





理论介绍
维基百科
在计算机科学以及数据挖掘领域中,先验算法(Apriori Algorithm)是关联规则学习的经典算法之一。先验算法的设计目的是为了处理包含交易信息内容的数据库(例如,顾客购买的商品清单,或者网页常访清单。)而其他的算法则是设计用来寻找无交易信息(如Winepi算法和Minepi算法)或无时间标记(如DNA测序)的数据之间的联系规则。
先验算法采用广度优先搜索算法进行搜索并采用树结构来对候选项目集进行高效计数。它通过长度为k−1" role="presentation" style="font-size: 14px; display: inline; line-height: normal; word-spacing: normal; overflow-wrap: normal; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border-width: 0px; border-style: initial; border-color: initial;">k−1k−1的候选项目集来产生长度为 k 的候选项目集,然后从中删除包含不常见子模式的候选项。根据向下封闭性引理,该候选项目集包含所有长度为 k 的频繁项目集。之后,就可以通过扫描交易数据库来决定候选项目集中的频繁项目集。
数据挖掘十大算法
Apriori 算法是一种最有影响力的挖掘布尔关联规则的频繁项集算法,它是由Rakesh Agrawal 和RamakrishnanSkrikant 提出的。它使用一种称作逐层搜索的迭代方法,k- 项集用于探索(k+1)- 项集。首先,找出频繁 1- 项集的集合。该集合记作L1。L1 用于找频繁2- 项集的集合 L2,而L2 用于找L3,如此下去,直到不能找到 k- 项集。每找一个 Lk 需要一次数据库扫描。为提高频繁项集逐层产生的效率,一种称作Apriori 性质用于压缩搜索空间。其约束条件:一是频繁项集的所有非空子集都必须也是频繁的,二是非频繁项集的所有父集都是非频繁的。
2 基本概念
关联分析
关联分析是一种在大规模数据集中寻找相互关系的任务。 这些关系可以有两种形式:
频繁项集(frequent item sets): 经常出现在一块的物品的集合。
关联规则(associational rules): 暗示两种物品之间可能存在很强的关系。
相关术语
关联分析(关联规则学习): 下面是用一个 杂货店简单交易清单的例子来说明这两个概念,如下表所示:
| 交易号码 | 商品 |
|---|---|
| 0 | 豆奶,莴苣 |
| 1 | 莴苣,尿布,葡萄酒,甜菜 |
| 2 | 豆奶,尿布,葡萄酒,橙汁 |
| 3 | 莴苣,豆奶,尿布,葡萄酒 |
| 4 | 莴苣,豆奶,尿布,橙汁 |
频繁项集: {葡萄酒, 尿布, 豆奶} 就是一个频繁项集的例子。
关联规则: 尿布 -> 葡萄酒 就是一个关联规则。这意味着如果顾客买了尿布,那么他很可能会买葡萄酒。
支持度: 数据集中包含该项集的记录所占的比例。例如上图中,{豆奶} 的支持度为 4/5。{豆奶, 尿布} 的支持度为 3/5。
可信度: 针对一条诸如 {尿布} -> {葡萄酒} 这样具体的关联规则来定义的。这条规则的 可信度 被定义为 支持度({尿布, 葡萄酒})/支持度({尿布}),支持度({尿布, 葡萄酒}) = 3/5,支持度({尿布}) = 4/5,所以 {尿布} -> {葡萄酒} 的可信度 = 3/5 / 4/5 = 3/4 = 0.75。
支持度 和 可信度 是用来量化 关联分析 是否成功的一个方法。 假设想找到支持度大于 0.8 的所有项集,应该如何去做呢? 一个办法是生成一个物品所有可能组合的清单,然后对每一种组合统计它出现的频繁程度,但是当物品成千上万时,上述做法就非常非常慢了。 我们需要详细分析下这种情况并讨论下 Apriori 原理,该原理会减少关联规则学习时所需的计算量。
k项集
如果事件A中包含k个元素,那么称这个事件A为k项集,并且事件A满足最小支持度阈值的事件称为频繁k项集。由频繁项集产生强关联规则
K维数据项集LK是频繁项集的必要条件是它所有K-1维子项集也为频繁项集,记为LK-1
如果K维数据项集LK的任意一个K-1维子集Lk-1,不是频繁项集,则K维数据项集LK本身也不是最大数据项集。
Lk是K维频繁项集,如果所有K-1维频繁项集合Lk-1中包含LK的K-1维子项集的个数小于K,则Lk不可能是K维最大频繁数据项集。
同时满足最小支持度阀值和最小置信度阀值的规则称为强规则。
3 Apriori 算法实现
算法思想
首先找出所有的频集,这些项集出现的频繁性至少和预定义的最小支持度一样。然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度。然后使用第1步找到的频集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则的右部只有一项,这里采用的是中规则的定义。一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才被留下来。
