





3.4 多表查询的空值处理:
1.要求返回所有比"ALLEN"提成低的员工∶
SELECT a.ename,a.comm FROM emp a
WHERE a.comm<(SELECT b.comm FROM emp b WHERE b.ename='ALLEN');
###
ENAME ----------TURNER
1 row selected
其中comm列有空值,要先对comm进行处理:coalesce(a.comm,0)
2.
(1)SELECT *FROM dept WHERE deptno NOT IN(SELECT emp.deptno FROM emp WHERE emp.deptno IS NOT NULL);
(2)如果不加WHERE emp.deptno IS NOTNULL会出现什么情况呢?
SELECT COUNT(*)FROM dept WHERE deptno NOT IN(SELECT emp.deptno FROM emp);
如你所见,返回了0行,这是因为在Oracle中如果子查询(SELECT emp.deptno FROM emp)中包含空值,NOT IN(空值)返回为空。(**)
(3)所以必须加入条件"WHERE emp.deptno IS NOTNULL"
SELECT*FROM dept WHERE deptno NOT IN(SELECT emp.deptno FROM emp WHERE emp.deptno IS NOT NULL);
第六章:
1.avg():
SELECT deptno,
AVG(sal)AS 平均值,#=sum(sal)/count(*)
MIN(sal)AS 最小值,
MAX(sal)AS 最大值,
SUM(sal)工资合计,
COUNT(*)总行数,
COUNT(comm)获得提成的人数,
AVG(comm)错误的人均提成算法,
AVG(coalesce(comm,0))正确的人均提成 /*需要把空值转换为0*/
FROM emp
GROUP BY deptno;
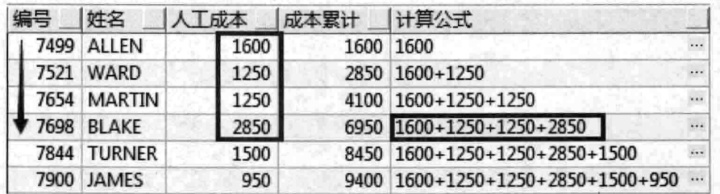
2.公司为了查看用人成本,需要对员工的工资进行累加,以便查看员工人数与工资支出之间的对应关系。

SELECT empno AS 编号,ename AS 姓名,sal AS 人工成本,
SUM(sal) over(ORDER BY empno)AS 成本累计#表示按照empno的顺序对sal进行累加
FROM emp WHERE deptno = 30 ORDER BY empno;(**,结尾排序顺序和累加顺序相同,便于核查)
3.
SELECT empno AS 编号,
ename AS 姓名,sal AS人工成本,
SUM(sal)over(ORDER BY empno)AS 成本累计,
(SELECT listagg(sal,'+')within GROUP(ORDER BY empno)#表示sal字段通过’+’连接,within group ()表示按照()分组,按照empno的顺序
FROM emp b
WHERE b.deptno = 30
AND b.empno <= a.empno)计算公式
FROM emp a WHERE deptno = 30 ORDER BY empno;
3-1 ||可以连接数字:'支出' || rownum AS 项目
4.累积差:
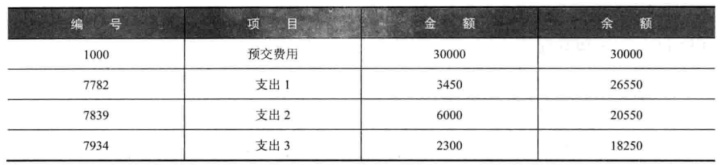
(1)SELECT rownum AS seq#伪列可以作为一列表示出来
,a.*
FROM(SELECT编号,项目,金额 FROM detail ORDER BY 编号)a;

