





“ 看书犯困,那是梦开始的地方。”
首先来看一个二进制文件一般是怎么构建出来的(拿C++举例)
- 预处理器进行文本替换、宏展开、删除注释这类简单工作,由.cpp文件得到.i文件
- 编译器将文本文件.i翻译成文本文件.s,得到目标平台的汇编语言程序
- 目标平台的汇编器将.s文件汇编成机器语言.o文件(Object文件,也叫目标文件,也叫模块)
- 链接器负责连接用到的各种库文件等资源,最终形成目标平台上可执行的二进制文件
下面具体看看相关原理
编译器
前端
词法分析:把程序分割成一个个 Token 的过程,可以通过构造有限自动机来实现(类似于分词,“我喜欢你”分成“我”、“喜欢”、“你”)
语法分析:把程序的结构识别出来,并形成一棵便于由计算机处理的抽象语法树。可以用递归下降的算法来实现(类似于主谓宾)
语义分析:消除语义模糊,生成一些属性信息,让计算机能够依据这些信息生成目标代码(类似于记录语境上下文)
前端得到抽象语法树,作为中间端的输入,经过多层翻译得到各种中间表示IR,最后翻译出中间代码
抽象语法树 -> 中间表示1 -> 中间表示2 -> ... -> 中间代码
后端
中间代码交给后端进行代码优化(包括机器有关的以及机器无关的优化)得到各种cpu架构的目标汇编代码(汇编语言是机器语言的助记符,各种cpu架构拥有自己的汇编语言,后端要求对各种cpu指令集非常理解)
链接器
链接的过程有点像拼图,多个目标根据各自的全局符号进行匹配拼接
目标文件
目标文件的格式跟可执行文件(PE格式、ELF格式、Math-O格式)的格式基本一致,只是还没有经过链接的过程,其中有些符号或地址还没有被调整,不能被直接执行起来
静态链接库