Apriori算法过程
第一步通过迭代,检索出事务数据库中的所有频繁项集,即支持度不低于用户设定的阈值的项集;
第二步利用频繁项集构造出满足用户最小信任度的规则。
具体做法就是:
首先找出频繁1-项集,记为L1;然后利用L1来产生候选项集C2,对C2中的项进行判定挖掘出L2,即频繁2-项集;不断如此循环下去直到无法发现更多的频繁k-项集为止。每挖掘一层Lk就需要扫描整个数据库一遍。算法利用了一个性质:任一频繁项集的所有非空子集也必须是频繁的。
4 Apriori 原理
假设我们一共有 4 个商品: 商品0, 商品1, 商品2, 商品3。 所有可能的情况如下:如果我们计算所有组合的支持度,也需要计算 15 次。随着物品的增加,计算的次数呈指数的形式增长 。为了降低计算次数和时间,研究人员发现了一种所谓的 Apriori 原理,即某个项集是频繁的,那么它的所有子集也是频繁的。 例如,如果 {0, 1} 是频繁的,那么 {0}, {1} 也是频繁的。 该原理直观上没有什么帮助,但是如果反过来看就有用了,也就是说如果一个项集是 非频繁项集,那么它的所有超集也是非频繁项集,如下图所示:
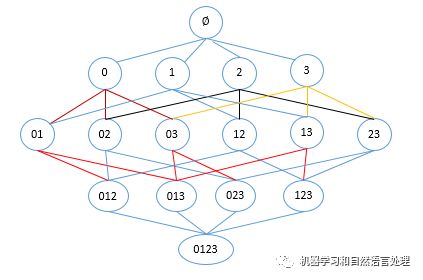
在图中我们可以看到,已知灰色部分 {2,3} 是 非频繁项集,那么利用上面的知识,我们就可以知道 {0,2,3} {1,2,3} {0,1,2,3} 都是 非频繁的。 也就是说,计算出 {2,3} 的支持度,知道它是 非频繁 的之后,就不需要再计算 {0,2,3} {1,2,3} {0,1,2,3} 的支持度,因为我们知道这些集合不会满足我们的要求。 使用该原理就可以避免项集数目的指数增长,从而在合理的时间内计算出频繁项集。
Apriori 算法优缺点
优点:易编码实现
缺点:在大数据集上可能较慢
适用数据类型:数值型 或者 标称型数据。
Apriori 算法流程步骤:
收集数据:使用任意方法。
准备数据:任何数据类型都可以,因为我们只保存集合。
分析数据:使用任意方法。
训练数据:使用Apiori算法来找到频繁项集。
测试算法:不需要测试过程。
使用算法:用于发现频繁项集以及物品之间的关联规则。
应用场景
Apriori 算法广泛应用于各种领域,通过对数据的关联性进行了分析和挖掘,挖掘出的这些信息在决策制定过程中具有重要的参考价值。
Apriori算法广泛应用于消费市场价格分析中:它能够很快的求出各种产品之间的价格关系和它们之间的影响。通过数据挖掘,市场商人可以瞄准目标客户,采用个人股票行市、最新信息、特殊的市场推广活动或其他一些特殊的信息手段,从而极大地减少广告预算和增加收入。百货商场、超市和一些老字型大小的零售店也在进行数据挖掘,以便猜测这些年来顾客的消费习惯。
Apriori算法应用于网络安全领域,比如网络入侵检测技术中。早期中大型的电脑系统中都收集审计信息来建立跟踪档,这些审计跟踪的目的多是为了性能测试或计费,因此对攻击检测提供的有用信息比较少。它通过模式的学习和训练可以发现网络用户的异常行为模式。采用作用度的Apriori算法削弱了Apriori算法的挖掘结果规则,是网络入侵检测系统可以快速的发现用户的行为模式,能够快速的锁定攻击者,提高了基于关联规则的入侵检测系统的检测性。
Apriori算法应用于高校管理中。随着高校贫困生人数的不断增加,学校管理部门资助工作难度也越加增大。针对这一现象,提出一种基于数据挖掘算法的解决方法。将关联规则的Apriori算法应用到贫困助学体系中,并且针对经典Apriori挖掘算法存在的不足进行改进,先将事务数据库映射为一个布尔矩阵,用一种逐层递增的思想来动态的分配内存进行存储,再利用向量求”与”运算,寻找频繁项集。实验结果表明,改进后的Apriori算法在运行效率上有了很大的提升,挖掘出的规则也可以有效地辅助学校管理部门有针对性的开展贫困助学工作。
Apriori算法被广泛应用于移动通信领域。移动增值业务逐渐成为移动通信市场上最有活力、最具潜力、最受瞩目的业务。随着产业的复苏,越来越多的增值业务表现出强劲的发展势头,呈现出应用多元化、营销品牌化、管理集中化、合作纵深化的特点。针对这种趋势,在关联规则数据挖掘中广泛应用的Apriori算法被很多公司应用。依托某电信运营商正在建设的增值业务Web数据仓库平台,对来自移动增值业务方面的调查数据进行了相关的挖掘处理,从而获得了关于用户行为特征和需求的间接反映市场动态的有用信息,这些信息在指导运营商的业务运营和辅助业务提供商的决策制定等方面具有十分重要的参考价值。
5 Apriori 实例理解
实例理解1