(2)WITH x AS
(SELECT rownum AS seq,a.*
FROM
(SELECT 编号,项目,金额FROM detail ORDER BY编号)a)
SELECT 编号,项目,金额,
sum(CASE WHEN seq= 1 THEN 金额 ELSE-金额 END)over (order by seq)
AS转换后的值#除了收入为正,其余都为负
FROM x;
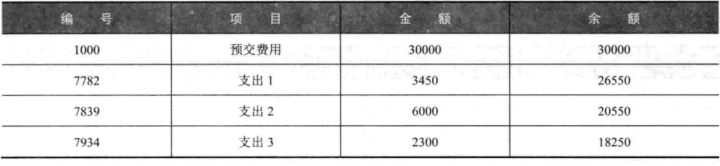
6.4更改累计和的值
- 收入对应的金额为正,支出对应的金额为:-金额
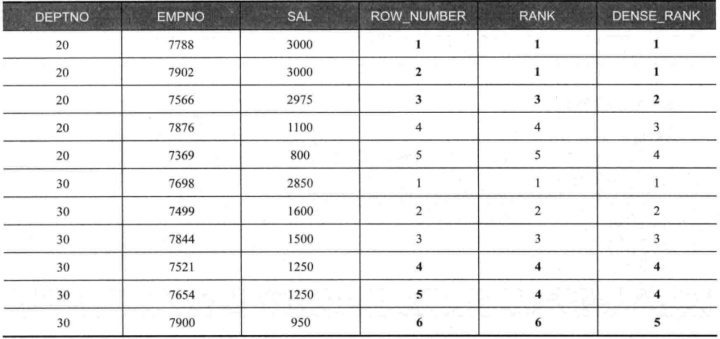
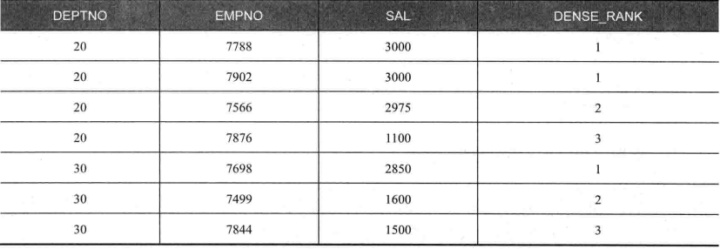
6.5 返回各部门工资排名前三位的员工
SELECT deptno,
empno, sal,
row_number()over(PARTITION BY deptno ORDER BY sal DESC) AS rownumber,
#按部门分组,工资排序
rank() over(PARTITION BY deptno ORDER BY sal DESC)AS rank, #按部门分组,工资排序
dense_rank()over(PARTITION BY deptno ORDER BY sal DESC)AS dense_rank
#按部门分组,工资排序
FROM emp
WHERE deptno =(20,30)ORDER BY 1,3 DESC;
注意粗体标识的部分,当排序列(工资)有重复数据时,会出现以下情况。
ROW NUMBER 仍然会生成序号1、2、3。
DENSE RANK 相同的工资会生成同样的序号,而且其后的序号递增(empno=7566,生成的序号是2)。#密集的排名,当重复时排名相同,后面的排名+1,所以呈现的排名会比较密集
RANK 相同的工资会生成同样的序号,而且其后的序号与 ROW_NUMBER 相同(empno=7566,生成的序号是3)。#rank的排名,重复时排名相同,后面的排名按实际的个数排名
答案代码:
SELECT*
FROM
(SELECT deptno,
empno, sal,
dense_rank() over(PARTITION BY deptno ORDER BY sal DESC) AS dense_rank
FROM emp
WHERE deptno IN(20,30))
WHERE dense_rank<= 3;
6.6 要求查看部门中哪个工资等级的员工最多。
(1)首先计算工资等级对应的员工数量
(2)按部门分组,按数量排序取最大值
SELECT deptno,sal FROM
(SELECT deptno,sal,
dense_rank()over(PARTITION BY deptno ORDER BY 出现次数 DESC)AS 次数排序
FROM
(SELECT sal,deptno,COUNT(*)AS出现次数
FROM emp
GROUP BY deptno,sal) x
)y
WHERE 次数排序 =1;
得出的数据结构是:部门,工资,标签(row_number() over()是来打标签的)
6.7 按各部门分组取出部门中最高的工资
法一:
Select b.*
From
(
Select deptno,max(sal) sal
From emp a
Group by a.deptno
) a
left join emp b on a.deptno=b.deptno and a.sal=b.sal
法二:
Select *
From
(select deptno,sal,dense_rank() over(partition by deptno order by sal desc) rank from emp)
Where rank=1
法三:
SELECT deptno,empno,
MAX(ename) keep(dense_rank FIRST ORDER BY sal) over(PARTITION BY deptno)
AS 工资最低的人,#按deptno分组,
MAX(ename) keep(dense_rank LAST ORDER BY sal) over(PARTITION BY deptno)
aS 工资最高的人,
ename, sal FROM emp WHERE deptno = 10 ORDER BY 1,6 DESC;
例:

