






IPFS采用的索引结构是DHT(分布式哈希表),数据结构是MerkleDAG

1内容寻址:使用多重哈希来唯一识别一个数据块的内容
2防篡改:可以方便的检查哈希值来确认数据是否被篡改,如果数据被篡改或损坏,IPFS会检测到
3去重:由于内容相同的数据块哈希是相同的,可以很容去掉重复的数据,节省存储空间
小文件(小于1KB)的文件,IPFS会把数据内容直接和Hash(索引)放在一起上传给IPFS节点,不会再额外的占用一个block的大小,IPFS在储存数据的时候,同一份数据只存储一次,文件是分块(block)存储的,hash相同的block,只会存储一次,也就说,前面1G的内容没有发生改变,其实IPFS并不会为这些数据分配新的空间,只会为最后1K的数据分配一个新的block,再重新上传hash,实际占用的空间是:1G+1K。
即使是不同文件的相同部分也仅仅会存储一份,比如电影资源的影音部分相同,但是只有字幕部分不一样,那么不同的字幕会和音影资源拼接,形成新的文件资源。这样一来就可能会有很多文件的索引指向同一个block,就构成了前面提到的一个数据结构——MerkleDAG。

什么是 Merkle DAG?
Merkle DAG是IPFS系统的核心概念之一,当然Merkle DAG并不是IPFS团队发明的,它来来自于Git数据结构,ipfs团队进行了改造(这一点ipfs团队一直是一个很努力的团队,并不是直接拿来使用,而是在此基础上修改更适合项目的使用)。
Merkle DAG的全称是 Merkle directed acyclic graph(默克有向无环图)。它是在Merkle tree基础上构建的,Merkle tree是由美国计算机学家merkle于1979年申请的专利。Merkle DAG跟Merkle tree很相似,但不完全一样,比如:Merkle DAG不需要进行树的平衡操作,非叶子节点允许包含数据等。
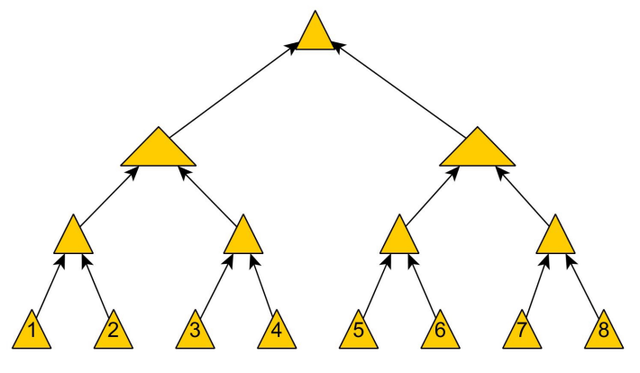
IPFS中以Merkle树为基础的MerkleDAG
正如您将看到的,Merkle树允许通过Merkle校样轻松解决数据完整性以及将数据映射到整个树。
Merkle树和Merkle证明
以1979年获得专利的Ralph Merkle命名,Merkle树基本上是数据结构树,其中每个非叶节点是其各自子节点的散列。叶节点是树中节点的最低层。首先,它可能听起来很难理解,但如果你看一下下面常用的数字,它将变得更容易理解。
Merkle树是分布式版本控制系统(如Git和IPFS)的重要组成部分。它们能够轻松确保和验证P2P格式的计算机之间共享数据的完整性,这使得它们对这些系统非常有用。
更多相关资讯请关注微信公众号:链动精灵科技
举报/反馈














 1058
1058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









