’方法 2:1->‘他’,2->‘你’,3->‘我’方法 3:1->‘你’,2->‘我’,3->‘他’并且,我给方法 1 取个名字叫“顺序码”,方法 2 叫“逆序码”,方法 3 叫“乱序码”。
区位码
字符编码方式的名字。和上面提到的“顺序码”,“逆序码”,“乱序码”一样,是一种编码方式的名字。
来由:可能是为了方便技术交流。
作用:给编码方式命名。
可见区位码在程序员眼中几乎一无是处,可以忽略不计。
交换码
用于在不同系统之间进行交换的编码。
来由:不同的系统之间可能使用不同的机内码,所以会导致乱码问题,所以定了一种在不同系统之间一样的编码。
作用:不同系统之间编码的统一接口,解决乱码问题。
机内码
计算机内部存储使用的编码。
来由:可能是程序员为了分层,自己系统内部使用的一种编码方式,用来屏蔽掉交换码的变动对系统的影响。
作用:计算机内部用于将编码映射到字符。
为了方便起见,许多系统的机内码直接使用交换码,如 ASCII, utf8, utf16, utf32, Unicode 等,所以这些编码的机内码和交换码一样。(GB2312 的机内码和交换码不一样)
其实,现代常见的系统(Windows, Mac, Linux)都采用 Unicode 作为内码。
需要注意的是“内码”并不是操作系统层面的东西,只是软件层面的东西,比如我自己写个软件,软件中字符的存储采用我自己的编码,因此我自己的软件就有了自己的内码。
Unicode 编码
我们通常说的 Unicode 编码,比如 U+4E00 其实叫做码位/码点(Code Point),这个是一种编码的方式,和 GB2312 的区位码一样。从这个意义上来讲 U+4E00 不是机内码。只是有些机内码使用和码点一样的数字来存储 Unicode 字符。
Unicode 的码点空间从 U+0000 到 U+10FFFF,共约 111 万个码点可用来映射字符。
Unicode 的码点空间被分为 17 个 plane,每个平面有 0xFFFF 个码位。
第一个 Unicode 平面,码位从 U+0000 到 U+FFFF 包含了最常用的字符,该平面被称为“基本多语言平面(BMP = Basic Multilingual Plane)”。其他平面被称为辅助(S=Supplementary)平面。见下图:

GB2312 的编码规则
GB2312 采用区位码的方式进行编码的。96*96 = 共 96 个区,每个区有 96 个位置。
编码规则为:区/位码分别加上 32(0010 0000)产生交换码,用于国际交换,然后高位置1得到机内码,用于存储。


字符编码相关问题
1. 有了交换码,为什么还会有乱码问题?
答:因为各软件/系统所用的交换码不一致。
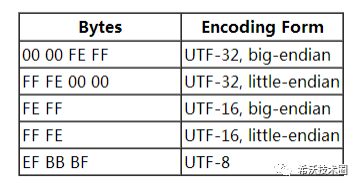
2. Windows 记事本将文本用 Unicode 保存,为什么会在文件开头添加“FFFE”或“FEFF”?答:为了区分 big-endian 和 little-endian 。FEFF 是 Unicode 里的一个合法字符(utf8 编码 EFBBBF),该字符没有宽度,也不会导致换行(ZERO WIDTH NO-BREAK SPACE),而且存储该字符还有一个好处,就是可以区分 big-endian 和 little-endian。因为 FFFE 不是 Unicode 的合法字符。这一做法并非是 Windows 记事本故意的,而是在 Unicode 规范中定义的。
3. 字符集和字符编码是一一对应的么?答:不是。如下图:
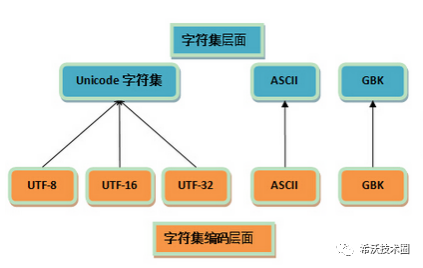
可见,知道了字符集不一定知道编码方式,但知道了编码方式则也就知道了字符集。
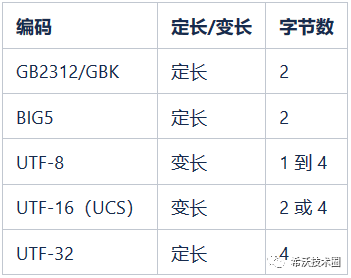
4. utf8, utf16, utf32 有什么异同?相同点:表示的范围相同,都是整个 Unicode 字符集范围。异同点:utf8 : 变长 1-4 字节utf16 : 变长 2 或 4 字节utf32 : 定长 4 字节(gb2312 : 定长 2 字节)
5. UCS-2 是什么?UCS-2 是早期的 Unicode 字符集的一种编码方式,由于当时 Unicode 字符集只有目前的第一平面,故 UCS-2 使用定长 2 字节的长度来编码 Unicode 字符集。其编码的方式和 Unicode 字符的码位一致。
6. utf16 和 UCS-2 的异同?utf16 包含 ucs-2 的字符,只是 utf16 是动态的编码,在 Unicode 第一平面内,其两者编码结果相同。(都是以 Unicode 的码位作为编码)
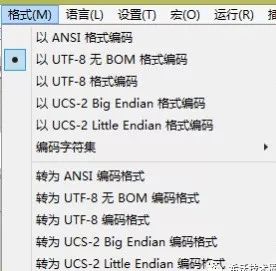
7. 如果 Unicode 只是一个字符集的话,为什么它常常和 utf8 放在一起?比如在记事本的另存里面:
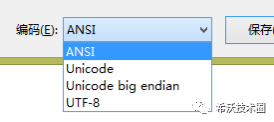
答:这是一种落后的使用方法,和 Unicode 的历史有关。
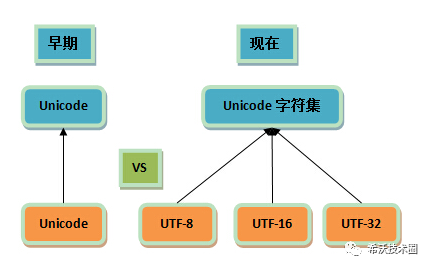
早期的 Unicode 字符集只有一种编码方式 UCS-2,由于只有一种所以就直接称为“Unicode 编码(橙色)”,所以有些程序沿用以前的叫法,把 Unicode 编码和 utf8 放在一起,一般这种情况下的 Unicode 编码指的就是 UTF-16。
其实,记事本中的 Unicode 就是 utf16。
8. 什么是带 BOM 的 UTF-8?BOM = Byte Order Mark , 字节码序标记,即字符 U+FEFF ,是 Unicode 标准定义的一种用于 表示字节码顺序 的字符。是 Unicode 标准专为 UTF16 和 UTF32 设计的(标准也允许 UTF8 使用 BOM),UTF8 由于是单字节的编码方式,所以不存在big-endian和little-endian的问题,所以 UTF8 其实并不需要这个东西,但微软的记事本为了统一或者为了和其他编码方式区分开,会自动在 UTF8 前加上 BOM,这有可能导致在 linux,mac 等系统下乱码。所以网页(要跨平台)一般不要使用带 BOM 的 UTF8。带 BOM 的编码,指的就是文件头带有 U+FEFF 字符。
Notepad++ 里的显示:
总结
本文主要是介绍了一些字符编码理论相关的内容,没有涉及到实际应用,接下来的一篇文章将结合具体开发过程相关的字符编码问题进行详细介绍。
















 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