对于id=1的结果集进行一下解释
min(mc) keep (DENSE_RANK first ORDER BY sl) over(partition by id):
partition by id:按照id分组
DENSE_RANK first ORDER BY sl:
id等于1取最靠前的(一组数量)的(DENSE_RANK first )为1 111 1 1 222 1
有两行
min(mc):取这两行的最小值
min(mc) keep (DENSE_RANK last ORDER BY sl) over(partition by id):
id等于1的数量最靠后的(一组数量)的(DENSE_RANK first )为1 555 3 1 666 3
6.9 求总和的百分比
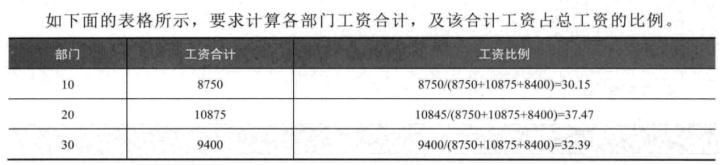
- 首先计算部门的工资
- 对部门的工资进行累加
- 用各部门的工资/累加工资
Select deptno,sum(sal) sal from emp group by deptno;
Select deptno,sal,sum(sal) over(order by deptno) 累计工资 from emp;

总合计的值一样的,不是连加的形式。
Select deptno,sal/累计工资
From
(
Select deptno,sal,sum(sal) over(order by deptno) 累计工资 from
(
Select deptno,sum(sal) sal from emp group by deptno
)
)
第七章
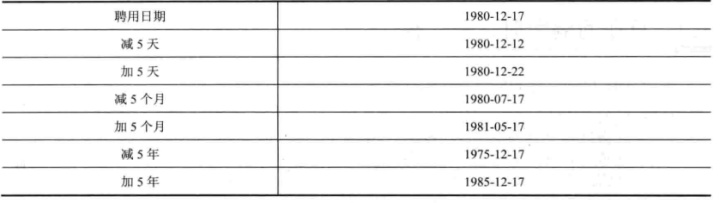
7.1加减日,月,年
hiredate形式为’2020-04-07’
Select hiredate+5 日期加5天,
Hiredate-5 日期减5天,
Add_months(hire_date,5) 加5个月,
Add_months(hiredate,-5) 减5个月,
Add_months(hiredate,5*12) 加5年(一年12个月),
Add_months(hiredate,-5*12) 减5年
From dual;
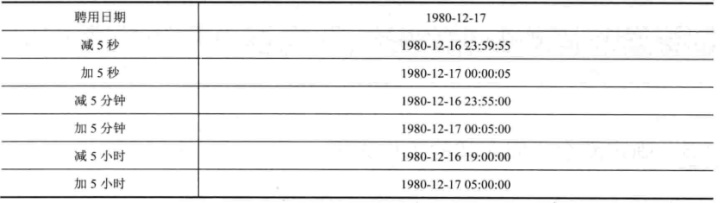
7.2 加减时分秒
Select hiredate +5/24 加5小时
,hiredate-5/24 减5小时
,hiredate +5/24/60 加5分钟
,hiredate-5/24/60 减5分钟
,hiredate+5/24/60/60 加5秒
,hiredate-5/24/60/60 减5秒
From dual;
7.3 间隔天数,时分秒
Select Max(hiredate)-min(hiredate) 间隔天数 from dual;
Select 间隔天数*24 小时
,间隔天数*24*60 分钟
,间隔天数*24*60*60 秒
From dual;

