





MongoDB,常用的NoSql数据库,在https://db-engines.com/en/ranking 里被分类为文档型数据库。
本文从以下五个方面来了解MongoDB (和上一篇一样,基础操作请查询官方文档或者菜鸟教程)
- 使用场景
- 存储引擎
- 性能测试
- 索引-B树
- 分片与复制
1.使用场景
一个业务系统的搭建,什么情况下用关系型数据库MySql,又在什么情况下用文档型数据库MongoDB呢?
在回答这个问题之前,先来了解一下MongoDB与关系型数据库的几个显著区别。在MongoDB的自述中,抽取出个人认为重要的两个点:
https://www.mongodb.com/nosql-explained
1. Dynamic Schemas:动态的数据结构
MySql需要先定义好一张表的字段,然后每个字段的值才能被插入;MongoDB不用预先定义字段和数据类型,可以随时动态插入新增的字段。对于一个不断变化发展的业务,数据定义也必然是变化发展的,因此一个灵活可变的数据结构才能较好的应对。比如,社交类软件,每一次的改版,后台的数据结构都有相应的变化。
2. Auto-sharding:自动分片
数据库层面原生的水平分库分表方案,对于海量数据,不用人为的去做分库分表操作。基本原理如下图所示(图片来自MongoDB官网)。
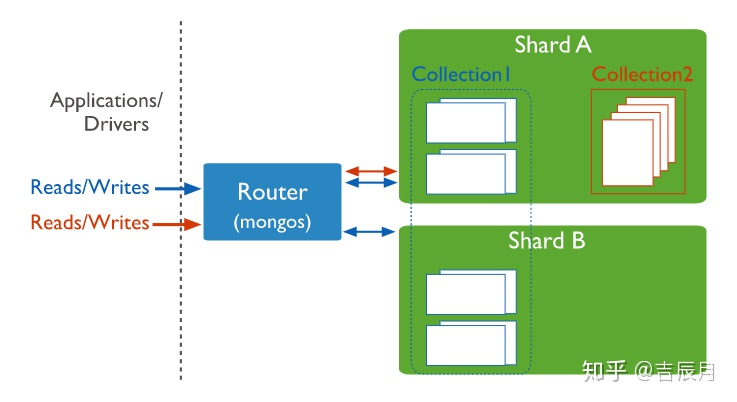
基于以上两个特点,不难看出在什么情况下需要使用MongoDB。
- 遇到经常变化的数据需求。产品今天提需求要支持每个用户设定3个兴趣爱好;明天起床觉得3这个数貌似不是自己的幸运数字啊,还是改为7个兴趣爱好吧;后天老板说我有8个爱好怎么办,产品又默默的改了需求。如果用MySql来存储,相信DBA会默默的准备麻袋和棍棒。所以,一般不经常变的个人数据存在MySql里,例如生日、姓名、籍贯,当然还有性别。而经常变化的数据通过userid关联到MongoDB里存储,比如头像、自我介绍、兴趣爱好,可能、也许、应该还有婚姻状况。
- 海量数据,例如日志。
其实MongoDB的使用场景,在官网的用户案例里已经给出了很多答案:
百度在什么场景用MongoDB?信息,图片分享,百度云,百度地图,社交论坛,用户行为日志。
奇虎呢?基于地理位置信息的移动搜索与结果分发,单点登录信息的缓存(The user’s SSO session is cached in MongoDB for ultra-fast access. MongoDB supports millions of concurrent users, handling 30,000 operations per second and 1.8 billion queries daily. 关于性能在本篇第3部分中阐述),日志分析平台。
还有很多其他公司的应用实例,大家可以访问下面这个链接获取信息。
https://www.mongodb.com/mongodb-scale
最常用的几个场景还是:文档,LBS相关的地理位置信息,日志。这几个场景的共同特点:数据量大,需要经常查询。
2.存储引擎
MongoDB 4.x版本有两个常用的存储引擎(关于存储引擎的概念,请参看上一篇文章 CTO之瞳-数据库-MySql)
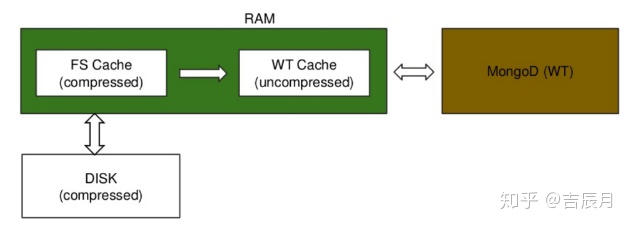
1. WiredTiger:默认引擎,也是社区版(免费版)唯一支持的引擎。
从下图(图片来自MongoDB官网)可以看出,WT引擎在内存中分了两个缓存区域,一个是没做数据压缩的WT Cache,另一个是做了数据压缩的FS Cache,查询的顺序是先去WT Cache,没有命中再去FS Cache,最后再去磁盘;而存进磁盘的数据都是压缩过的(默认压缩)。
2. In-Memory:企业版才支持的引擎
