





深度学习数据集
目前ImageNet中总共有14197122张图像,分为21841个类别,数据官网地址为:
http://www.image-net.org/
ImageNet数据集示例如图5所示。
Author:louwill
From:深度学习笔记
很多朋友在学习了神经网络和深度学习之后,早已迫不及待要开始动手实战了。 第一个遇到的问题通常就是数据。 作为个人学习和实验来说,很难获得像工业界那样较高质量的贴近实际应用的大量数据集,这时候一些公开数据集往往就成了大家通往 AI 路上的反复摩擦的对象。 计算机视觉(CV)方向的经典数据集包括MNIST手写数字数据集、Fashion MNIST数据集、CIFAR-10和CIFAR-100数据集、ILSVRC竞赛的ImageNet数据集、用于检测和分割的PASCAL VOC和COCO数据集等。而自然语言处理(NLP)方向的经典数据集包括IMDB电影评论数据集、Wikitext维基百科数据集、Amazon reviews(亚马逊评论)数据集和Sogou news(搜狗新闻)数据等。 本讲就分别对这些经典数据集和使用进行一个概述。CV经典数据集
1.MNIST MNIST(Mixed National Institute of Standards andTechnology database)数据集大家可以说是耳熟能详。可以说是每个入门深度学习的人都会使用MNIST进行实验。作为领域内最早的一个大型数据集,MNIST于1998年由Yann LeCun等人设计构建。MNIST数据集包括60000个示例的训练集以及10000个示例的测试集,每个手写数字的大小均为28*28。在本书的前面一些章节,我们曾多次使用到了MNIST数据集。 MNIST数据集官网地址为http://yann.lecun.com/exdb/mnist/。 MNIST在TensorFlow中可以直接导入使用。在TensorFlow 2.0中使用示例如代码1所示。 代码1 导入MNIST# 导入mnist模块from tensorflow.keras.datasets import mnist# 导入数据(x_train,y_train), (x_test, y_test) = mnist.load_data()# 输出数据维度print(x_train.shape,y_train.shape, x_test.shape, y_test.shape) (60000, 28, 28) (60000,) (10000, 28, 28)(10000,)# 导入相关模块import matplotlib.pyplot as pltimport numpy as np# 指定绘图尺寸plt.figure(figsize=(12,8))# 绘制10个数字fori in range(10): plt.subplot(2,5,i+1) plt.xticks([]) plt.yticks([]) img = x_train[y_train == i][0].reshape(28,28) plt.imshow(img, cmap=plt.cm.binary)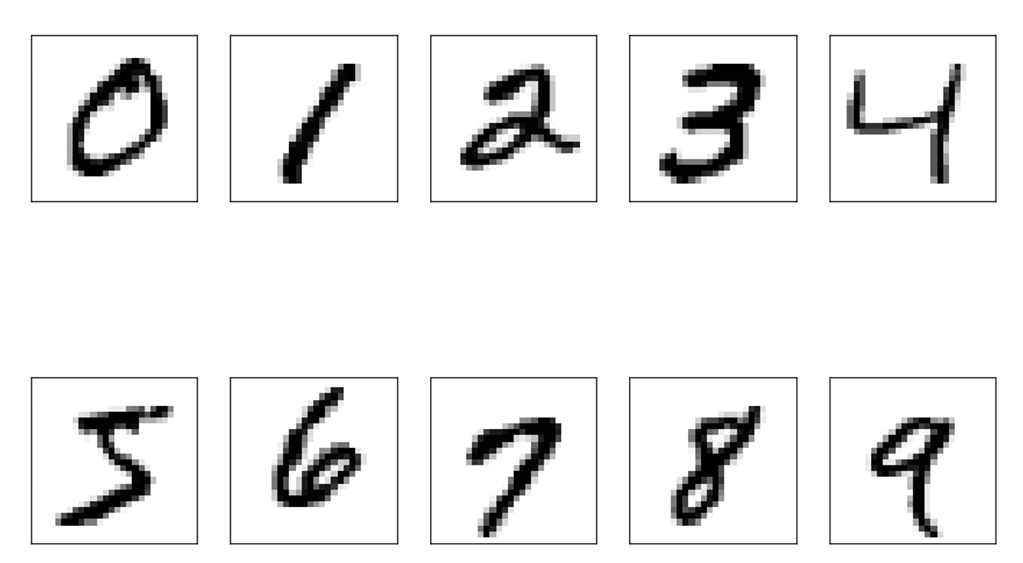
# 导入fashion mnist模块from tensorflow.keras.datasets import fashion_mnist# 导入数据(x_train,y_train), (x_test, y_test) = fashion_mnist.load_data()# 输出数据维度print(x_train.shape,y_train.shape, x_test.shape, y_test.shape) (60000, 28, 28) (60000,) (10000, 28, 28)(10000,)# 绘图尺寸plt.figure(figsize=(12,8))# 绘制10个示例fori in range(10): plt.subplot(2,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) img = x_train[y_train == i][0].reshape(28,28) plt.imshow(x_train[i], cmap=plt.cm.binary)
# 导入cifar10模块from tensorflow.keras.datasets import cifar10# 读取数据(x_train,y_train), (x_test, y_test) = cifar10.load_data()# 