就是包含了很多目标文件的文件包,这些目标文件之间的引用都已经调整好了
可执行文件存储结构的的分段机制
编译链接后生成的目标文件被拆分成了头部和若干个段
头部描述了整个文件的文件属性,如下图所示ELF格式文件头:
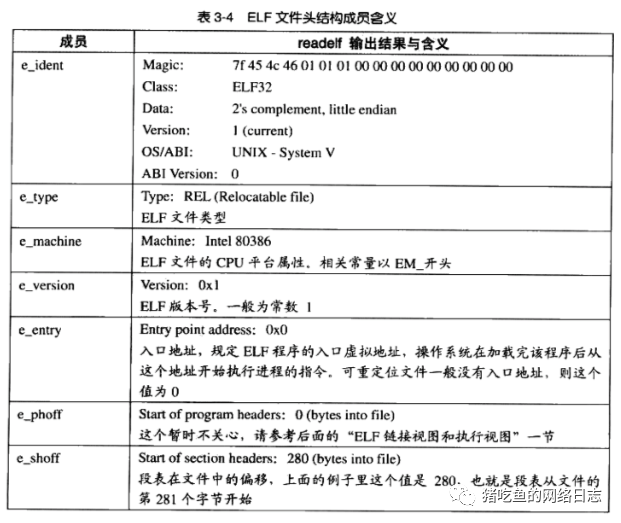
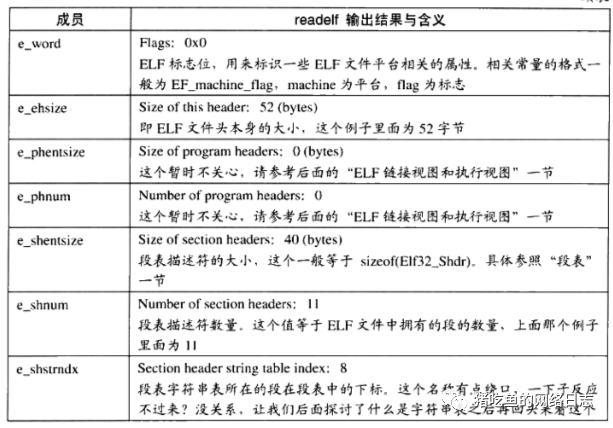
例如下面的例子:
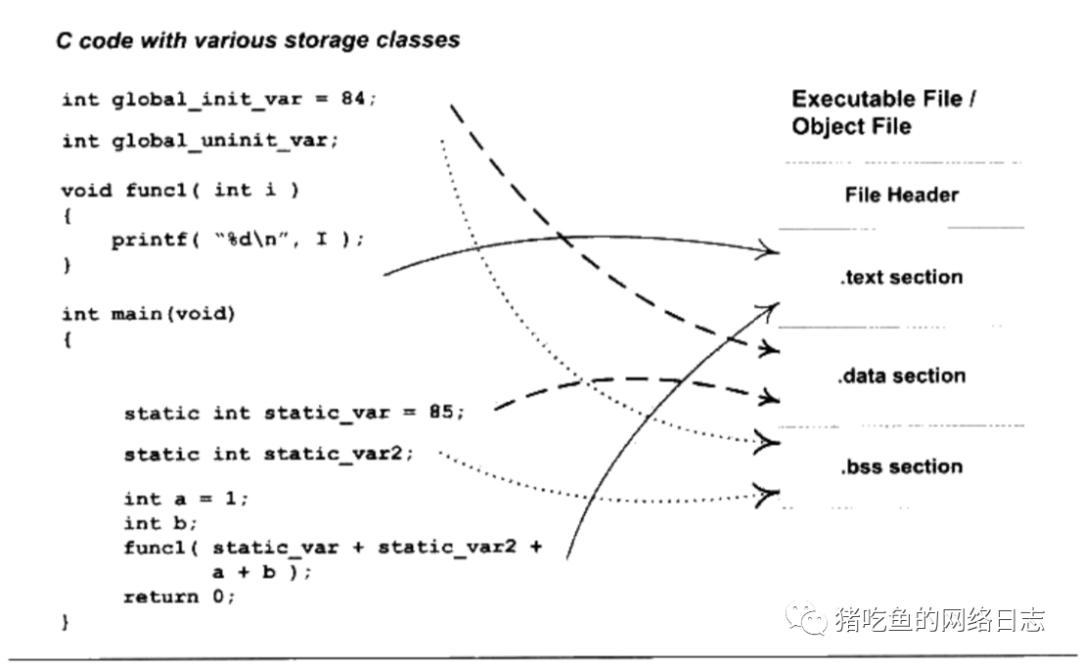
分成了3个段,text(代码段)、data(数据段,存放已经初始化的全局变量以及局部变量)、bss(存放未初始化的全局变量以及局部变量)
段表中段描述符的成员如下:
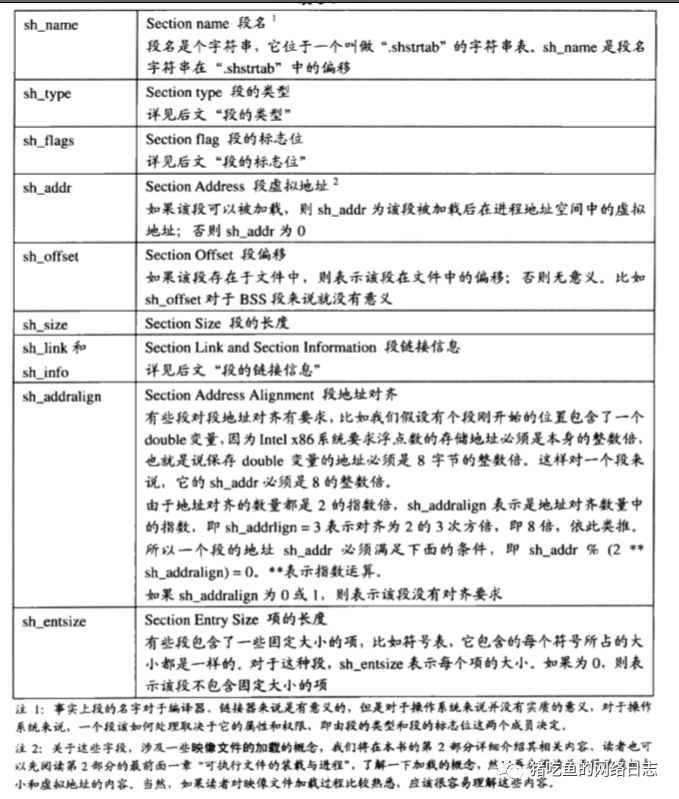
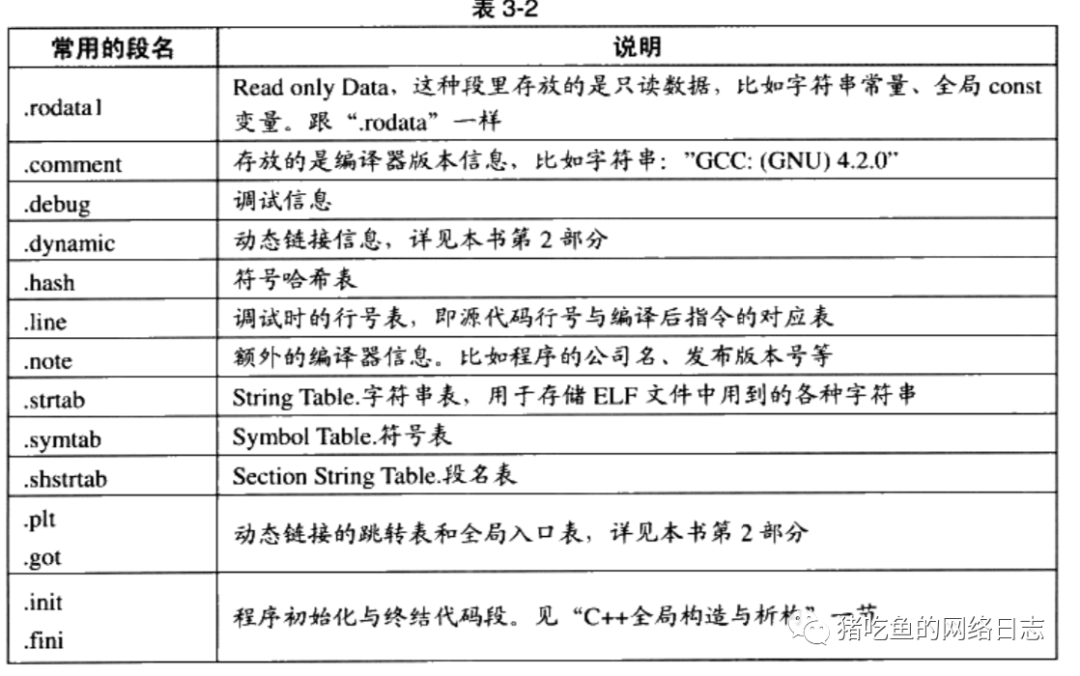
其实一般的程序不止这3个段,还有rodata、comment等等,下图是常见的段
当然我们也可以自己弄一个段放上去,比如一张图片,不会影响程序执行
总的来讲,目标文件会被拆分成两个类型的段:程序指令、程序数据
分段带来的好处:
- 程序指令段和程序数据段被操作系统加载后放入内存,会放到不同的页中,程序指令段所处的页设置成只读,程序数据段所处的内存页设置为可读可写,避免代码被有意无意改写
- 把程序指令和数据归类,对于CPU的缓存命中率会有很大提高
- 很重要的好处:当同一个程序被打开多次,内存中的程序指令段以及部分只读的数据所在的内存页可以被共享,而无需在内存中复制多份,比如系统静态链接库、DDL等
符号、符号表
函数以及变量都是符号,函数名和变量名就是符号名,函数、变量的地址就是符号值
