






46年前,两位年轻的IBM研究人员在数据库上提出了一种新的语言,这是一种关系型语言,它奉行一切数据可以被声明性地操作和容易操作的思想。46年的时光里,它经历了许多数据库的诞生和消亡,也经历了许多数据处理方法的诞生和消亡,但直到今天,SQL依然是数据分析人员的必备技能,是关系型数据库的查询语言,每个BI工具都使用各种各样的SQL与数据交互,正如Lukas Eder 所说:“SQL是一种只有它自己的力量才能超越它的神秘手段”。今天,我们就一起来学习如何用这种什么的语言做汇总分析吧!
1.汇总分析
首先,我们进入SQL的常用函数部分,学会了这些常用函数就打开了汇总分析的大门,come on!
count()函数:函数返回符合指定条件的行数。
count(column_name)函数返回指定列的值得数目(null不计入):
SELECT 栗子:
SELECT 
COUNT(*) 函数返回表中的记录数(null计入,计算所有行数):
SELECT COUNT(*)
FROM teacher;
COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目(即重复值不重复计数,例如在student表中,姓名字段中“猴子”是重复值):
SELECT COUNT(DISTINCT 姓名)
FROM student;
sum()函数返回数字列的总和(注意必须是数值类型的列哦):
SELECT SUM(column_name)
FROM table_name
WHERE condition;栗子:
SELECT SUM(成绩)
FROM score;
AVG() 函数返回数字列的平均值(注意必须是数值类型的列哦):
SELECT AVG(column_name)
FROM table_name
WHERE condition;栗子:
SELECT AVG(成绩)
FROM score;
MIN() 函数返回所选列的最小值。
SELECT MIN(column_name)
FROM table_name
WHERE condition;MAX() 函数返回所选列的最大值。
SELECT 栗子:
SELECT 
面试题:
查询课程编号为“0002”的总成绩:
SELECT 
查询选了课程的学生人数:
SELECT 
2.分组
学完了基本的汇总函数,接下来我们来学习如何对数据进行分组。在SQL中我们用group by语句来对数据进行分组:
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组,语法如下:
SELECT 注意:凡是在group by后面出现的字段,必须同时在select后面出现;凡是在select后面出现的、同时未在聚合函数中出现的字段,必须同时出现在group by后面。
栗子:在“student”表中按性别进行分组并计算人数
SELECT 
进一步,我们对出生日期大于1990-01-01的学生按性别分组并计算人数
SELECT 
注意:SQL的运行顺序。
面试题:
查询各科成绩最高和最低的分
SELECT 
查询每门课程被选修的学生人数
SELECT 课程号,COUNT(学号) as 学生人数
FROM score
GROUP BY 课程号;
查询男生、女生人数(见实例1)
3.对分组结果指定条件
GROUP BY主要作用是用来进行分组聚合,也有时候会用来进行排重,与DISTINCT关键字作用类似。此外还常与HAVING关键字一起使用,用来对分完组后的数据进一步的筛选。
在 SELECT 查询中,HAVING 子句必须紧随 GROUP BY 子句,并出现在 ORDER BY 子句(如果有的话,我们在后面会讲到)之前。带有 HAVING 子句的 SELECT 语句的语法如下所示:
SELECT column1,column2 --查询结果
FROM table1,table2 -- 从哪张表中查找数据
WHERE [conditions] -- 查询条件
GROUP BY column1,column2 -- 分组
HAVING [conditions] -- 对分组结果指定条件栗子:按性别分组,筛选出学生人数大于1的学生并计数
SELECT 性别,COUNT(姓名) as 学生人数
FROM student
GROUP BY 性别
HAVING COUNT(姓名)>1;
面试题:
查询平均成绩大于60分学生的学号和平均成绩
SELECT 学号,AVG(成绩) as 平均成绩
FROM score
GROUP BY 学号
