






大家可能平时都有在百度文库下载文档的经历,费尽心思好不容易在文库找了一份可以用的资料,一看需要用下载券下载,搞的人很烦。
有的人为了节省时间,就任性办理了个文库VIP,再也不用纠结怎么下文档了。如果你是一个百度文库的重度用户,这样做当然没问题了。
但有些学生党、上班族,他们可能只是为了交个作业,做一个产品汇报的PPT等等,对这部分人群再去办理VIP,我觉得没必要,毕竟挣钱也不容易,咱能省就省。
有的人会说,我会选择去某宝买下载券,需要用的时候,用卖家给的账户和密码下载就可以了,这个方法我也用过,不过随着百度文库不断修复漏洞,一些卖家的账户和密码,很快就会失效,这也不是一个长久之计。
当然除了我上面说的这些方法外,还有一些其他的神操作,比如,自己一点点去复杂粘贴、放到手机版的百度文库APP里,再另存为文章、或者用众所周知的“冰点文库”……
在我看来,这些都不是最优的解决方案,我今天就和大家分享一个我自己用Python写的百度文库免下载券的小项目。当然,这个项目主要是用来学习Python爬虫的,如果有任何侵权嫌疑,请联系我删除!

1.优点
不仅可以下载word文档,而且能下载PPT;
可以下载一个完整的文档;
不需要用一些某宝卖家的漏洞网址。
2.准备工作
(1)本次程序主要用到了火狐浏览器的selenium,大家可以在下面网址下载自己火狐浏览器对应的驱动geckodriver。下载地址:https://github.com/mozilla/geckodriver/releases/
下载解压后,将geckodriver.exe安装在Python的安装目录Scripts里面,之后就可以正常使用了。
(2)因为本次项目还涉及到了PPT文档的下载,所以,如果你没安装pptx模块,需要在命令行输入pip3 installpython-pptx提前安装好。
3.PPT文档下载