符号表存在于每个目标文件中,记录着当前程序中所有的符号
符号有以下分类:
- 本程序定义的全局函数以及变量
- 本程序中引用的外部的全局符号
- 段名
- 局部函数以及变量
- 行号信息,即指令与行号对应关系
最值得关注的是1、2两种,因为链接过程只关心全局符号之间的粘合,其他几种对其他目标文件都是不可见的
符号表作为一个段存在目标文件中,段名一般是.symtab
符号表中每一个符号具有以下内容:
- 符号值
- 符号大小
- 符号类型(未知类型NOTYPE、数据对象OBJECT、函数FUNC、段SECTION、文件名FILE)
- 符号绑定信息(局部符号、全局符号、弱引用3种)
- 符号所处的段所在的段表数组下标(也可以是ABS(值为0xfff1,表示这个符号包含了一个绝对的值)、COMMON(值为0xfff2,未初始化的全局符号都是这个类型)、UNDEF(值为0,表示本程序未定义,但引用到,符号处于其他目标文件中))
- 符号名
符号修饰
在没有符号修饰之前,任何地方的函数名都不能一样,甚至当前程序的函数名都不能跟引用到的三方库中的函数名一样,因为符号名会冲突
这样的问题是致命的,因为很难做到。所以就有了符号修饰
符号修饰就是将函数签名(函数名以及参数名的集合)转化成符号名的时候按照某个规则进行适当的修饰
C编译器仅仅是在函数名前面加一个_变成符号名,int func(int) -> _func,无疑会有上面说的问题
C++中引入了命名空间,函数只要在不同命名空间下,名称一样也没关系。即使在同一命名空间下,参数不一样,函数也可以一样。所以只要本程序的命名空间和三方库的命名空间不一样,就无需担心函数名的冲突
这都是因为符号修饰之后,他们能够得到不一样的符号名,不会冲突。下面看看GCC编译器的符号修饰规则