看名字就想象的出,所有的数据是存在内存中的,目的是为了避免硬盘I/O操作,提升性能。缺点也很明显,一旦关机或重启,所有数据都会丢失。看到这里,始终想不明白In-Memory引擎的用途,直到看见了MongoDB的又一特性Replication(复制)才秒懂。
Replication类似于MySql Router机制。试想一下,如果把Master设为In-Memory模式,而数据持久化到Slave上,读写不经过硬盘,性能是何其的强劲;或者把一台slave设为高频数据的专用读取源,比如用户token,这个访问性能也一定是杠杠的。猜想第1节里奇虎案例提到的性能参数 (MongoDB supports millions of concurrent users, handling 30,000 operations per second and 1.8 billion queries daily),就是通过使用In-Memory引擎实现的。
对于In-Memory引擎的使用场景,在第5节-分片与复制里再详述。
3.性能测试
测试环境:
MongoDB 4.2, Windwos社区版, WT engine
IDEA 2019
Windows10
i7-9700F, 8G内存, 东芝固态硬盘
代码访问路径:
https://gitlab.com/ctoeyes/mongodb
Database:test
Collection:WiredTiger
为了和上一篇MySql的测试结果比对,MongoDB的数据表设计如下
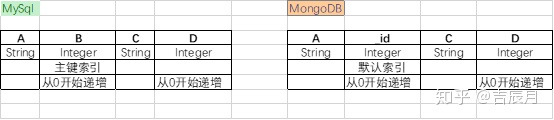
实验一:单线程连续插入5w条数据,数据和MySql测试案例保持一致。
实验二:单线程连续查询1w次,每次以_id列作为查询条件(索引查询)。
实验三:单线程连续查询1w次,每次以D列作为查询条件(非索引查询)。
实验四:查看数据占用空间大小。
实验结果如下:

和上一篇MySql的结果比对如下:
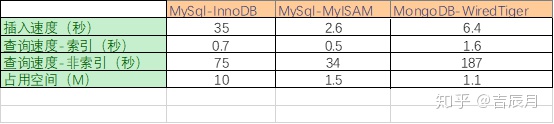
插入速度:MongoDB 4.2支持事务,与同样支持事务处理的MySql-InnoDB比较,性能是较优的。
索引列查询速度:MongoDB劣于MySql的两个引擎,这可能与MongoDB的索引采用B树的数据结构,而MySql索引采用B+树数据结构有关,详细的在下一节“索引-B树”里讨论。
非索引列查询速度,MongoDB也明显慢于MySql,原因是否和MongoDB的数据默认压缩后再存进磁盘有关?查询前要解压缩,有一定耗时。
占用空间:MongoDB占优。
4.索引-B树
MongoDB索引采用的数据结构是B树,以上一篇MySql里相同的数据表为例,画一下在MongoDB里的数据结构。
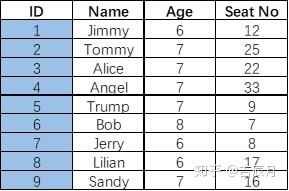
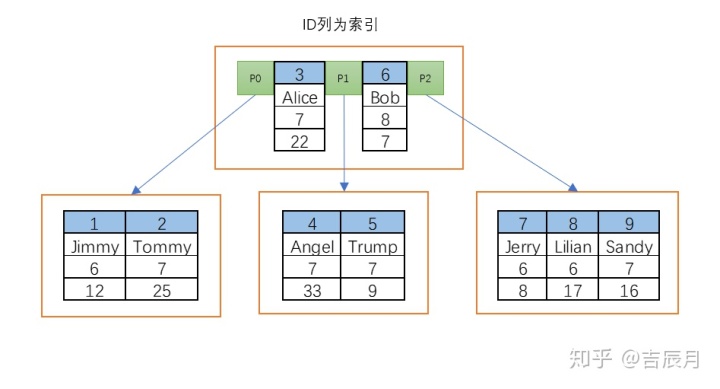
这些数据长成这样:
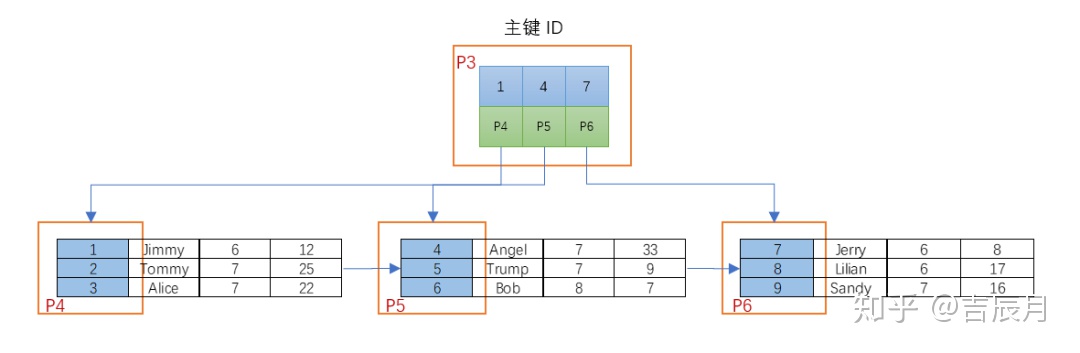
回顾上一篇MySql InnoDB引擎的B+树
可以发现两者有两个很明显的区别
1. B+树只有最下层的叶子节点保存数据,其他节点只保存关键字;而B树每一层节点均保存数据。因此单一数据查询,B+树必须查到最下一层,而B树只有在最坏情况下需要查询到最下层。但第3节的实验结果明明索引查询是MySql的B+树胜出,为什么?个人猜测(未必正确),因为B+树的非叶节点不保存数据,空间占用小而被缓存在内存中,这样访问速度快;B树的非叶节点因为保存数据,空间占用大,有些存在磁盘里,因而访问速度慢。
2. B+树每个相邻的叶子节点有指针连接,而B树没有。因此范围查询,B+树更有优势。
思考:如果把Seat No也设为索引,数据应该长什么样(此时B+树只有叶子节点保存数据的优势就体现出来了)?