HAVING 平均成绩>60;
查询至少选修两门课程的学生学号
SELECT 学号,COUNT(课程号)as 选修课程数
FROM score
GROUP BY 学号
HAVING 选修课程数>=2;
查询同名同姓学生名单并统计同名人数
SELECT 姓名,COUNT( 姓名)as 学生人数
FROM student
GROUP BY 姓名
HAVING 学生人数>=2;
4.用SQL解决业务问题
前面学了这么多,我们是不是该学以致用,用SQL来解决业务问题了呢?那么如何用SQL解决业务问题呢?
- 把业务问题解读成通俗易懂的大白话
- 写出分析思路(按步骤分解)
- 写出对应的SQL子句
下面我们通过一个实际的例子来看一下,如何使用这个思路来解决问题:
假设老板现在要求你计算各科的平均成绩,你就可以按上面步骤,先在草稿纸上写出问题对应的分析思路,第一步要做什么,第二步要做什么……:
- 老板要求的关键词:各科、平均成绩
- 从哪张表——>score
- 各科——>每门课——>按课程号分组;
- 平均成绩——>对成绩求平均值
- 查询结果:课程号,平均成绩
- OK!下面我们按照上面的分析思路结合SQL子句的运行顺序来写出对应的SQL子句
SELECT 课程号 ,AVG(成绩 ) as 平均成绩
FROM score
GROUP BY 课程号;
接下来,老板让你进一步筛选出平均成绩大于等于80分的:
关键词:筛选、平均成绩——>对分组结果指定条件>=80,
SELECT 课程号 ,AVG(成绩 ) as 平均成绩
FROM score
GROUP BY 课程号
HAVING 平均成绩>=80;
这样你就轻松完成了
面试题:计算各科的平均成绩并且平均成绩大于等于80分的。把上面讲的自己操作一遍吧
5.对查询结果排序
在处理数据时我们经常需要对数据进行排序,在SQL中,我们用order by 语句完成这一操作。
ORDER BY 关键字用于对结果集进行排序。
- ORDER BY就是对需要排序的列按升序(ASC)或降序(DESC)排列后显示数据,与Excel的排序类似。
- ORDER BY 关键字默认情况下按升序(ASC)排序记录,默认排序可以不写ASC。
- 降序的情况下必须写DESC,常与TOP关键字一起使用。
照例,我们先上语法:
SELECT 此时,SQL语句的运行顺序为:
(5)SELECT <select list>
(1)FROM [left_table]
(3)WHERE <where_condition>
(2)GROUP BY <group_by_list>
(4)HAVING <having_condition>
(6)ORDER BY <order_by_list> -- order by 子句在select子句之后运行,因为是对查询结果进行排序栗子:例如上面的题,如改为求出各科的平均成绩,并按降序排列,则就需要加上order by 语句
SELECT 课程号 ,AVG(成绩 ) as 平均成绩
FROM score
GROUP BY 课程号
ORDER BY 平均成绩 DESC;
那如果我们要指定多个排序列名呢
栗子:按成绩升序,课程号降序对score表中的数据进行重新排列
SELECT *
FROM score
ORDER BY 成绩 ASC,
课程号 DESC;
/*多个排序列名,按照order by子句中的列名从左到右进行排序的,先排第一个列,如果第一个列
值相同,则在此基础上按第二个列的值进行排序*/
现在新的疑问来了,如果要排序的列里面有空值呢?如何对空值(null)进行排序?
我们来看一颗栗子:
对教师表的教师姓名进行排序
SELECT *
FROM teacher
ORDER BY 教师姓名;
可以看出空值是排在最前面的,也就是说如果我们想看一列里面有多少个空值,这样一排序,其实就可以知道了。
也许你可能还会问上面排序“教师姓名”这一列里 孟扎扎 为什么排在 马化腾 的前面呢?在不指定排序规则的话,是默认按“升序”排列的。孟(meng)和马(ma),a 在 e 的前面,所以 马化腾 应该排在 孟扎扎 的前面吧?
其实如果数据库的字符集编码是utf-8,汉字排序并不是按照字母顺序的;如果数据库的字符集编码是gbk,汉字排序是按照字母顺序的。
这里在告诉大家一个小tip:如果一个数据有几万条甚至十几万条,我们为了提高效率,只想返回其中一部分数据,此时我们可以使用limit语句。
栗子:
SELECT *
FROM score
LIMIT 2;这样就只返回表中的前两条数据啦