- 所有符号都以
_Z开头 - 如果函数位于命名空间或者类中,则接着
N - 然后是命名空间、类的名称、函数的名称(名称前面都有一个字符长度)
- 接着就是参数列表,如果函数位于命名空间或者类中,则紧跟
E,否则没有E,然后是参数的类型。比如int类型就是字母i
比如 int func(int) -> _Z4funci,int C::C2::func(int) -> _ZN1C2C24funcEi
extern "C"的由来
C++编译器会将extern "C"内部的代码当成C代码对待,会按照C编译器的符号修饰规则来生成符号名
有时候C++程序中需要使用某C系统库,比如libc,因为C库中的符号都是按照C编译器的符号修饰规则生成的,如果不在系统头文件中使用extern "C",当有C++程序引用这个头文件,然后使用C++编译后,系统头文件中内容被C++编译器处理,函数名被转换成了跟系统库符号名不一样的符号名,这个程序将找不到系统头文件中声明的函数
所以C系统库如果要实现被C++调用,头文件中必须使用extern "C"
那么问题来了,C系统库如果加了extern "C",不就不能被C调用了吗,这不是水火不容吗?难道只能同时实现两个头文件,一个给C用,一个给C++用吗?这么未免太过麻烦
下面看__cplusplus宏的由来
__cplusplus宏的由来
C++编译器会在编译的时候默认定义__cplusplus宏,所以可以在代码中检查这个宏是否被定义来区分当前编译器是C编译器还是C++编译器
所以头文件中只需加上这样一段
#ifdef __cplusplus
extern "C" {
# endif
// ...
