





参考《PostgreSQL11.2-中文手册》
下面这个链接,讲的通俗易懂,可以看看。
数据分析师不得不知道的SQL优化 - 鑫获 - 博客园www.cnblogs.com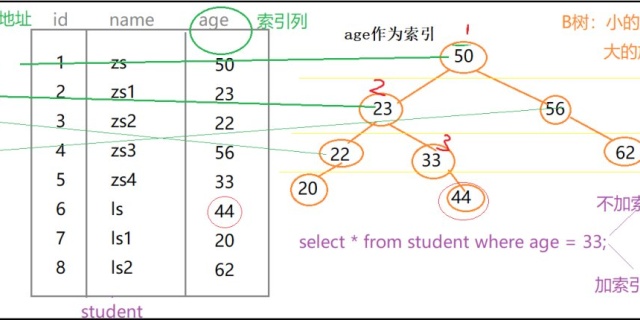
索引是提高数据库性能的常用途径。比起没有索引,使用索引可以让数据库服务器更快找到
并获取特定行。
但是索引同时也会增加数据库系统的日常管理负担,因此我们应该聪明地使用索引。
简介
CREATE TABLE test1 (
id integer,
content varchar)假设对上表做出如下查询:
SELECT content FROM test1 WHERE id = constant在没有事前准备的情况下,系统不得不扫描整个test1表,一行一行地去找到所有匹配的
项。如果test1中有很多行但是只有一小部分行(可能是0或者1)需要被该查询返回,这显
然是一种低效的方式。
但是如果系统被指示维护一个在id列上的索引,它就能使用一种更有效的方式来定位匹配行。例如,它可能仅仅需要遍历一棵搜索树的几层而已。
类似的方法也被用于大部分非小说书籍中:经常被读者查找的术语和概念被收集在一个字母
序索引中放在书籍的末尾。感兴趣的读者可以相对快地扫描索引并跳到合适的页而不需要阅
读整本书来寻找感兴趣的材料。正如作者的任务是准备好读者可能会查找的术语一样,数据
库程序员也需要预见哪些索引会有用。
正如前面讨论的,下列命令可以用来在id列上创建一个索引:
CREATE INDEX test1_id_index ON test1 (id);索引的名字test1_id_index可以自由选择,但我们最好选择一个能让我们想起该索引用途的
名字。
为了移除一个索引,可以使用DROP INDEX命令。索引可以随时被创建或删除
一旦一个索引被创建,就不再需要进一步的干预:系统会在表更新时更新索引,而且会在它
觉得使用索引比顺序扫描表效率更高时使用索引。
但我们可能需要定期地运行ANALYZE命令
来更新统计信息以便查询规划器能做出正确的决定。通过Chapter 14 的信息可以了解如何找
出一个索引是否被使用以及规划器在何时以及为什么会选择不使用索引。
索引也会使带有搜索条件的UPDATE和DELETE命令受益。此外索引还可以在连接搜索中使用。
因此,一个定义在连接条件列上的索引可以显著地提高连接查询的速度。
在一个大表上创建一个索引会耗费很长的时间。默认情况下,PostgreSQL允许在索引创建时
并行地进行读(SELECT命令),但写(INSERT、UPDATE和DELETE)则会被阻塞直到索引创建完成。
在生产环境中这通常是不可接受的。在创建索引时允许并行的写是可能的,但是有些警告需要注意,更多信息可以参考并发构建索引。
一个索引被创建后,系统必须保持它与表同步。这增加了数据操作的负担。因此哪些很少或
从不在查询中使用的索引应该被移除。
索引类型
PostgreSQL提供了多种索引类型: B-tree、Hash、GiST、SP-GiST 、GIN 和 BRIN。每一种
索引类型使用了 一种不同的算法来适应不同类型的查询。
B-tree 索引
默认情况下, CREATE INDEX命令创建适合于大部分情况的B-tree 索引。
B-tree可以在可排序数据上的处理等值和范围查询。特别地,PostgreSQL的查询规划器会
在任何一种涉及到以下操作符的已索引列上考虑使用B-tree索引:
<
<=
=
>=
>将这些操作符组合起来,例如BETWEEN和IN,也可以用B-tree索引搜索实现。同样,在索引
