





上次我介绍了,利用内部工程enginedump可以直接将一个pdf导出包括每页信息的xml文件,本文介绍另一种方法,可以将pdf导出成xml(这个xml将会包括更为详细的内容)还可以倒出成html等等格式, 话不多说,直接介绍方法:
本次我自己新建了一个工程 pdfextract ,因为在已有的工程里并没有找到调用相关接口进行转换的代码,所以我根据接口,做了如下尝试:
新建的工程如下:
这个工程,主要是用到了 enginepdf这个模块,我在enginepdf中加了个save方法:
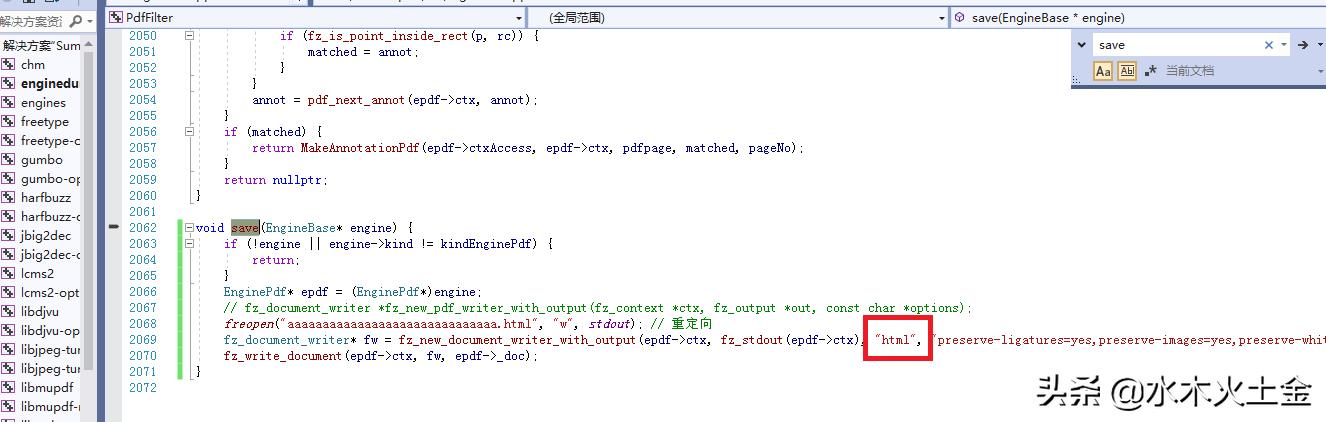
注意,这里可以传入格式,我在这里倒出html, 具体的格式有多种:
if (!fz_strcasecmp(format, "cbz"))
return fz_new_cbz_writer_with_output(ctx, out, options);
#if FZ_ENABLE_PDF
if (!fz_strcasecmp(format, "pdf"))
return fz_new_pdf_writer_with_output(ctx, out, options);
#endif
if (!fz_strcasecmp(format, "pcl"))
return fz_new_pcl_writer_with_output(ctx, out, options);
if (!fz_strcasecmp(format, "pclm"))
return fz_new_pclm_writer_with_output(ctx, out, options);
if (!fz_strcasecmp(format, "ps"))
return fz_new_ps_writer_with_output(ctx, out, options);
if (!fz_strcasecmp(format, "pwg"))
return fz_new_pwg_writer_with_output(ctx, out, options);
if (!fz_strcasecmp(format, "txt") || !fz_strcasecmp(format, "text"))
return fz_new_text_writer_with_output(ctx, "text", out, options);
if (!fz_strcasecmp(format, "html"))
return fz_new_text_writer_with_output(ctx, format, out, options);
if (!fz_strcasecmp(format, "xhtml"))
return fz_new_text_writer_with_output(ctx, format, out, options);
if (!fz_strcasecmp(format, "stext"))
return fz_new_text_writer_with_output(ctx, format, out, options);
咱试了两个,一个html, 一个xml,stext其实就是xml一样,

这里html有一个问题,发现 pdf中的table边框丢失了,这个问题暂时还没有找到是什么原因,也有可能是这个倒出功能不支持,但是因为它是pdf阅读器,所以这个信息肯定有,只是暂时还不知道怎么把这个边框信息导出来,后续有时间再研究,读者朋友如果有知道的,请留言告诉我。这里的xml与之前用第一种方法导出的格式也不一样,这个就更详细了,它把具体每一行,文本的asc编码,字体,颜色等等,都导出来了,具体上图:















 1319
1319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