因为limit语句也是对查询结果进行处理,所以limit子句也是在select子句之后运行的哦!
面试题:
查询不及格的课程并按课程号从大到小排列
SELECT 课程号,成绩
FROM score
WHERE 成绩<60
ORDER BY 课程号 DESC;
查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列
SELECT 课程号,avg(成绩) as 平均成绩 -- 查询结果 [课程号,平均成绩:汇总函数avg(成绩)]
FROM score -- 从哪张表中查找数据 [成绩表score]
GROUP BY 课程号 -- 分组 [每门课程:按课程号分组]
ORDER BY 平均成绩 ASC,
课程号 DESC; -- 对查询结果排序
检索课程号为“0003”且分数小于90的学生学号,结果按按分数降序排列
SELECT 课程号,成绩
FROM score
WHERE 课程号='0003' and 成绩<90
ORDER BY 成绩 DESC;
统计每门课程的学生选修人数(超过2人的课程才统计),要求输出课程号和选修人数,查询结果按人数降序排序,若人数相同,按课程号升序排序
SELECT 课程号,COUNT(学号) as 选修人数
FROM score
GROUP BY 课程号
HAVING 选修人数>2
ORDER BY 选修人数 DESC,
课程号 ASC;
查询1门及以上不及格课程的同学的学号及不及格课程的平均成绩
select 学号, avg(成绩) as 平均成绩,count(课程号) as 不及格课程数
from score
where 成绩 <60
group by 学号
having count(课程号)>=1;
6.如何看懂报错信息
学了这么多,做了这么多联系,是不是经常在运行时出现报错信息呢?你看懂了吗?现在我们就一起来学习如何看懂报错信息。
[err] 是指错误,表示当前运行的sql语句有错误。
To use near '_______________' atline 4,下划线处则代表语句出错的具体位置。
举颗栗子:
SELECT 课程号,avg(成绩) as 平均成绩
FROM score
GROUP BY 课程号
ORDER BY 平均成绩 ASC
课程号 desc;
那我们就来看一看第5行“课程号 desc;”有什么错误,一检查“平均成绩 ASC”后面少了个逗号,填上去就解决啦。
其实一般出现报错,第一检查标点符号,第二检查子句运行顺序,第三检查是否输入错误的列名等等,还有例如where子句中不能使用汇总函数等等,总之不要着急,按照报错提示定位去找就可以了。
还有一些常见问题:在求最大值时,为什么查询出来的最大值与实际的最大值不符?
这是因为这一列数字看起来是数字,但在设置的时候把这一列的数据类型设置成字符串了,排序或者计算时是按字符串类型来计算的,而非数字类型。这两者的计算规则是不一样的,所以实际操作中一定要记得设置好数据类型哦。或者发现类似问题,检查一下是不是数据类型设置成字符串的,如果是就赶快改过来吧。
好啦,今天所有的内容就到这里啦,虽然写的很累,但是很开心!接下来我们依然来到我们的SQLZOO,完成我们的巩固联系:
1.select from nobel
这部分题目使用的是诺贝尔奖信息表,现在 let's go!
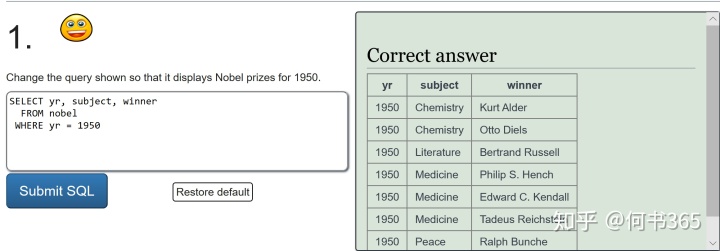
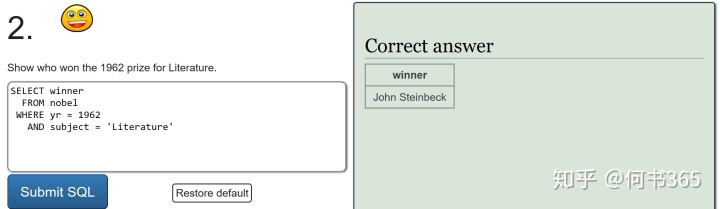
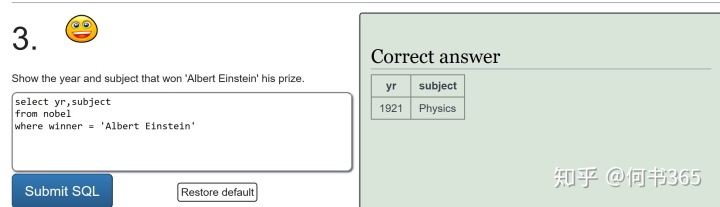
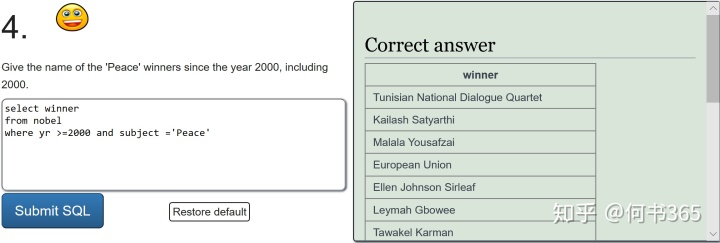
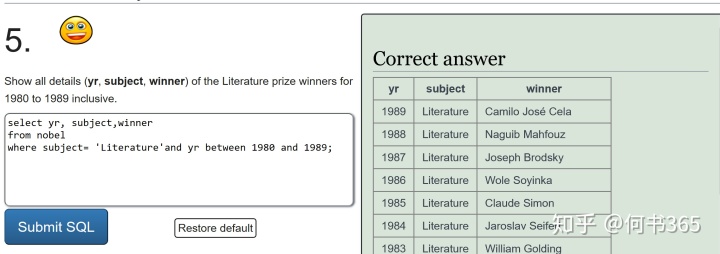
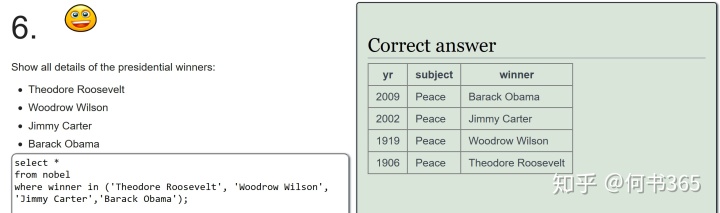

