





什么是WMD?
WMD算法采用了运输指派EMD(Earth Mover's Distance) 的方法来进行词与词之间的相似度计算。

为什么需要WMD算法
当两个短文本的词的位置都对齐时,我们可以直接评估两个短文本的词与词之间的相似度。但是许多时后两个短文本的词的位置并不是完全对齐,我们如何将不同长度的两个短文本中的主要词进行聚类呢?
传统的文本相似度评估方法
- BOW
- TF-IDF
词袋模型(Bag of Words, BOW)
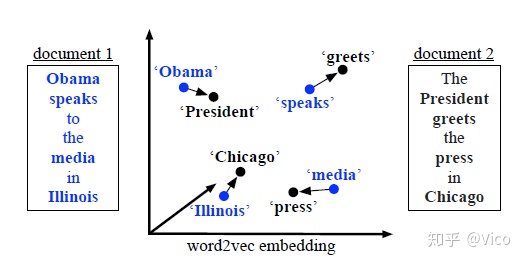
透过短文本中出现的词计算出现的词的频率,可以看到以下两个短文本
1. Obama speaks to the media in Illinois
2. The President greets the press in Chicago.根据上述两句话中出现的所有单词(去除重复的单词), 我们能构建出一个字典(dictionary):
{"Obama": 1, "speaks": 2, "to": 3, "the": 4, "media": 5,"in": 6, "Illinois": 7, "President": 8, "greets": 9, "press": 10, "Chicago": 11}那两个短文本可以依照两个向量,每一个向量表达出现单词的次数,举例如下:
- Obama在第1个短文中出现1次,在向量1中表达为1次
- Obama在第2个短文中并未出现,在向量2中表达为0次
因此整理词频率向量如下:
1.{1,1,1,1,1,1,1,0,0,0,0}
2.[0,0,0,2,0,1,0,1,1,1,1]BoW模型依照词频率产生统计直方图(histogram)
TF-IDF(Term Frequency-Inverse Document Frequency)
- TF(Term Frequency):⽂本中的出现频率
- IDF(Inverse Document Frequency):逆向⽂档频率
TF表达在单一个文本中,出现单词的重要性,当TF值愈高,其单词愈重要,范例如下:
1. 第一个文章中,被我们筛选出两个重要名词,分别为「健康」、「富有」,「健康」在该篇文件中出现 70 次,「富有」出现 30 次
(1) 「健康」的 tf = 70 / (70+30) = 70/100 = 0.7
(2) 「富有」的 tf = 30 / (70+30) = 30/100 = 0.3
2. 第二个文章中,同样筛选出两个名词,分别为「健康」、「富有」,「健康」在该篇文件中出现 40 次,「富有」出现 60 次,
(1) 「健康」的 tf = 40 / (40+60) = 40/100 = 0.4,
(2) 「富有」的 tf = 60 / (40+60) = 60/100 = 0.6,IDF表达在所有文章中,出现单词出现的机会,当IDF越低,其单词越重要,范例如下:
例如有 100 个网页,「健康」出现在 10 个网页当中,而「富有」出现在 100 个网页当中,
(1) 「健康」的 idf = log ( 100/10 ) = log 100 – log 10 = 2 – 1 = 1
(2) 「富有」的 idf = log (100/100) = log 100 – 1og 100 = 2 – 2 = 0。TF-IDF即是结合个别文章、全部文章的影响,保留重要的单词,计算方式如下:
公式为tf(i,j) * idf(i)(例如:i =「健康」一词)以某一特定文件内的高单词频率,乘上该单词在文件总数中的低文件频率,便可以产生 TF-IDF 权重值
TF-IDF 倾向于过滤掉常见的单词,保留重要的单词,如此一来,「富有」便不重要了。Word2Vec(神经网络)文本相似度评估方法
传统的方式即为建立一个词袋(one-hot向量)当单词的数量越多时将换产生高维度的(one-hot向量),将会对电脑的运算造成大量的负担,word2vec将的one-hot向量(模型的输入)转换成低维词向量(模型的中间产物,更具体来说是输入权重矩阵)。
Word2Vec包含了两种词训练模型:CBOW模型和Skip-gram模型
1. CBOW模型: 根据中心词W(t)周围的词来预测中心词
2. Skip-gram模型: 则根据中心词W(t)来预测周围词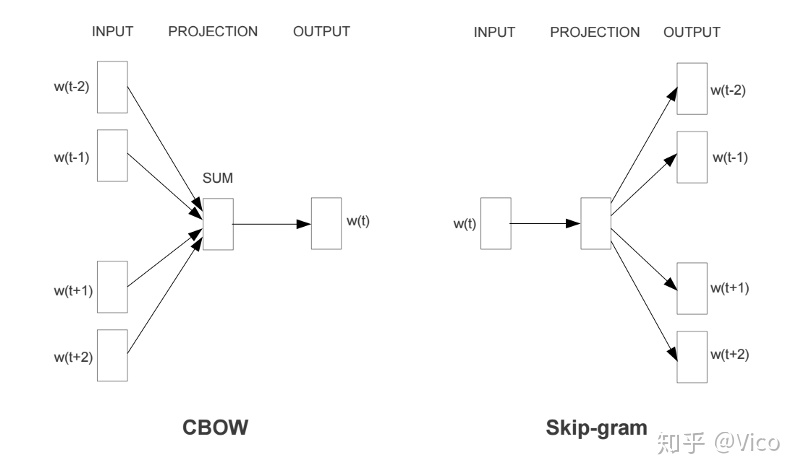
透过Word2Vec降维后聚类,可以找出单词之间的语义相关性。
范例:国王(king)减掉男人(man)加上女人(woman)会变皇后(queen)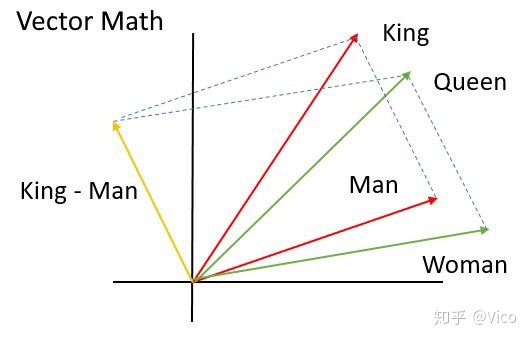
Word2Vec如何延伸出WMD?
如下两个短文本,表达的意思很相似,都是要表达欧巴马在芝加哥发表演说
1. Obama speaks to the media in Illinois
2. The President greets the press in Chicago.如下图所示,我们可以透过WMD算法引入了Word travel cost,计算词(i)、词(j)之间欧式距离如下图:

