





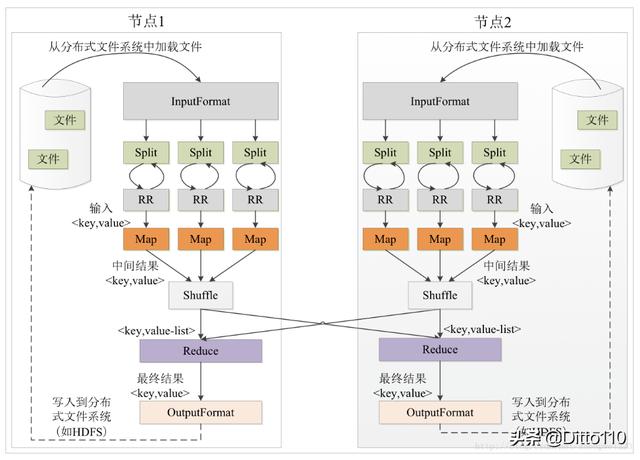
Mapreduce 执行原理(图片来源网络)
用一个简单Mapreduce Job 加以说明
//以一个简单的例子说明, 提交一个mapreduce job, 分别配置mapper 和reducer 。当然我们也可能不需要reduer 进行处理Configuration conf = new Configuration();Job job = Job.getInstance(conf, "Test MapReduce");job.setMapperClass(null);job.setReducerClass(null);job.setNumReduceTasks(2);job.waitForCompletion(true);- MapReduce 执行流程: files --> split --> map --> shuffle --> reduce
1.map
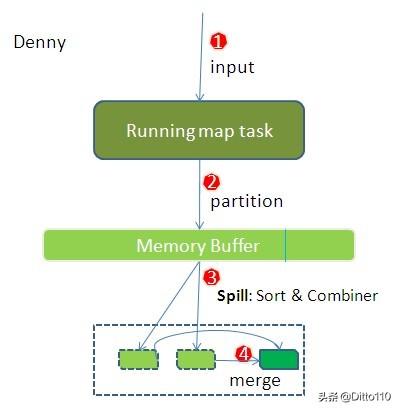
mapreduce map端进行数据处理过程(图片来于网络)
files 经过FileInputFormat 读取数据(默认是TextInputFormat),并且切割成splits,通过LineReadRecorder 进行读取(即读取一行content,以key_value的形式返回结果,如:<1,content>),每一个split 对应一个MapTask
public class ScheduleLogCleanMapper extends Mapper {@Overrideprotected void setup(Context context) {context.getConfiguration().getLong("nowDate", 0);}/*** 对从split中读取的每一条content通过每一个mapper 进行处理* @param key ,key/value 是lineReadRecorder 读取出的每一条split 信息,以 的形式* @param value* @param context 当前job 的上下文信息*/@Overrideprotected void map(LongWritable key, Text value, Context context) {String line = value.toString();context.write(NullWritable.get(), new Text(line)); //数据写入环形缓冲区}@Overrideprotected void cleanup(Context context) {}}2.map_shuffle
分区 Partition 策略
在将数据写入环形缓冲区前会对其分区存放,默认采用的是hashPartitioner 算法,
https://blog.csdn.net/asn_forever/article/details/81233547
https://blog.csdn.net/u014374284/article/details/49205885
https://blog.csdn.net/weixin_42582592/article/details/83080900
public class HashPartitioner extends Partitioner {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}}
写入环形缓冲区并落盘
由于频繁的I/O会严重降低执行效率,因此map计算的中间结果不会立即写入磁盘,而是先写入到节点的“环形缓冲区”,并且执行排序处理。当环形缓冲区的数据累计到一定量后(即mapreduce.task.io.sort.mb(默认是100M)与mapreduce.map.io.sort.spill.percent(默认0.80) 乘积),将这部分的数据进行内存锁定完成排序后(可以通过combiner将key 相同的value 进行相加,减少溢出到磁盘的数据空间占比)溢出(spill)到本地磁盘(即形成spill文件,存放到mapreduce.cluster.local.dir 目录)。
spill文件超过一定的值(mapreduce.map.combine.minspills 默认是3)可以通过combiner (合并)和merge (归并) 将多个小文件和合并为一个大文件
注意此处涉及到几个关键属性:
mapreduce.task.io.sort.mb //环形缓冲区的大小
mapreduce.map.io.sort.spill.percent //环形缓冲区的溢出比
mapreduce.cluster.local.dir //溢出文件的存放路径
mapreduce.map.combine.minspills //溢出文件的最小数量
这里有提到合并和归并,二者区别如下:
和,如果合并,会得到,如果归并,会得到>
可知是value 的组织方式不同
数据压缩输出
写磁盘时压缩map端的输出,因为这样会让写磁盘的速度更快,节约磁盘空间,并减少传给reducer的数据量。默认情况下,输出是不压缩的(将mapreduce.map.output.compress设置为true即可启动)
3.reduce_shuffle
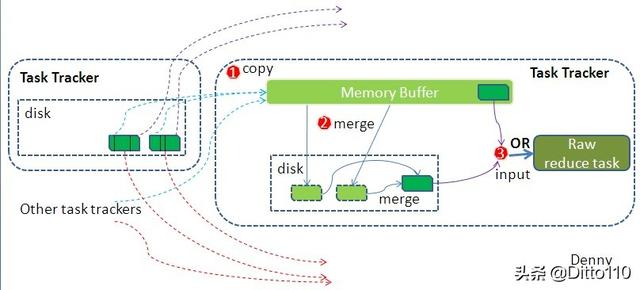
mapreduce reduce端数据处理过程(图片来源于网络)
Copy(拉取数据)
当map Task 执行结束后,reduce 进程或开启数据拉取线程(Fetcher)通过http 方式拉取map 端的结果文件,拉取到的文件会暂时放到内存缓冲区中。
Merge 阶段
copy 阶段拉取的数据会暂时放到内存缓缓冲区中,此处的内存缓冲区是基于JVM设置,由于在shuffle 阶段没有执行reduce函数,因此内存大部分都是有shuffle 过程占用。
注意此处涉及到几个关键属性:
mapred.job.shuffle.input.buffer.percent //内存缓冲区的大小,默认站内存的70%
mapred.job.shuffle.merge.percent //内存merge到磁盘的阈值,默认是66%
merge 的方式有三种,分别是内存到内存,内存到磁盘,磁盘到磁盘。
当内存缓冲区的数据一定量后,会启用内存到磁盘的merge 方式,merge的作用 主要是完成数据合并与归并的处理。
当map端的数据已经merge 结束后,开始执行磁盘到磁盘的merge方式进行合并操作,生成一个最终文件,默认情况下此文件存放在磁盘中。
4.reduce函数计算
以reduce_shuffle 的输出文件作为reduce 函数计算的输入文件,执行计算后将计算结果保存到hdfs 中。
至此,简单介绍了下mapreduce shuffle 的数据处理原理,虽然当前行业针对离线数据处理多数厂家都已经通过tez或spark 替代mapreduce,算是记个笔记吧














 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