输出数据维度print(x_train.shape,y_train.shape, x_test.shape, y_test.shape) (50000,32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)# 指定绘图尺寸plt.figure(figsize=(12,8))# 绘制10个示例fori in range(10): plt.subplot(2,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(x_train[i], cmap=plt.cm.binary)
# 导入cifar100模块from tensorflow.keras.datasets import cifar100# 导入数据(x_train,y_train), (x_test, y_test) = cifar100.load_data()# 输出数据维度print(x_train.shape,y_train.shape, x_test.shape, y_test.shape)(50000,32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)# 指定绘图尺寸plt.figure(figsize=(12,8))# 绘制100个示例fori in range(100): plt.subplot(10,10,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(x_train[i], cmap=plt.cm.binary)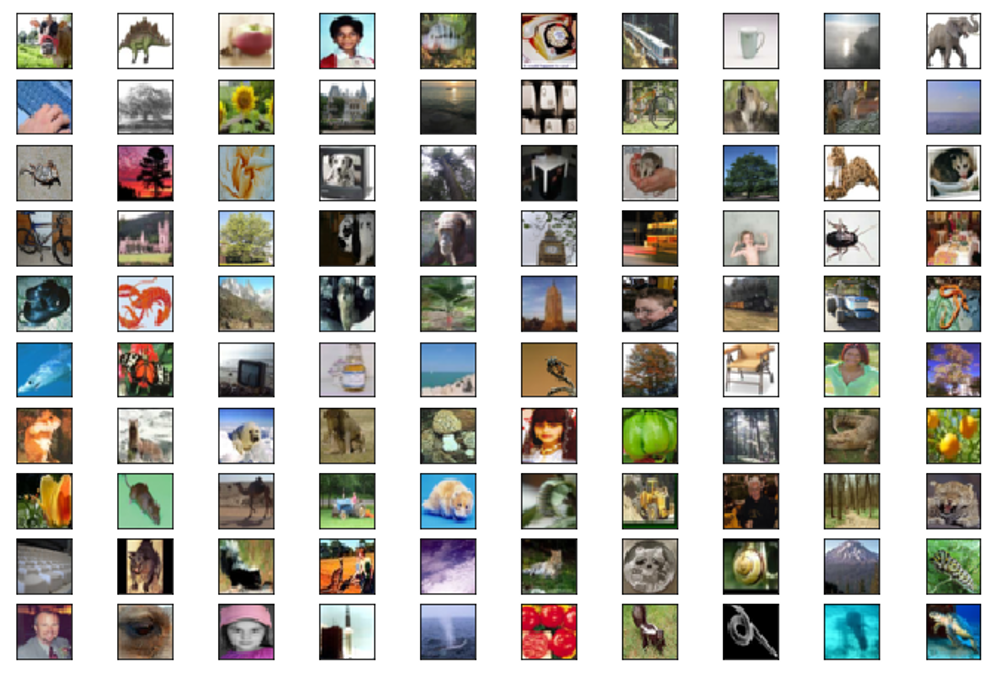
| 年份 | 网络名称 | Top5成绩 | 论文 |
| 2012 | AlexNet | 16.42% | ImageNet Classification with Deep Convolutional Neural Networks |
| 2013 | ZFNet | 13.51% | Visualizing and understanding convolutional networks |
| 2014 | GoogLeNet | 6.67% | Going Deeper with Convolutions |
| VGG | 6.8% | Very deep convolutional networks for large-scale image recognition | |
| 2015 | ResNet | 3.57% | Deep Residual Learning for Image Recognition |
| 2016 | ResNeXt | 3.03% | Aggregated Residual Transformations for Deep Neural Networks |
| 2017 | SENet | 2.25% | Squeeze-and-Excitation Networks |


NLP经典数据集
1.IMDB IMDB本身是一家在线收集各种电影信息的网站,跟国内的豆瓣较为类似,用户可以在上面发表对电影的影评。IMDB数据集是斯坦福整理的一套用于情感分析的IMDB电影评论二分类数据集,包含了25000个训练样本和25000个测试样本,所有影评被标记为正面和负面两种评价。IMDB数据集的一个示例如图9所示。
# 导入imdb模块from tensorflow.keras.datasets import imdb# 导入数据(x_train,y_train), (x_test, y_test) = imdb.load_data()# 输出数据维度print(x_train.shape,y_train.shape, x_test.shape, y_test.shape)Downloadingdata fromhttps://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz17465344/17464789[==============================] - 2s 0us/step(25000,)(25000,) (25000,) (25000,)
往期精彩:
【原创首发】机器学习公式推导与代码实现30讲.pdf
【原创首发】深度学习语义分割理论与实战指南.pdf



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









