







1 简介
- 国标的编码和Unicode 系列的编码在下面的将讲解中将会表现出两个层次。第一层是固定码表,这一层会固定字符与数字的映射关系。在第二层编码方式中,你可以随便制作码表,但是码表的字符排布顺序一定要按照第一层固定码表中的顺序排布,这样就保证了同一系列的编码方式所表示的字符顺序是统一。但是国标的编码表和Unicode的编码表是不一致的,所以这是两个系列的编码方式。
- 在国标的编码中,区位号就是上述思想的体现。根据区号来划分不同种类的符号,再根据位号指定具体的字符位置。但是根据区位号制作出来的码表不能直接用于实践当中,但是它规定了字符之间的顺序。
- 国标码 = 区位码+ 2020H,它实际上就是咱们国家的前辈们设计好的编码方式,但是只用国标码的时候,无法和ASCII码区分开来。例如"啊"的国标码 0x3021 = 00110000 00100001B,它的第一个字节到底是ASCII码还是咱们的国标码?为了兼容ASCII 码,所以必须要把每个字节的首位变为1,所以才有了机器码 = 国标码 + 8080H。
- 区位码制作的基础码表就是第一层码表,国标码的符号排布顺序要和区位码的码表一致,国标码相当于是第二层码表,而机器码是为了兼容ASCII码而存在的,它相当于是第三层码表。
- 在部分的网站当中国标码和机器码有时候是相同的,就是拿着机器码来表示国标码,每个字节的首位给变为1了,但没必要计较这么细致,在内存中存储的就是机器码。所以我在第三章也就不做明显区分,大家知道是怎么回事就好。
2 Unicode系列
- UNICODE就是一个字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)
- ASCII、UNICODE、UTF-8、UTF-16、UTF-32 是编码规则
2.1 Unicode码与UTF-32
- Unicode为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从 0x000000 到 0x10FFFF
- Unicode本身只规定了每个字符的数字编号是多少,并没有规定这个编号如何存储。
- 下面所说的编码方式最终都要通过某种方式映射到Unicode码表中。
-
UTF-32
- 用固定用四个字节表示一个字符
- 可以简单理解为它把Unicode码表直接照搬了过来。
2.2 大端和小端模式
-
大端模式:
- 高位字节放到底地址处,比如0x1234,存储时,高位字节为0x34,一个是低位字节为0x12
-
小端模式
- 高位字节放到高地址处,比如0x1234,存储时,高位字节为0x12,低位字节为0x34
-
为什么要有大小端模式?为什么以每8位作为一个整体?
- 因为很多设备存储方式并不统一。。。
- 一个存储单元往往是8位的,所以要以8位为一个整体。
- 举个例子,在嵌入式领域,传输数据的时候,要传输0x12 34 的时候,是需要1个字节1个字节传输的。但是0x1234占两个字节,是先传高8位还是先传低8位?如果约定好先传高8位,那怎么取得这个高8位呢?这个就跟这个数在内存中的存储模式有关。int a = 0x12 34如果是大端存储模式,则可以通过 a & 0x00FF得到高8位,通过 a & 0x FF00得到低8位。int a = 0x12 34如果是小端存储模式,则可以通过 a & 0xFF00得到高8位,通过 a & 0x 00FF得到低8位。所以大端和小端模式在传输过程中是必须要考虑的事情。
2.3 UTF-8
- 可变长的存储字符
- 对于单字节的符号,字节的第一位设为0,后面的7位为这个符号的Unicode码,因此对于英文字母,UTF-8编码和ASCII码是相同的。
- 对于n字节的符号(n>1),第1个字节的前n位为1,n+1 位为0,其他字节的前2位为10