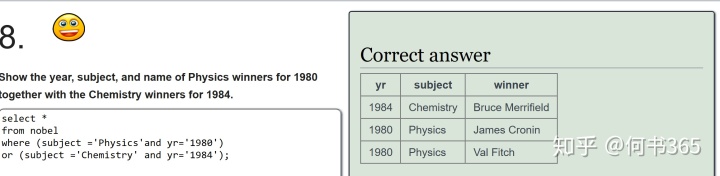

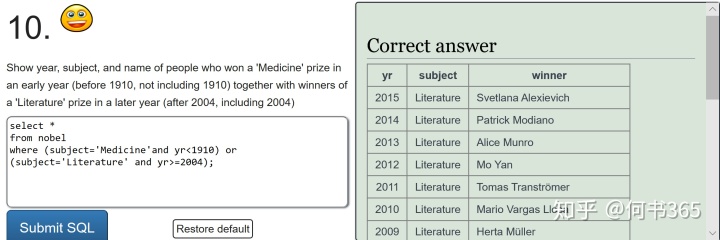
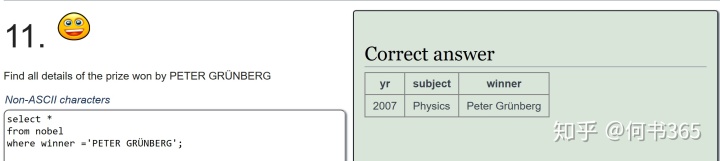

