







 cnstd是一个Python3场景文字检测工具,包含PSENet模型,支持多种backbone,可用于图片中文字检测。通过结合OCR工具cnocr,可以识别检测框内的文字。提供命令行工具进行图片预测和模型训练。项目源代码可在GitHub找到。
cnstd是一个Python3场景文字检测工具,包含PSENet模型,支持多种backbone,可用于图片中文字检测。通过结合OCR工具cnocr,可以识别检测框内的文字。提供命令行工具进行图片预测和模型训练。项目源代码可在GitHub找到。
通过识别图片中的文字,我们可以更好地理解图片的内容。cnstd 是 Python 3 下的场景文字检测(Scene Text Detection,简称STD)工具包,自带了多个训练好的检测模型,安装后即可直接使用。当前的文字检测模型使用的是 PSENet,目前支持两种 backbone 模型: mobilenetv3 和 resnet50_v1b。它们都是在 ICPR 和 ICDAR15 的 11000 张训练集图片上训练得到的。
如需要识别文本框中的文字,可以结合 OCR 工具包 cnocr 一起使用。
项目地址:https://github.com/breezedeus/cnstd ,欢迎大家尝试。
示例

安装
嗯,安装真的很简单。
pip install cnstd【注意】:
请使用Python3 (3.4, 3.5, 3.6以及之后版本应该都行),没测过Python2下是否ok。
依赖opencv,所以可能需要额外安装opencv。
已有模型
当前的文字检测模型使用的是PSENet,目前包含两个已训练好的模型,分别对应两种backbone模型:mobilenetv3 和 resnet50_v1b。它们都是在ICPR和ICDAR15训练数据上训练得到的。
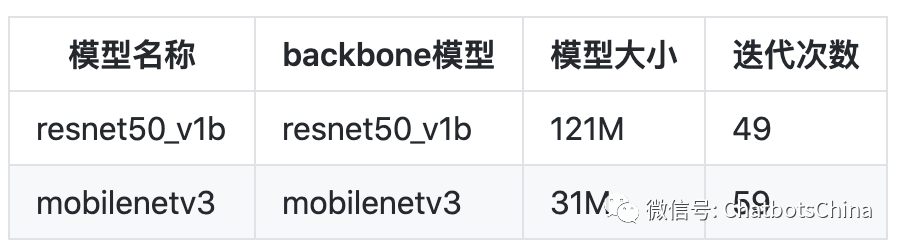
模型 resnet50_v1b 精度略高于模型 mobilenetv3。
使用方法
首次使用 cnstd 时,系统会自动下载zip格式的模型压缩文件,并存放于 ~/.cnstd目录(Windows下默认路径为 C:\Users\\AppData\Roaming\cnstd)。下载后的zip文件代码会自动对其解压,然后把解压后的模型相关目录放于~/.cnstd/0.1.0目录中。
如果系统无法自动成功下载zip文件,则需要手动从 百度云盘(提取码为 4ndj)下载对应的zip文件并把它存放于 ~/.cnstd/0.1.0(Windows下为 C:\Users\\AppData\Roam
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