一个大型超级市场根据最小存货单位(SKU)来追踪每件物品的销售数据。从而也可以得知哪里物品通常被同时购买。通过采用先验算法来从这些销售数据中创建频繁购买商品组合的清单是一个效率适中的方法。假设交易数据库包含以下子集{1,2,3,4},{1,2},{2,3,4},{2,3},{1,2,4},{3,4},{2,4}。每个标号表示一种商品,如“黄油”或“面包”。先验算法首先要分别计算单个商品的购买频率。下表解释了先验算法得出的单个商品购买频率。
| 商品编号 | 购买次数 |
|---|---|
| 1 | 3 |
| 2 | 6 |
| 3 | 4 |
| 4 | 5 |
然后我们可以定义一个最少购买次数来定义所谓的“频繁”。在这个例子中,我们定义最少的购买次数为3。因此,所有的购买都为频繁购买。接下来,就要生成频繁购买商品的组合及购买频率。先验算法通过修改树结构中的所有可能子集来进行这一步骤。然后我们仅重新选择频繁购买的商品组合:
| 商品编号 | 购买次数 |
|---|---|
| {1,2} | 3 |
| {2,3} | 3 |
| {2,4} | 4 |
| {3,4} | 3 |
并且生成一个包含3件商品的频繁组合列表(通过将频繁购买商品组合与频繁购买的单件商品联系起来得出)。在上述例子中,不存在包含3件商品组合的频繁组合。最常见的3件商品组合为{1,2,4}和{2,3,4},但是他们的购买次数为2,低于我们设定的最低购买次数。
实例理解2
假设有一个数据库D,其中有4个事务记录,分别表示为:
| TID | Items |
|---|---|
| T1 | l1,l3,l4 |
| T2 | l2,l3,l5 |
| T3 | l1,l2,l3,l5 |
| T4 | l2,l5 |
这里预定最小支持度minSupport=2,下面用图例说明算法运行的过程:
1、扫描D,对每个候选项进行支持度计数得到表C1:
| 项集 | 支持度计数 |
|---|---|
| {l1} | 2 |
| {l2} | 3 |
| {l3} | 3 |
| {l4} | l |
| {l5} | 3 |
2、比较候选项支持度计数与最小支持度minSupport(假设为2),产生1维最大项目集L1:
| 项集 | 支持度计数 |
|---|---|
| {l1} | 2 |
| {l2} | 3 |
| {l3} | 3 |
| {l5} | 3 |
3、由L1产生候选项集C2:
| 项集 | |
|---|---|
| {l1,l2} | |
| {l1,l3} | |
| {l1,l5} | |
| {l2,l3} | |
| {l2,l5} | |
| {l3,l5} |
4、扫描D,对每个候选项集进行支持度计数:
| 项集 | 支持度计数 |
|---|---|
| {l1,l2} | 1 |
| {l1,l3} | 2 |
| {l1,l5} | 1 |
| {l2,l3} | 2 |
| {l2,l5} | 3 |
| {l3,l5} | 2 |
5、比较候选项支持度计数与最小支持度minSupport,产生2维最大项目集L2:
| 项集 | 支持度计数 |
|---|---|
| {l1,l3} | 2 |
| {l2,l3} | 2 |
| {l2,l5} | 3 |
| {l3,l5} | 2 |
6、由L2产生候选项集C3:
| 项集 | |
|---|---|
| {l2,l3,l5} |
7、比较候选项支持度计数与最小支持度minSupport,产生3维最大项目集L3:
| 项集 | 支持度计数 |
|---|---|
| {l2,l3,l5} | 2 |
算法终止。
从整体同样的能说明此过程
首先我们收集所有数据集(可以理解为商品清单),经过数据预处理后如Database TDB所示。我们扫描数据集,经过第一步对每个候选项进行支持度计数得到表C1,比较候选项支持度计数与最小支持度minSupport(假设最小支持度为2),产生1维最大项目集L1。再对L1进行组合产生候选项集C2。第二步我们对C2进行支持度计数,比较候选项支持度计数与最小支持度minSupport,产生2维最大项目集L2。由L2产生候选项集C3,对C3进行支持度计数,使用Apriori性质剪枝:频繁项集的所有子集必须是频繁的,对候选项C3,我们可以删除其子集为非频繁的选项,{A,B,C}的2项子集是{A,B},{A,C},{B,C},其中{A,B}不是L2的元素,所以删除这个选项;{A,C,E}的2项子集是{A,C},{A,E},{C,E},其中{A,E} 不是L2的元素,所以删除这个选项;{B,C,E}的2项子集是{B,C},{B,E},{C,E},它的所有2-项子集都是L2的元素,因此保留这个选项。这样,剪枝后得到{B,C,E},比较候选项支持度计数与最小支持度minSupport,产生3维最大项目集L3:继续进行没有满足条件,算法终止。
6 Apriori 算法实现
