






我认为SVM如此有挑战性的原因是训练SVM是一个复杂的优化问题,需要大量的数学和理论来解释。然而,下面这个训练一个简单数据集的例子能让你理解SVM的核心思想。
我编了一个非常简单的例子来帮助我理解一些概念。这里有一些结果和图表,还有数据文件,因此你也能自己运行算法。
在Excel中,我随意地建了两个点的集合,我这么放是为了能方便地画一条线来区分两个类(类被称为线性分离)。

这里是Excel数据文件
SVM计分函数
训练过的svm有一个分数函数能够为一个新的输入来计算得分。支持向量机是二分类器。如果输出是负数那么就被归为y=-1。如果得分是整的,输入就被分类为y=1。
下面这个等式是为了计算输入向量x的分数。

- 这个函数操作了训练集里面的每个数据点。其中:
x^(i),y^(i)代表了第i个训练样本;
x^(i)是可能是任意纬度的输入向量;
y^(i)是类标签,可能是-1或者1;
a_i是和第i项训练样本有关的系数。
- x是我们尝试分类的输入向量。
- K被称作核函数。
操作了两个向量输出是一个scaler。
有不同可能的核函数选择,我们之后会看这个。
b仅仅是一个scaler值。
支持向量
这个得分函数计算起来很复杂。你必须在每一个单独的训练点上进行每一个操作仅仅为了分类一个输入x——加入你的训练集包含百万个数据点呢?正如被证明的,系数会是0为所有的训练点除了支持向量。
在下面的图表中,你能看到被svm选择的支持向量——三个训练点接近决定边缘。

在WEKA中训练SVM
为了在这个数据集中训练svm,我用了WEKA工具集。
1. 在WEKA explorer中,打开this.csv 数据集。

2. 在Classify tab中,按choose按钮来选择smo(SMO是用来在数据集上训练一个SVM的优化算法)

3. 点击分类命令行来打开对话框编辑命令行。
在对话框中,改变"filterType"类型为“normalization/standardization“。这会让结果更容易翻译。
点击“kernel"特性按钮。会打开另一个对话框来让你明确核函数的特性。将"exponent"特性为2。

Note:(给那些已经熟悉kernel的人) 因为我们的数据集是线性分离的,我们不真的在核内部需要2。尽管为了让weka使用支持向量设置为2是必要的。否则,weka会给你一个简单的线性等式得分函数,不能帮助我们理解svm。
4. 点击“start"来运行训练算法。
在输出的中间,你应该看到下面的等式:
0.0005 * <7 2 > * X]
- 0.0006 * <9 5 > * X]
+ 0.0001 * <4 7 > * X]
+ 2.70351)<7 2>,<9 5>,<4 7>这三个坐标是我们的支持向量,也是我在图里面标出来的点。
2)每个支持向量旁边的系数是这个训练样本的alpha值
3)系数来自于类标签。例如,<9 5>属于y = -1类,<7 2>属于y =1类。在原来的得分函数中,有个部分是 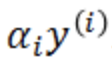
alpha的值总是大于或等于0,所以系数的标记来自于类标签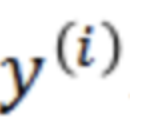 。
。
b = 2.7035
视觉化分数函数
现在我们来看这个等式:
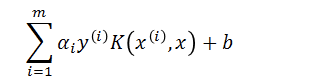
插入我们刚刚得到的值:

x1和x2是输入向量x的值,我们想要计算的分数。
注意到原始合集是过训练集中的每个点的,但我们仅仅包含支持向量部分。所有其他的数据点的Alpha是0,所以那些部分消失了。
你可以在谷歌的搜索框里面输入:
plot z = 0.0005(7x + 2y)^2-0.0006(9x+5y)^2+0.0001(4x+7y)^2+2.7035
将x和y的范围改到0-16你能得到下面的图片:

得分函数形成了三维表面。它和z=0平面交叉形成了一条线;这是我们的决定边界。在决定边界的左边,输入收到了比0更高的数值而且被分配给了y =1。右边的输入收到了少于0的输入被分配给了y=-1类。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