5.分片与复制
分片(Sharding)与复制(Replication)是MonoDB的两种扩展方式,前文也提到过。
分片:实质是一种水平方向上的分库分表,主要目的是为了增大容量、提升性能。第1节里的示意图一目了然,不再重复。
复制:类似于MySql Router,主要目的是数据备份、故障热切换、读写分离。而第2节里提到的In-Memory引擎用在复制模式里,也可以帮助提升性能,看下图(图片来自MongoDB官网)。
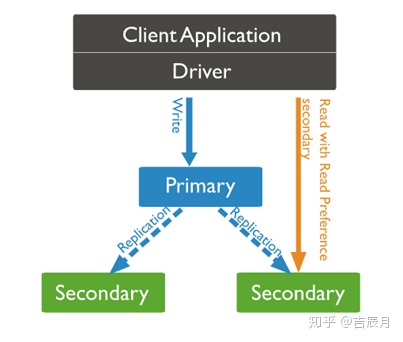
如果把右边的secondary DB设为读操作的默认DB,同时设定它使用In-Memory引擎,那么一些常用的数据读取会极大的提速。当然,这种情况下,需要保证最少两台secondary。为什么呢?试想如果只有一台secondary且是In-Memory模式,此时primary挂了,secondary自动接替为primary,然后它也宕机了,那么primary切换后写入的数据就会全部丢失。这时咋办?赶紧回家卷铺盖跑路吧 ^^
如果把primary设为In-Memory模式,读写都通过primary,而数据持久化到secondary中,那么读写性能都可以得到极大的提升。
了解了分片与复制机制后,想到一个问题,这两种方式能不能放到一起用?也就是既要分表扩容,又要数据备份与故障热切换。仔细看了下MondoDB的官网,其实已经给出了答案,看下图(图片来自MongoDB官网)。
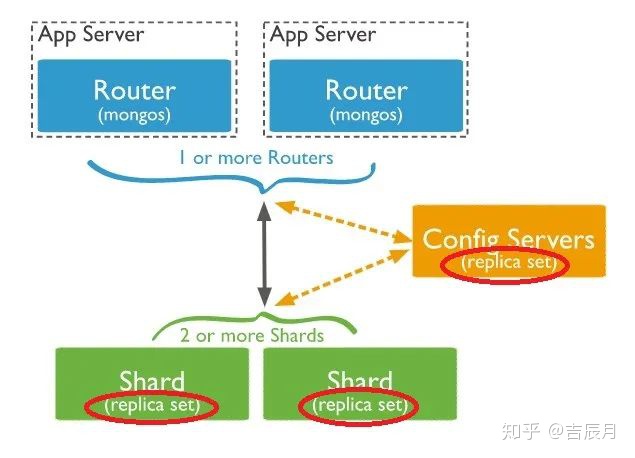
在介绍Sharding架构的图中,已经明确标明了(红色圈圈),每一台Shard DB和Config Server都可以是一组Replica集群。
所以
- 对于小型业务,一台Primary+一台Secondary的Replication方式即可满足业务需求。
- 对于中大型业务,采用Sharding + Replication的矩阵组合基本也可满足业务需求。
MongoDB就聊到这里,依然是九牛一毛,关键是思考;另外,官方文档仔细看,有很多有价值的信息可以挖掘。
下一篇开始说说后端体系,坑中坑,头大,现在觉得B坑的一年之约太乐观了。















 1317
1317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









