之前曾经对Logistic Regression进行过深入的讲解,对于SVM的理解其实可以在LR的基础上进行。
优化目标
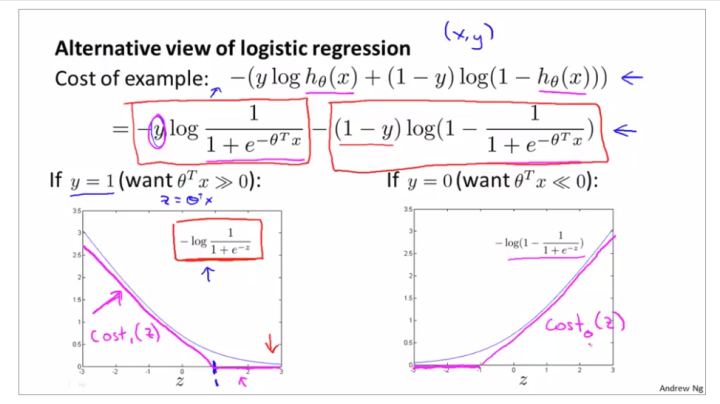
首先不谈SVM的原理,我们先将熟悉的LR的Loss Function进行一下改造。
我们知道,单个样本Logistic Regression的Loss Function为
上面这个Loss在
![]()
(第二项失效)和
![]()
(第一项失效)时,随
![]()
的分布分别长成下图左右两部分蓝线的形式。
SVM所做的就是,把这个Loss做一下变换,将
![]()
和
![]()
两种情况的分布改造成如图紫线的形式,分别以z=1和z=-1为拐点构造一个类似ReLU的分布形式,并分别将其命名为
![]()
和
![]()
。
下面就开始构造SVM的Loss。多样本LR的Loss为
其中第一项就是m个单样本Loss求和,并把-提到括号里边;第二项是正则项,
![]()
是正则化系数。
根据上图,首先将第一项里的两个
![]()
子式分别替换为
![]()
和
![]()
;然后再修改一些表示方式:
1.去掉
![]()
,这不会影响最优化过程,因为仅仅是把Loss在纵轴方向缩放了m倍,不会影响极值的分布;
2.再去掉正则项前面的
![]()
,而在第一项前面乘
![]()
,这同样不会改变极值分布,就相当于将Loss缩放
![]()
(或
![]()
)倍。
最后我们得到了SVM的Loss Function:
这里要注意,与LR输出概率值不同,SVM的输出在
![]()
时直接是1,否则为0。
说了这么多,为什么要把LR的Loss修改成SVM现在的这个样子呢?
我们根据上面的对比图可以知道,LR的优化目标是在
![]()
(
![]()
))的情况下,尽可能的使
![]()
大于0(或者小于0),但实际对大于或者小于的程度没有明确的约束,实际上,在LR的Loss中,只要在标签
![]()
时
![]()
,就认为分类正确(或反过来是负类的情况),此时模型就没有继续优化下去的动力了。而SVM的Loss则给出了明确的约束,如下图:
即,在优化的过程中,构成了这样一种约束:明确的希望达到
![]()
或者
![]()
的目标就可以了,不必再继续优化下去,但前提是一定要达到这个目标。
那么再一次,为什么要这么做?下面就对这个问题做进一步的解释。
最大间隔分类器
从直观上理解,假定SVM的Loss中,C值非常大(比如是10000000),那么此时为了使Loss最小化,优化过程就会倾向于使C后面一项非常趋近于0(这样才能使加号前边这项变小),那么就会到最优化问题
即
同时,根据我们改造的Loss,如果C后面的那一项非常趋近于0,就一定会有
即对于任意
![]()
,都要满足
![]()
(大于1时
![]()
才为0);对任意
![]()
,都要满足
![]()
(小于-1时
![]()
才为0)。而这样,就相当于是同时给优化问题(1)增加了这个约束条件:
s.t.
