







 本文深入解析了MapReduce的shuffle过程,包括Mapper端的环形Buffer、Spill、合并、压缩以及Reducer端的数据合并与传递。理解shuffle对于MapReduce调优至关重要,文章还探讨了性能调优的策略,包括map优化和reduce优化。
本文深入解析了MapReduce的shuffle过程,包括Mapper端的环形Buffer、Spill、合并、压缩以及Reducer端的数据合并与传递。理解shuffle对于MapReduce调优至关重要,文章还探讨了性能调优的策略,包括map优化和reduce优化。
更新记录
- 2017-07-18 初稿
MapReduce简介
在Hadoop MapReduce中,框架会确保reduce收到的输入数据是根据key排序过的。数据从Mapper输出到Reducer接收,是一个很复杂的过程,框架处理了所有问题,并提供了很多配置项及扩展点。一个MapReduce的大致数据流如下图:
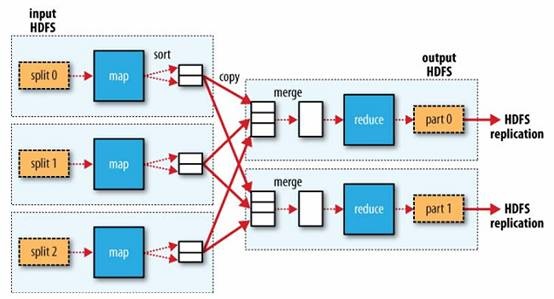
更详细的MapReduce介绍参考Hadoop MapReduce原理与实例。
Mapper的输出排序、然后传送到Reducer的过程,称为shuffle。本文详细地解析shuffle过程,深入理解这个过程对于MapReduce调优至关重要,某种程度上说,shuffle过程是MapReduce的核心内容。
Mapper端
当map函数通过context.write()开始输出数据时,不是单纯地将数据写入到磁盘。为了性能,map输出的数据会写入到缓冲区,并进行预排序的一些工作,整个过程如下图:
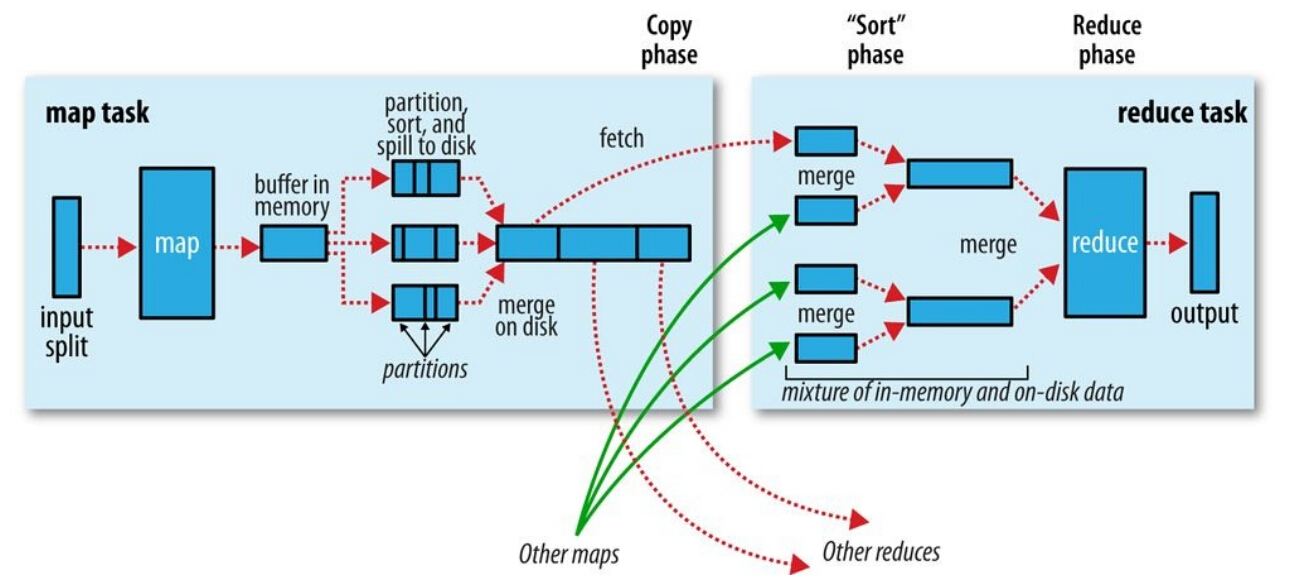
环形Buffer数据结构
每一个map任务有一个环形Buffer,map将输出写入到这个Buffer。环形Buffer是内存中的一种首尾相连的数据结构,专门用来存储Key-Value格式的数据:
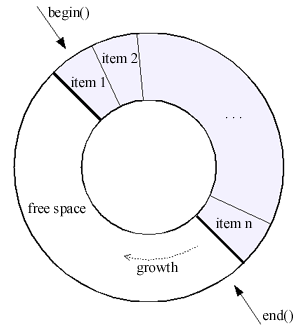
Hadoop中,环形缓冲其实就是一个字节数组:
// MapTask.java
private byte[] kvbuffer; // main output buffer
kvbuffer = new byte[maxMemUsage - recordCapacity]; kvbuffer包含数据区和索引区,这两个区是相邻不重叠的区域,用一个分界点来标识。分界点不是永恒不变的,每次Spill之后都会更新一次。初始分界点为0,数据存储方向为向上增长,索引存储方向向下:
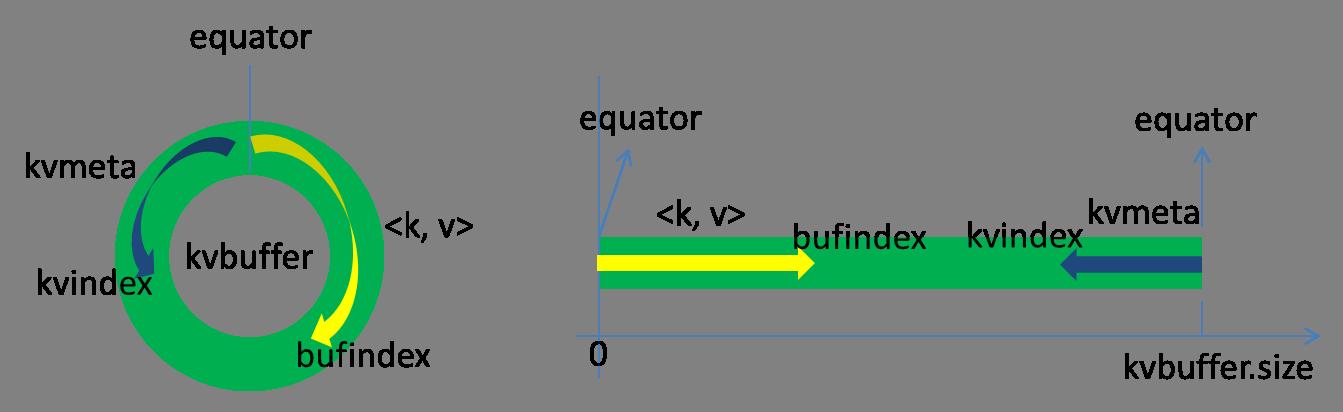
bufferindex一直往上增长,例如最初为0,写入一个int类型的key之后变为4,写入一个int类型的value之后变成8。
索引是对key-value在kvbuffer中的索引,是个四元组,占用四个Int长度,包括:
- value的起始位置
- key的起始位置
- partition值
- value的长度
private static final int VALSTART = 0; // val offset in acct
private static final int KEYSTART = 1; // key offset in acct
private static final int PARTITION = 2; // partition offset in acct
private static final int VALLEN = 3; // length of value
private static final int NMETA =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