透过WMD计算后相似的词聚类的结果如下图:
WMD算法的核心问题
WMD核心是将两个不同的文本按照最好的方式词聚类,而如何才是最好将相似词聚类呢?相似词聚类的方式有很多,最好的聚类方式就是两相似词的距离最小,同时这个最小的距离就是这两个相似词的距离。

如上图所示,两个短文本D1, D2那个文本与D0所要表达的意思最相近?可以看到D1对于D0的WMD距离为1.07,小于D2对于D0的WMD距离为1.63,代表D1短文本表达词含义与D0短文本的词含义最相近。

上图的D3短文本,因为与D0短文本字数差异导致WMD计算时会有多重配对的情况发生。
WMD引入的新概念
1. Word travel cost的概念:让Word2Vec加入了单词间的语意也被考虑进计算短文本之间的相似性,Word travel cost公示如下:
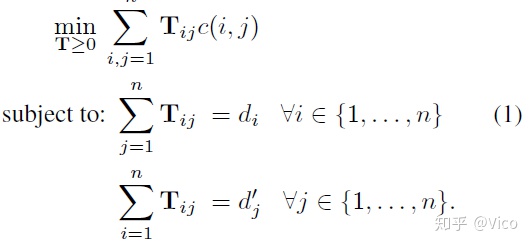
2. Word centroid distance(WCD)的概念:计算出每一篇文章中的质心,来搜索最近距离的可能相似单词,降低模型的计算复杂度,通过降低精度来降低计算复杂度。
3. Relaxed word moving distance(RWMD)的概念:去除限制条件2,放松限制条件,降低模型的计算复杂度,通过降低精度来降低计算复杂度。
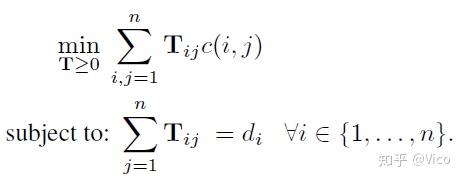
通过去掉条件2,其实是去掉了仓库容量的限制,工厂可以将货物全部运到离其最近的仓库,而不需要考虑仓库的容量。我们在运某个货物时,往离该货物最近的仓库运送,即在转移词语i时,我们只考虑词语i距离最近的词语j进行转移。
4. Prefetch and prune的概念:结合WCD和RWMD降低精度来降低计算复杂度。
总结
我们需要找到两个文本之间的相似程度,可以透过降维和Word travel cost找到单词的相似度,透过单词的相似度可以判别两个文本之间的相似程度。
但是最重要的问题是,当文本的单词数量庞大时,可引入的上述的新概念就是舍弃部份的计算精确程度(WCD和RWMD),以降低运算的时间。
参考文献:
http://proceedings.mlr.press/v37/kusnerb15.pdf
https://www.zhihu.com/question/44832436
Earth Mover's Distance (EMD) - 人工知能に関する断創録















 2497
2497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