这个约束条件的作用,同样也就是经过我们修改的SVM的Loss的作用,也是最大间隔分类器的核心所在。下面我们就会一步一步的揭示其原理和意义。
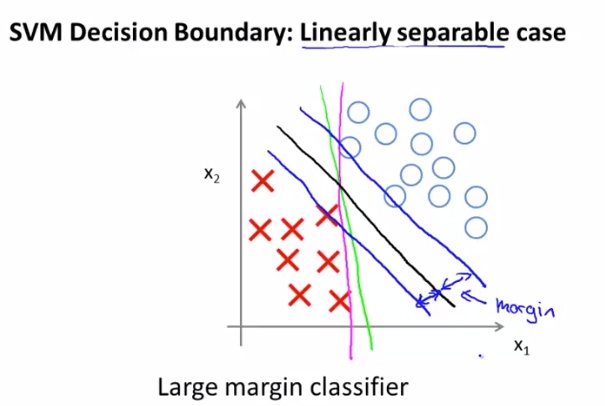
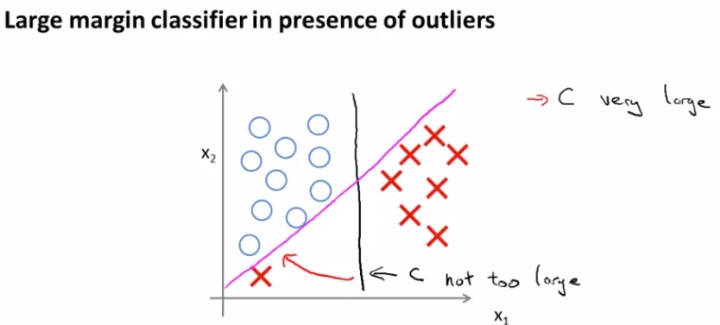
以二维特征为例,求解这个优化问题(1),会得到这样一个有趣的分类结果(假设数据线性可分):得到的分类边界一定是距离正负类样本点最短距离最大的边界(下图黑线)。
当然,这只是一个直观解释,因为C值非常大时,SVM总是会学习到一个与所有的正负样本间距都最大的决策边界,那么如果出现如下图的异常点,为了跟它距离最大,反而会产生过拟合(如粉线的形式,而不是黑线)。或者从另一个角度理解,如果C非常大,那么就相当于LR中
![]()
非常大,即
![]()
非常小,那么就相当于Loss后边的正则项就失效了。因此在实际应用中C会设置成一个不是很大的值。
那么,为什么我们会的到上面的结果呢?即,为什么通过求解上边这个最优化问题,就会得到一个与正负样本最小距离尽可能大的决策边界呢?下面我们就对其进行证明。
首先要对向量内积的概念做一下回顾:
对于两个列向量
![]()
,
![]()
,线性代数的知识告诉我们,他们的内积是
但是在几何意义上,向量
![]()
的内积是这么定义的:
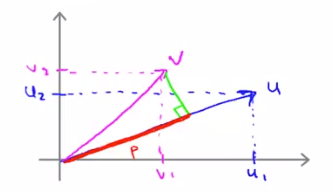
将
![]()
在向量
![]()
的方向上进行投影,如上图所示,得到投影长度为
![]()
,则
![]()
的内积为
其中
![]()
的范数
![]()
,也就是长度为
注意,这里将
![]()
在向量
![]()
的方向上投影或者将
![]()
在向量
![]()
的方向上投影再求内积,得到的结果是没有区别的,最终得到的是同一个实数,有
![]()
。如果
![]()
夹角大于90度,则
![]()
的投影
![]()
的方向就会与
![]()
相反,此时
![]()
就是负值,此时内积也是负的。同时,如果两个向量内积为0,说明两个向量相互垂直。
那么回到最大间隔分类器的Loss最小化的问题上来。为了简化推导过程,需要假设截距
![]()
,此时
![]()
就变成了仅由
![]()
构成的列向量,且此时仍然是二维特征。
则可以对式(1)做以下变换:
可以看到,最终结果里
![]()
就是参数向量的长度,也就是说,在C值很大的时候,求解SVM做的唯一一件事情,就是最小化参数向量
![]()
的长度(范数)(的平方)。
接下来,我们看,在公式(1)的两个约束条件中,
![]()
的实际意义很明确,参数向量和样本的乘积用以预测样本所属类别,这和神经网络中的正向传播完全相同。
但是如果我们从向量内积的几何意义来看
![]()
,如上图,那么它代表着第i个样本向量
![]()
在参数向量
![]()
上的投影
![]()
与
![]()
的范数(长度)之间的乘积,即
那么(1)的约束条件就可以被更换为
我们知道,参数向量
![]()
与决策边界是正交的,这是因为,由LR的定义的可知(SVM与LR在求预测值时形式一致),对于一个二分类问题,如果我们认为输出概率>0.5为正类1,反之为反类0,则当预测结果
![]()
时,代表Sigmoid函数的输出大于0.5,由Sigmoid的形状可知,此时