#ifdef __cplusplus
}
# endif
这样,一份头文件就可以兼容C以及C++。几乎所有的系统头文件都使用了这种方式
强引用、弱引用
目标文件A引用目标文件B中的函数,如果A中引用是强引用,则B中必须有此函数的符号,否则编译失败
但如果是弱引用,则编译不会报错,但运行时会报错。但可以通过判断避免报错
__attribute__ ((weakref)) void foo(); // 弱引用
int main () {
if (foo) {
foo()
}
}
重定位表
重定位表中记录者目标文件中所有需要进行重定位的符号信息。
重定位表也位于段中,而且可以有多个重定位表。text段中如果有需要重定位的符号(函数),则对应有一个rel.text段。data段如果有需要重定位的符号(变量),则对应有一个rel.data段
重定位表数组中成员的结构如下:
- 重定位符号所处的虚拟地址相对于段首地址的偏移。比如call test,test是待重定位符号,这里就是call指令所处的text段的虚拟地址相对于段首地址的偏移
- 重定位的类型(决定如何进行地址修正)
- 重定位符号在符号表数组中的下标
静态链接
静态链接就是将多个目标文件拼接成一个可执行文件,分为两步
- 段合并以及虚拟地址(就是线性地址,每个进程都有自以为的线性地址范围)分配。扫描所有目标文件,将他们的相同段(所有符号表所有符号取并集后放入新段)合并(text、data段就是简单的附加,符号段是取并集)且为新段分配虚拟地址(原目标文件中都没有进行虚拟地址分配,所有段首地址都是0)
- 根据重定位表进行符号重定位,就是给所有符号重新填充符号值(各个目标文件的所有符号已经有了值,不过因为各个段的首地址都是0,所以符号值都是可以当作相对段首地址的偏移地址)。比如a.o中test函数的符号,符号值就是函数所处的虚拟地址,其实第一步中为text段分配了虚拟地址后,test函数所处的虚拟地址就已经确定了(就是新段中a.o的text段所处地址加上原来的偏移),这一步就将这个地址填入符号表中完成重定位。比如已初始化的全局变量abc的符号,符号值是abc所处的虚拟地址,abc的值放在了data段,第一步中data段被分配了虚拟地址,abc所处地址也就确定了。
.a静态库
a结尾的静态库文件其实就是多个.o目标文件打包放在了一起
动态链接
静态链接是将多个目标文件链接成一个大的文件,这样有一个问题
比如目标A依赖libc.a,目标B也依赖libc.a,那么A和B都要将libc.a中依赖的目标文件链接起来得到可执行文件A1和B1
那么A1和B1中都含有libc.a中依赖的目标文件,看着就很冗余。假设有一千个这样的目标A或B,那么libc.a中的目标文件会被复制一千次
不仅浪费磁盘空间,更重要的浪费内存空间(一千个程序全部装载入内存,libc.a中的目标文件同样占有一千份空间)
所以就有了动态链接,目的是对常见库的复用,达到节省内存的目的
动态链接相对静态链接 有点像 微服务相对单体应用
万变不离其宗,操作系统类比成Kubernetes,进程类比成微服务
静态链接则是将两个微服务的代码写到一个项目中构成一个微服务,而动态链接则是保留两个微服务,A依赖B只需要在A中配置B的域名,K8s自会根据域名找到B
静态链接把重定位表中符号的重定位工作放在了装载前,而动态链接则是放在装载后,所以动态链接相对更加损耗性能,是一种时间换空间的做法,但是性能损耗并不大,相对于空间的节省,是可以接受的
动态链接其实就是在程序装载后,动态链接器扫描重定位表,将引用到的动态链接库的地址进行填充(填充分页表以及GOT表,完成程序虚拟地址与物理地址的映射关系,且将符号正确指向动态链接库)
GOT表:就是所有需要动态链接的符号以及符号对应的虚拟地址。静态链接时可以直接修改代码段中的符号,但是动态链接不可以,因为装载后代码段是只读的,所以出现了一个处于数据段的可读可写的GOT表,程序装载后,内核会完善GOT表,程序运行时碰到一个动态链接符号时就从GOT表中查找对应虚拟地址,然后去访问
而且如果代码段是可写的,动态链接器可以装载后修改代码段中的符号,那么就做不到多个进程共享,因为符号在每个进程中的虚拟地址都不一样。所以需要GOT段使代码段变得与地址无关
不同的进程动态链接到同一个库时,动态链接库的数据段会被每个进程复制出一个副本。所以当动态链接库中有一个全局变量,两个进程对其的修改各自都不可见,但是一个进程中的两个线程对其的修改就是可见的
可执行文件的装载
可执行文件要得到执行,必须先载入内存,因为CPU是从内存取数据的,不是从磁盘
那么如果一个可执行文件有100M,但是内存只有50M,怎么办,这个程序是不是无法运行?