关联分析的目标包括两项:发现频繁项集和发现关联规则。Apriori算法是发现频繁项集的一种方法。 Apriori 算法的两个输入参数分别是最小支持度和数据集。该算法首先会生成所有单个物品的项集列表。接着扫描交易记录来查看哪些项集满足最小支持度要求,那些不满足最小支持度要求的集合会被去掉。然后对剩下来的集合进行组合以生成包含两个元素的项集。接下来再重新扫描交易记录,去掉不满足最小支持度的项集。该过程重复进行直到所有项集被去掉。具体算法实现详细代码请查看网页:
https://bainingchao.github.io/categories/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/Apriori/
7 应用:发现毒蘑菇相似特性
实际需求
菌类蘑菇食用对人体有益,现在市场上很受欢迎。假设你在一个山林里,遇到很多蘑菇,有些可以食用有些有毒。此刻,你或许会询问山中常驻居民,居民非常友好的告诉你伞菇上有彩色花斑的,样式好看的等等有毒。他会通过判断蘑菇的大小,高度,颜色,形状等23个特征决定蘑菇有毒,我把将居民的经验收集在mushromm.dat里面,以下是部分数据:
1 3 9 13 23 25 34 36 38 40 52 54 59 63 67 76 85 86 90 93 98 107 113
2 3 9 14 23 26 34 36 39 40 52 55 59 63 67 76 85 86 90 93 99 108 114
2 4 9 15 23 27 34 36 39 41 52 55 59 63 67 76 85 86 90 93 99 108 115 其中第一列1代表可以食用2代表有毒。其他各列代表不同特征。实际中,我们不可能对比23个特征,我们只需要找出毒蘑菇特有的几个特征即可,比如颜色彩色,形状方形等。我们自然语言描述很容易,就是看到蘑菇,对比下毒蘑菇的几个特征,不具备就可以采摘食用了。
到目前为止,我们清楚的采用毒蘑菇共同特征判断,那么如何知道毒蘑菇共同特征呢?我们就可以使用本节学习的先验算法Apriori进行关联规则找出毒蘑菇的共同特性。
算法实现
得到数据集
dataSet=[line.split() for line in open("./mush.dat").readlines()]利用我们的先验算法计算L频繁项集和所有元素支持度的全集
L, supportData = apriori(dataSet, minSupport=0.4)找出关于2的频繁子项,就知道如果是毒蘑菇,那么出现频繁的也可能是毒蘑菇
for item in L[2]:
if item.intersection('2'):
print (item)毒蘑菇的相似特性运行结果
frozenset({'59', '39', '2'})
frozenset({'59', '85', '2'})
frozenset({'34', '39', '2'})
frozenset({'90', '86', '2'})
frozenset({'34', '90', '2'})
frozenset({'39', '86', '2'})
frozenset({'85', '28', '2'})
frozenset({'59', '86', '2'})
frozenset({'34', '85', '2'})
frozenset({'90', '39', '2'})
frozenset({'39', '85', '2'})
frozenset({'34', '59', '2'})
frozenset({'34', '86', '2'})
frozenset({'90', '59', '2'})
frozenset({'85', '86', '2'})
frozenset({'90', '85', '2'})
frozenset({'63', '85', '2'})如上结果显示,遇到如上特征就很可能是毒蘑菇不能食用的啦。我们上面实验设置的2-频繁项集,根据实际需要可以调整k-频繁项集。
8 参考文献
[1] 数据挖掘十大算法:
https://wizardforcel.gitbooks.io/dm-algo-top10/content/apriori.html
[2] 中文维基百科:
https://zh.wikipedia.org/wiki/%E5%85%88%E9%AA%8C%E7%AE%97%E6%B3%95
[3] GitHub:https://github.com/BaiNingchao/MachineLearning-1
[4] 图书:《机器学习实战》
[5] 图书:《自然语言处理理论与实战》
9 完整代码下载
源码请进【机器学习和自然语言QQ群:436303759】文件下载

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