![]()
;反过来
![]()
则有
![]()
。
那么,如果我们根据
![]()
值在样本平面上画一条直线,落在这条直线上方的都认为是正类,落在这条直线下方的都认为是负类,那么这条直线就是决策边界。既然落在直线上方的都是正类(即
![]()
),那对任意样本
![]()
在这条直线上方就有
![]()
,同理这条直线下方就有
![]()
。那么不考虑边界条件,在这条决策边界直线上,就一定有
![]()
!或者说决策边界的直线方程就是
![]()
,由内积为0的定义可知,既然
![]()
与决策边界上的任意一个样本向量的内积都为0,就说明
![]()
与决策边界上的任意向量都正交,也就是说
![]()
与决策边界是正交的 。
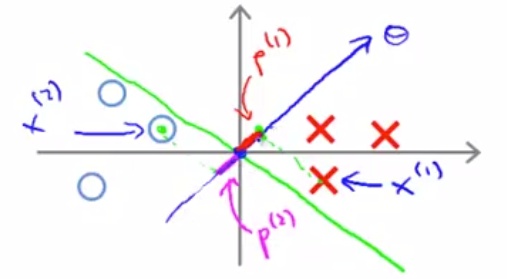
既然
![]()
正交于决策边界,那么样本
![]()
在
![]()
上的投影也就正交于决策边界,如上图所示,这时一个有趣的事实出现了:样本
![]()
在
![]()
上的投影长度
![]()
,也恰好就是
![]()
到决策边界的距离!也就是说,SVM的margin,就是样本点到参数向量
![]()
上的投影长度。
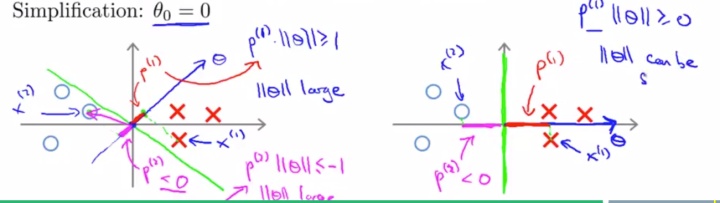
那么上边说的一大堆是怎么决定SVM会选择一个最大间隔分类边界的呢?我们看优化过程中可能会出现的以下左右两个决策边界:
左边的情况,决策边界严重歪斜,距离一些样本非常近,这会导致许多样本
![]()
到
![]()
的投影长度
![]()
非常短。如果
![]()
是正类,在分类边界上方,那么
![]()
就会是一个很小的正值;若x是负类则
![]()
是一个小负值。则为了满足约束(4)大于1的要求以及(5)小于-1,就需要
![]()
的值较大,即需要
![]()
的有很
大的长度,而由式(3),我们的优化目标是最
小化
![]()
的长度,因此直观理解,左边的这个决策边界不是一个好的选择。
而右边的情况,决策边界距离各样本都较远,即
![]()
值相对较高,此时较小的
![]()
的值就可以满足约束条件(4)(5),这样与优化(3)的方向是一致的。
因此直观上来讲,SVM在优化过程中会更倾向于形成右侧的决策边界,实际上梯度的方向就是使决策边界倾向于与样本点距离最大的方向。我们反过来理解也可以,因为在求解(3)时,会尽量选择较小的
![]()
,那么为了满足约束(4)(5),就会要使
![]()
倾向于更大的值,才能满足大于1或小于-1的约束条件,而我们已经说了在
![]()
上的投影长度
![]()
就是样本
![]()
到决策边界的距离。
上述推导我们是假定截距
![]()
为0,实际上
![]()
不为0时,过程和结果是一样的,最大间距分类器同样会朝着使决策边界与样本点距离最大的方向去优化。
下一篇:成旭元:SVM: Kernels和应用技巧






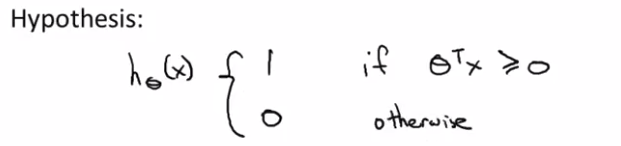

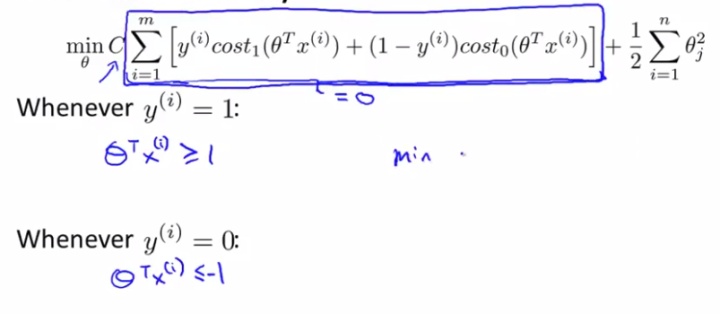















 6531
6531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