- 与Unicode 编码表的对应关系
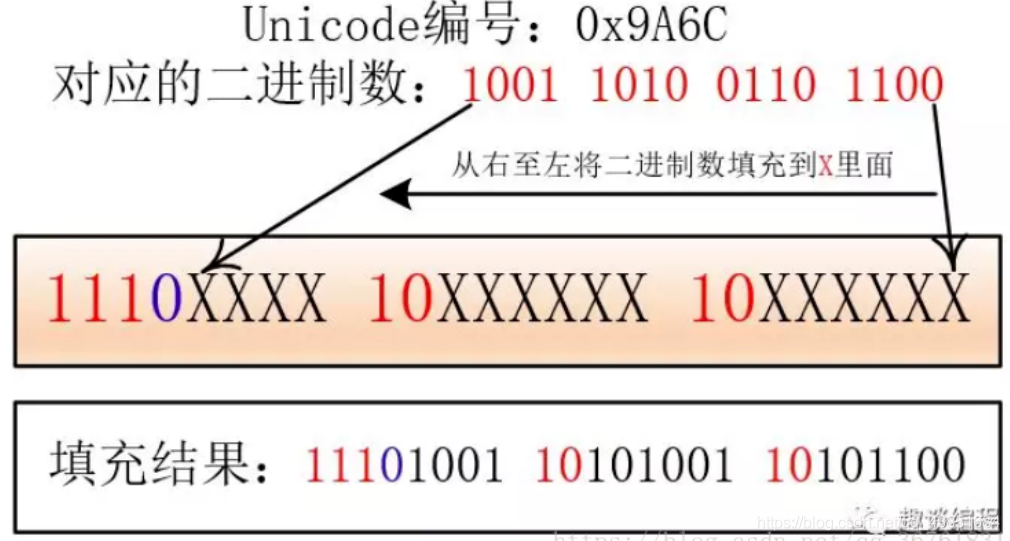
- 例如“马”的Unicode编号是:0x9A6C ,整数编号是39532,对应第三个范围(2048 - 65535),所以在UTF-8编码中需要用三个字节表示"马"
- 将二进制数填入到X中
2.4 UTF-16
-
可变长的编码集
-
从 0x0000 - 0xffff 和 Unicode码表一致
-
Unicode 码表中 0x1 0000 - 0x10 ffff 部分按如下要求表示
- 必须要扩展到4个字节,4个字节表示一个字符
- 需要将Unicode 码表数值减去 0x1 0000,因为前0x10000个字符已经可以用2字节的UTF-16编码表示了。也就是将UNICODE码表的0x1 0000 - 0x10 ffff 部分映射到 0x00 0000 - 0x01 ffff 上。4字节的字符实际上表示的是 0x00 0000 - 0x01 ffff 部分的值。
- 1101 10xx xxxx xxxx 表示字符的高16位
- 1101 11xx xxxx xxxx 表示字符的低16位
- 为了兼容UTF-16,UNICODE码表中 0000 0000 1101 10xx 和 0000 0000 1101 11xx 是不表示任何值的。这保证了4个字节的 UTF-16 的字符可以被准确识别。
-
例如要表示 U+12345 的字符
-
需要先减去 0x1 0000,得到 0x02345,这个是 UTF-16要填充的值
-
0x02345 为 20 位,将高10位和低10位分开,高位为 00 0000 1000 ,低位为 11 0100 0101。
-
将高10位和低10位放置在特定值上
- 高16位:0xD808 + 00 0000 1000B = 0xD8 08
- 低16位:0xDF45 + 11 0100 0101B = 0xDF 45
-
3 GBK系列
- GB2312、GBK、GB18030
- 注意,国标的编码表和UNICODE编码表并不兼容,汉字顺序不一致。
3.1 国标码和机内码
-
国标码和UNICODE码表有着相同的作用,是为了统一某一个值与规定顺序的字符的映射关系
-
国标码为使用两个字节表示一个字符
- 在国标码中,使用区号和位号表示一个字符。
- 但是注意,国标码不是从0x0000开始的,而是从0x2020开始的。而区号和位号,是从0开始的。个人观点:国标码之所以从0x2020开始,是因为一些历史的遗留问题,国标码为了兼容过去的设备而保留这种映射关系至今。
- 所以,( 区号+0x20 ) << 8 + (位号 + 0x20) = 国标码
-
机内码就是计算机在内存中存储的值,例如GBK编码、GB2312编码等
-
以 gb2312 编码举例,双字节字符的首位必为1,将两个字节的首位都变为 0,即可得到国标码
- gb2312 编码的双字节字符首位之所以为1,是为了要兼容ASCII编码。
- ASCII码表的值分布在0x00 - 7F 上
- 对于 GB2312 码表中的 2 个字节的字符而言,全部大于0x80,即两个字节的最高一定为1。所以,当系统检测到一个字节的首位为0的时候,就知道这个字节使用的是ASCII编码,否则这个字节和下一个字节使用的是GBK的双字节编码
3.2 国标码、机内码、区位号转换
- 想要表示一个字符,先查表,找到字符所在的区号和位号
- 区位码先转换成十六进制数表示
- 国标码 = 区位码的十六进制表示 +0x2020
- 机内码 = 国标码 + 8080H =区位码的十六进制表示 + 0xA0A0
以汉字“大”为例,“大”字的区内码为 20 和 83
1、区号为20,位号为83
2、将区位号转换为十六进制表示为1453H
3、1453H+2020H=3473H,得到国标码3473H
4、3473H+8080H=B4F3H,得到机内码为B4F3H
3.3 gb2312编码
-
GB 2312 或 GB 2312-80 是一个简体中文字符集的中国国家标准,全称为《信息交换用汉字编码字符集·基本集》。由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312
-
GBK编码是GB2312编码的扩展,GBK编码完全兼容GB2312编码。
-
GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个
-
分区规则
- 1区:0xA1A0-0xA1FF
- 2区:0xA2A0-0xA2FF
- 3区:0xA3A0-0xA3FF
- ……
- 16区:0xB0A0-0xB0FF
- ……
- 32区:0xC0A0-0xC0FF
- ……
- 94区:0xFEA0-0xFEFF
-
字符分布情况
-
01-09区为特殊符号
-
10-15区没有编码
-
16-55区为一级汉字,按拼音排序,共3755个
-
56-87区为二级汉字,按部首/笔画排序,共3008个
-
88-94区没有编码
-
GB2312只是编码表,在计算机中通常都是用"EUC-CN"表示法,即在每个区位加上0xA0来表示。区和位分别占用一个字节
-

















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