7.4间隔日月年
Select 间隔天数
,month_between(max_hiredate,min_hiredate) 间隔月
,month_between(max_hiredate,min_hiredate)/12 间隔年
From dual;

7.5将字段错位相减
Select hiredate,lead(hiredate) over by (hiredate) #表示按Hiredate的顺序将hiredate提前一行

lag(hiredate) over by (hiredate) #lag是后退一行

9.3定义连续范围之间的开始点与结束点

找出连续工程的时间段,并提取最大时间,最小时间
如何判定连续呢?
工程开始的时间和上一个工程结束的时间相同
Select case when proj_star=proj_end then 0 else 1 end × 要先把proj_end往后挪一行
Select proj_star,proj_end,lag(proj_end),上一工程结束时间
,case when proj_star=上一工程结束时间 then 0 else 1 end 是否连续
From (select proj_star,proj_end,lag(proj_end) over(order by proj_end) 上一工程结束时间 from dual)
#没有proj_star=lag(proj_end) over(order by proj_end)这一格式,case when 相当于条件筛选,此时还没有上一工程结束时间这一字段,所以要先生成上一工程结束这一字段。
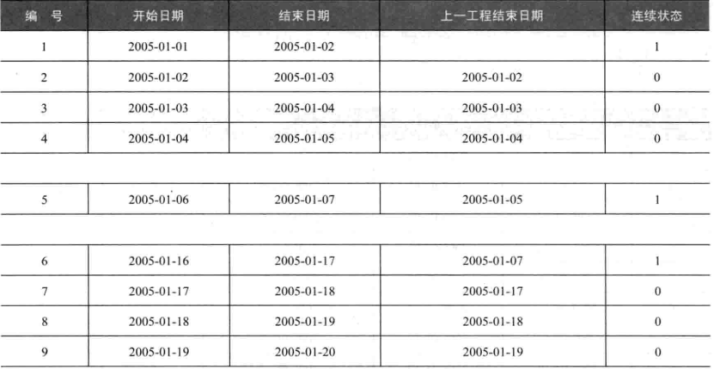
要将连续在做的工程和不连续的工程分开,因为前面对连续的工程标记为0,不连续的工程标记为1,所以可以用累加的形式,将同一连续的工程识别开来:
Select 编号,开始日期,结束日期
,上一工程结束日期,连续状态
,sum(连续状态) over(order by 编号) as 分组依据
From x1;
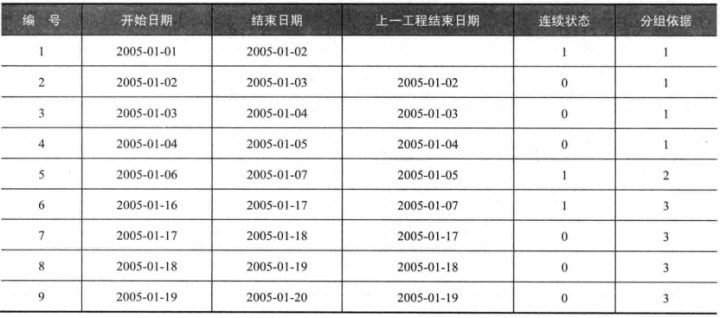
按照分组依据进行分组,得出连续工程的开始日期和结束日期。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