列上的IS NULL或IS NOT NULL条件也可以在B-tree索引中使用。
优化器也会将B-tree索引用于涉及到模式匹配操作符LIKE和~ 的查询,前提是如果模式是一
个常量且被固定在字符串的开头—例如:col LIKE 'foo%'或者col ~ '^foo', 但在col
LIKE '%bar'上则不会。但是,如果我们的数据库没有使用C区域设置,我们需要创建一个
具有特殊操作符类的索引来支持模式匹配查询,参见下面的Section 11.10 。同样可以将Btree索引用于ILIKE和~*,但仅当模式以非字母字符开始,即不受大小写转换影响的字符。
B-tree索引也可以用于检索排序数据。这并不会总是比简单扫描和排序更快,但是总是有用
的。
Hash索引
Hash索引只能处理简单等值比较。不论何时当一个索引列涉及到一个使用了=操作符的比较
时,查询规划器将考虑使用一个Hash索引。
CREATE INDEX name ON table USING HASH (column)GiST索引
GiST索引并不是一种单独的索引,而是可以用于实现很多不同索引策略的基础设施。相应
地,可以使用一个GiST索引的特定操作符根据索引策略(操作符类)而变化。作为一个例
子,PostgreSQL的标准捐献包中包括了用于多种二维几何数据类型的GiST操作符类,它用来
支持使用下列操作符的索引化查询:
<<
&<
&>
>>
<<|
&<|
|&>
|>>
@>
<@
~=
&&(这些操作符的含义见Section 9.11 )Table 64.1 中给出了标准发布中所包括的 GiST 操作
符类。contrib集合中还包括了很多其他GiST操作符类,可见Chapter 64 。
GiST索引也有能力优化“最近邻”搜索,例如:
SELECT * FROM places ORDER BY location <-> point '(101,456)' LIMIT 10;它将找到离给定目标点最近的10个位置。能够支持这种查询的能力同样取决于被使用的特定
操作符类。 在Table 64.1中,“Ordering Operators”列中列出了可以在这种方法中使用的
操作符。
SP-GiST索引
GiST相似,SP-GiST索引为支持多种搜索提供了一种基础结构。SPGiST 允许实现众多不同的非平衡的基于磁盘的数据结构,例如四叉树、k-d树和radix树。
作为一个例 子,PostgreSQL的标准捐献包中包含了一个用于二维点的SP-GiST操作符类,它
用于支持使用下列操作符的索引化查询:
<<
>>
~=
<@
<^
>^GIN 索引
GIN 索引是“倒排索引”,它适合于包含多个组成值的数据值,例如数组。倒排索引中为
每一个组成值都包含一个单独的项,它可以高效地处理测试指定组成值是否存在的查询。
与 GiST 和 SP-GiST相似, GIN 可以支持多种不同的用户定义的索引策略,并且可以与一
个 GIN 索引配合使用的特定操作符取决于索引策略。
作为一个例子,PostgreSQL的标准贡献
包中包含了用于数组的GIN操作符类,它用于支持使用下列操作符的索引化查询:
<@
@>
=
&&BRIN 索引
BRIN 索引(块范围索引的缩写)存储有关存放在一个表的连续物理块范围上的值摘要信
息。与 GiST、SP-GiST 和 GIN 相似,BRIN 可以支持很多种不同的索引策略,并且可以与一
个 BRIN 索引配合使用的特定操作符取决于索引策略。对于具有线性排序顺序的数据类型,
被索引的数据对应于每个块范围的列中值的最小值和最大值,使用这些操作符来支持用到索
引的查询:
<
<=
=
>=
>多列索引
一个索引可以定义在表的多个列上;