注意:查询得奖者为EUGENE O'NEILL的具体信息,由于名字中含有',查询时输入'EUGENE O'NEILL',此时mysql会报错因为其将名字中的'当成了字符串结尾,因此为了避免这种情况的发生,可将名字中单引号替换为双引号。
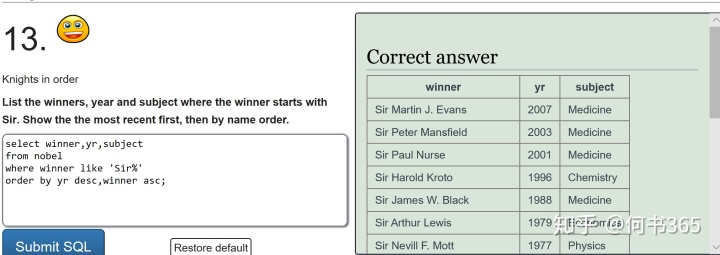
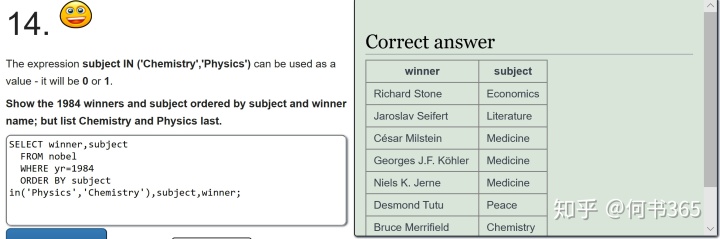
注:subject in ('Physics','Chemistry')返回值(0或者1),会对每一个subject做一个if的判断,有的是1,没有的是0 ,再用order by把这些值排序在下面。
不是这两个科目('Physics','Chemistry')的就是0排在前边,是这两个科目的返回1就排在后边了。 因为化学和物理科目题目要求在后面,所以引入此函数出现0、1,达成题目的要求。
2.sum and count
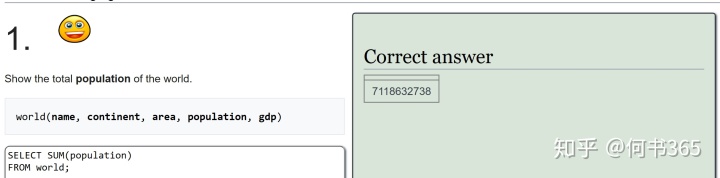

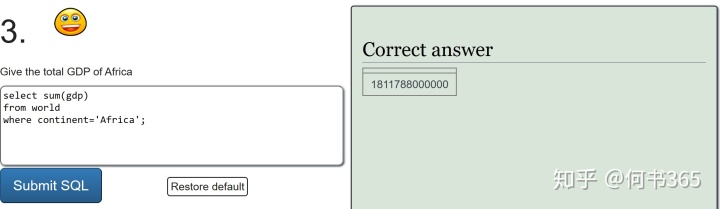

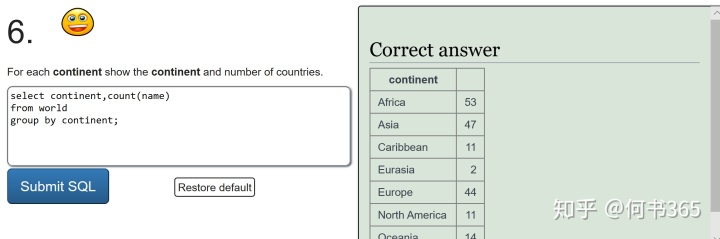
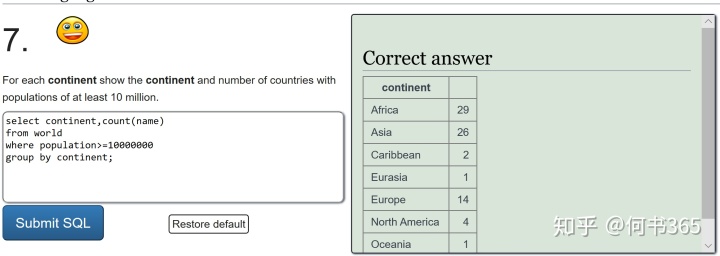

好啦,到这里所有的练习题你已经完成啦,给自己点个赞吧,最后依然还是一张思维导图,让我们一起来复习一下所学习的内容:
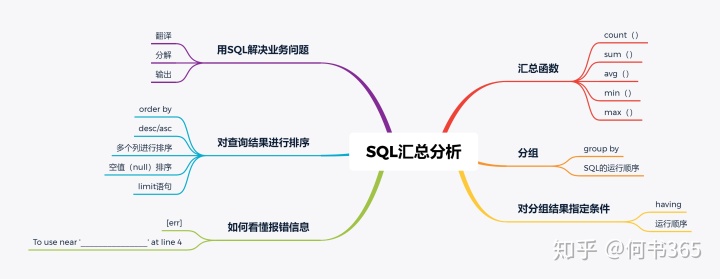
好啦,我们下次见!记住一定要勤加练习和复习哦!you are the best!
往期精彩:
何书365:轻松搞定数据分析之MySQL——零基础入门
何书365:轻松搞定数据分析之MySQL——简单查询















 1206
1206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