首先我们随便找一个需要下载券的PPT文档,本文以https://wenku.baidu.com/view/a132c661eef9aef8941ea76e58fafab069dc443d.html?rec_flag=default&sxts=1570202117357为例,打开开发者工具,对文档中图片进行分析,如下图所示:
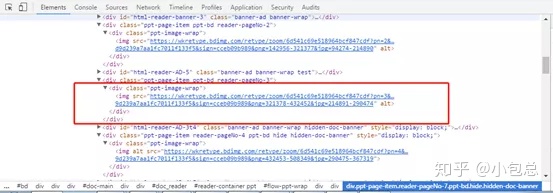
图片保存在标签为div里面,所以写代码时首先需要找到这个标签,然后再把图片的url提取出来,同时,提取url时还要注意,有的属性是“src”,有的是“src”,不然就会出现文档丢失。主要代码如下:
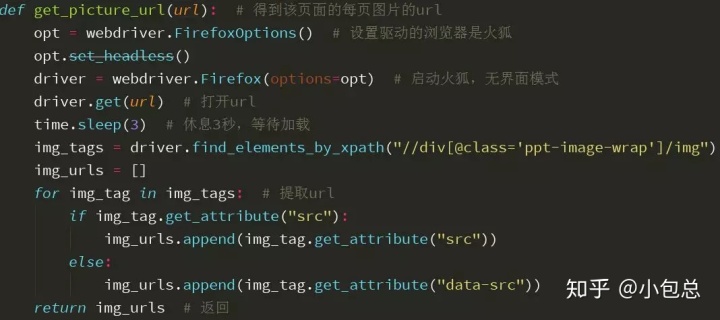
4.下载图片
提取到图片的url后,就可以下载所有的图片,并以pictures命名保存在指定的路径下。代码如下:
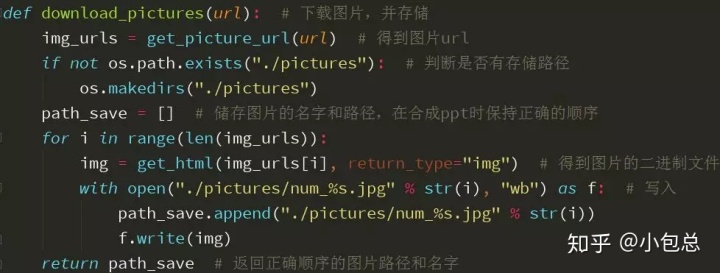
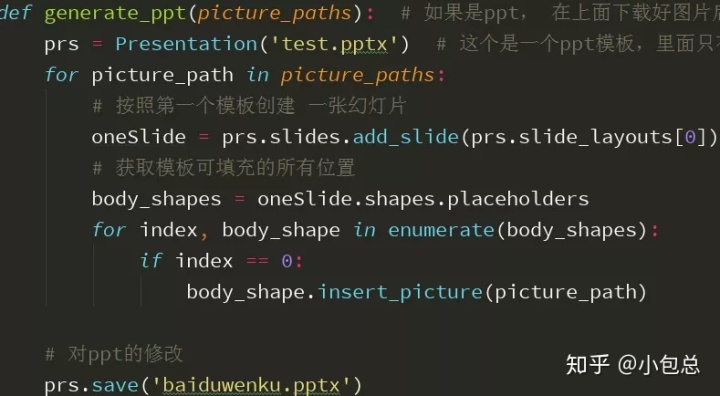
5.组合成PPT
此时需要将上面下载好的图片,利用编写的函数重新合成ppt,这里就要用到刚才提前准备好的生成PPT需要的包,此外,为了保证程序顺利运行,还需要一个ppt模板,这个模板里面只有一个图片的占位,主要是为了让所有图片安装模板来创建成新的幻灯片。代码如下:
6.word文档下载
关于文档下载,本文以https://wenku.baidu.com/view/1b5ee5dbad51f01dc281f13e.html?sxts=1570243034873为例。
主要难点是当页数过多时,会出现“继续阅读”的字样,此时需要selenium模拟人去自动点击,所以,需要提取找到“继续阅读”的按钮;另外,还要获取文档的下载总页码,最后还需要对提取的文本进行分段整理。
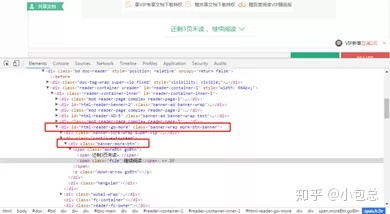
(1)、寻找“继续阅读”位置
本文主要用到了正则表达式,以及js语法。首先要找到继续阅读的位置,如下图所示:
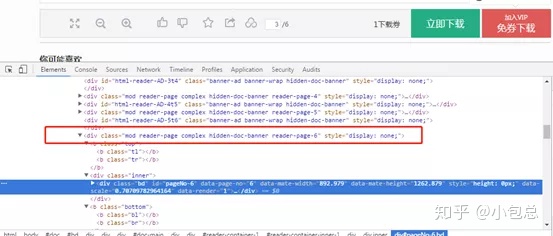
(2)、获取总页数
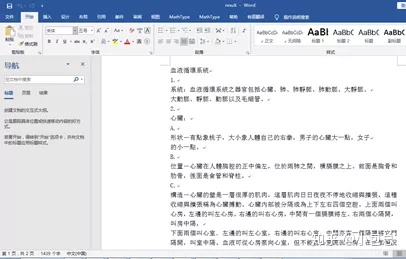
要获取整个文档,首先要找到文档的总页数,在下图中找到保存总页数的标签。
还要分析文档中的文字保存在哪个标签,如下图所示:
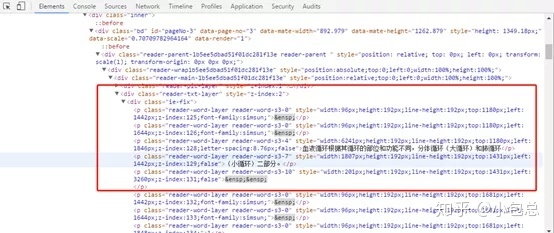
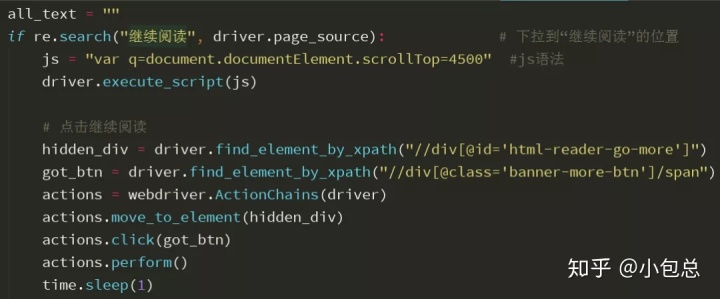
可以看到,文字主要保存在p标签里,我们找到相应的p标签,然后遍历每一页,提取文字。最后,还要设置一个判断变量,因为提取的文字会有很多行,有的是一个段的,有的不是一段的文字,这里需要处理一下,主要代码如下:
7.写入文档
将下载好的文档,以特定的名字写入新的文档,这里没什么难度,代码如下:
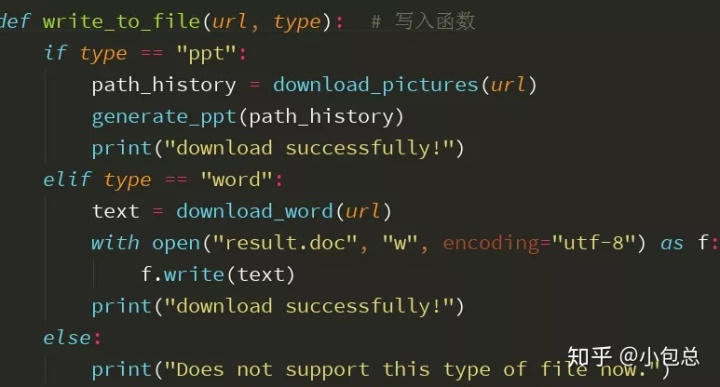
8.结果展示
(1)、PPT下载
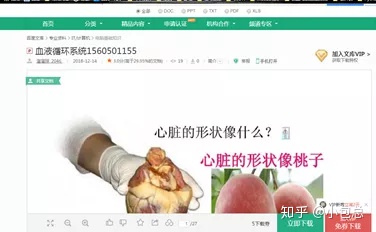
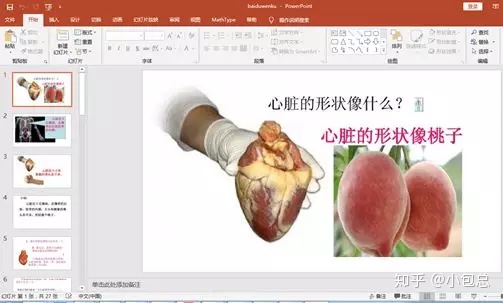
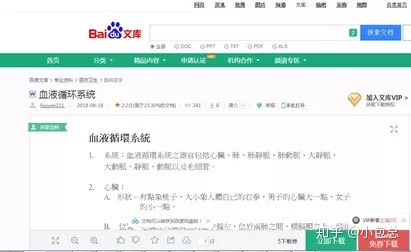
(2)、word下载
总结
今天分享的这个用百度文库免下载券的实战项目,主要用自动化测试工具selenium,可以帮助大家获取一些付费的学习资料,大家不用再去某宝买下载券,或者办VIP了,如果有感兴趣的小伙伴,后台回复「文库」即可获得项目源代码。
最后,再次声明,本次项目主要用来学习Python爬虫,不能拿来商用,本人概不承担所有法律责任,如果有侵权,请联系作者,我马上删除。
















 4407
4407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