不是的,现代操作系统都使用了分页实现动态装载的技术,是指需要什么东西就临时将其载入内存
举例,一开始text段中的入口所处位置往后n页大小内容被载入内存,程序就开始执行,执行期间发现调用的某函数没有载入内存(通过虚拟内存查找页表,发现找到的页记录没有值),处理器触发页缺失的硬中断,控制权交给操作系统
操作系统就会将函数所处位置往后n页载入内存,然后接着执行,又发现一个函数没有载入内存,假设此时内存已经满了
操作系统就会根据一个策略(可能是先进先出或其他策略)把这个函数载入到已经被分配的物理地址上,覆盖掉了原来的数据
下面是Linux对ELF文件的装载执行过程
- bash下输入一个命令,比如
ls - bash进程会调用系统调用fork()创建一个新进程
- 新进程调用execve()系统调用进入内核,接着使用ELF装载器(如果想装载EXE文件,可以实现一个EXE装载器,但是没有意义)开始装载
- 检查
ls可执行文件的有效性,比如魔数 - 寻找动态链接的.interp段,设置动态链接器路径
- 根据ELF的header头信息,对其进行映射物理内存
- 初始化进程环境
- 将系统调用的返回地址修改成ELF可执行文件的入口点(虚拟地址)
- 系统调用返回,开始执行ELF文件
大小端字节序
大小端字节序是指CPU对字节集的识别顺序,大端识别就是顺序识别,小端识别则是倒序识别
注意:网络传输的字节流全部都是大端字节序
比如内存中 0x12 0x34 0x56 0x78 这个字节集,在大端CPU看来是uint32数字 0x12345678,而在小端CPU看来是uint32数字 0x78563412
又比如uint16数字 0x1234,大端CPU存入内存后是 0x12 0x34,小端CPU存入内存后确实 0x34 0x12
看下面演示:
package main
import (
"bytes"
"encoding/binary"
"fmt"
"log"
)
func main() {
var num uint32
err := binary.Read(bytes.NewReader([]byte{0x12,0x34,0x56,0x78}), binary.LittleEndian, &num)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%x\n", num) // 78563412
err = binary.Read(bytes.NewReader([]byte{0x12,0x34,0x56,0x78}), binary.BigEndian, &num)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%x\n", num) // 12345678
var a uint16 = 0x1234
var buffer bytes.Buffer
err = binary.Write(&buffer, binary.LittleEndian, a)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%x\n", buffer) // {3412 0 0}
var buffer1 bytes.Buffer
err = binary.Write(&buffer1, binary.BigEndian, a)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%x\n", buffer1) // {1234 0 0}
}
那么该如何判断本机CPU是大端还是小端呢
package main
import (
"fmt"
"unsafe"
)
func main() {
// 方法1
var i int32 = 0x01020304
u := unsafe.Pointer(&i)
pb := (*byte)(u)
b := *pb
fmt.Println("是否是小端:", b == 0x04)
// 方法2
s := int16(0x1234)
b1 := int8(s)
fmt.Println("是否是小端:", 0x34 == b1)
}

戳↙【阅读原文】















 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









