





Numpy和Pandas是Python进行数据分析的基础库,当初学习Pandas就买了《利用Python进行数据分析》这本书来看,书非常棒,既深入又通俗,而且这本书的原作者就是Pandas库的主要创建者之一。Pandas最常用的两种数据结构是Series和DataFrame,Series是一维数据,类似一维数组,DataFrame是二维数据,类似Excel表格,这两种数据结构都包含数据标签index,在没有设置index时,系统会自动分配(0到N-1)。本文使用Jupyter notebook进行编程测试。
创建/读取Series和DataFrame数据
import 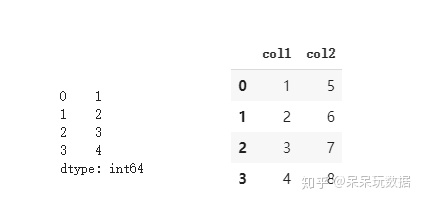
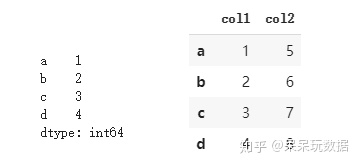

索引对象
Pandas的索引对象用来存储轴标签(包括行索引和列索引),索引对象不可以修改,类似于数组和集合,与集合不同的是索引可以重复。
#输出DataFrame的索引对象
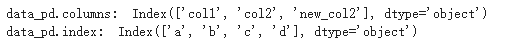
查找数据
#查找列数据
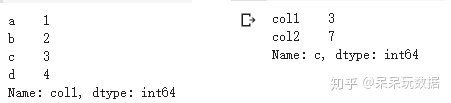
修改数据
#插入新行
将数组和列表赋值给data_frame时,长度必须一致,而将series赋值给data_frame的一列会按照索引重新排列,不匹配的索引则为缺失值NaN。
删除数据
#删除列del,直接在原数据上删除

数据排序
对DataFrame数据排序,既可以按照行列标签排序,也可以按照值进行排序,函数分别是sort_index和sort_values,排序后会生成排完序的新对象,而不是改变原来的数据。
#创建新data

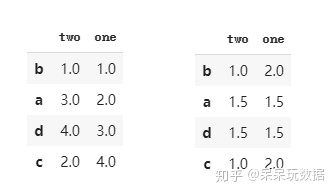
用rank()函数可对dataframe和series进行排名,pandas默认相同值取平均序号,可以传入参数更改。
#排序
数据连接
Pandas连接数据主要是通过merge()函数和concat()函数,merge()函数的连接类似于sql数据库中的join,而concat是在轴向上进行连接
#merge连接
常用统计方法
#统计某一列值的频率
data_pd['columns'].value_counts()













 967
967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