CREATE INDEX test2_mm_idx ON test2 (major, minor);目前,只有 B-tree、GiST、GIN 和 BRIN 索引类型支持多列索引,最多可以指定32个列(该
限制可以在源代码文件pg_config_manual.h中修改,但是修改后需要重新编PostgreSQL)。
B-tree索引
一个B-tree索引可以用于条件中涉及到任意索引列子集的查询,但是当先导列(即最左边的
那些列)上有约束条件时索引最为有效。
确切的规则是:
- 在先导列上的等值约束,加上第一个无等值约束的列上的不等值约束,将被用于限制索引被扫描的部分。
- 在这些列右边的列上的约束将在索引中被检查,这样它们适当节约了对表的访问,但它们并未减小索引被扫描的部分。
例如,在(a, b, c)上有一个索引并且给定一个查询条件WHERE a = 5 AND b >= 42 AND c < 77,对索引的扫描将从第一个具有a = 5和b = 42的项开始向上进行,直到最后一个具有a = 5的项。
在扫描过程中,具有c>= 77的索引项将被跳过,但是它们还是会被扫描到。这个索引在原则上可以被用于在b和/或c上有约束而在a上没有约束的查询,但是整个索引都不得不被扫描,因此在大部分情况下规划器宁可使用一个顺序的表扫描来替代索引。
多列GiST索引
一个多列GiST索引可以用于条件中涉及到任意索引列子集的查询。在其余列上的条件将限制
由索引返回的项,但是第一列上的条件是决定索引上扫描量的最重要因素。当第一列中具有
很少的可区分值时,一个GiST索引将会相对比较低效,即便在其他列上有很多可区分值。
其他多列索引
一个GIN索引可以用于条件中涉及到任意索引列子集的查询。与B-tree和GiST不同,GIN的搜
索效率与查询条件中使用哪些索引列无关。
多列 BRIN 索引可以被用于涉及该索引被索引列的任意子集的查询条件。和 GIN 相似且不
同于 B-树 或者 GiST,索引搜索效率与查询条件使用哪个索引列无关。在单个表上使用多个
BRIN 索引来取代一个多列 BRIN 索引的唯一原因是为了使用不同的pages_per_range存储参
数。
当然,要使索引起作用,查询条件中的列必须要使用适合于索引类型的操作符,使用其他操
作符的子句将不会被考虑使用索引。
多列索引应该较少地使用。在绝大多数情况下,单列索引就足够了且能节约时间和空间。具
有超过三个列的索引不太有用,除非该表的使用是极端程式化的。Section 11.5 以及Section 11.9 中有对不同索引配置优点的讨论。
索引和ORDER BY
除了简单地查找查询要返回的行外,一个索引可能还需要将它们以指定的顺序传递。这使得
查询中的ORDER BY不需要独立的排序步骤。在PostgreSQL当前支持的索引类型中,只有Btree可以产生排序后的输出,其他索引类型会把行以一种没有指定的且与实现相关的顺序返
回。
规划器会考虑以两种方式来满足一个ORDER BY说明:扫描一个符合说明的可用索引,或者先
以物理顺序扫描表然后再显式排序。对于一个需要扫描表的大部分的查询,一个显式的排序
很可能比使用一个索引更快,因为其顺序访问模式使得它所需要的磁盘I/O更少。只有在少
数行需要被取出时,索引才会更有用。
一种重要的特殊情况是ORDER BY与LIMIT n联合使用:一个显式的排序将会处理所有的数据来确定最前面的n行,但如果有一个符合ORDER BY的索引,前n行将会被直接获取且根本不需要扫描剩下的数据。
默认情况下,B-tree索引将它的项以升序方式存储,并将空值放在最后。这意味着对列x上
索引的一次前向扫描将产生满足ORDER BY x(或者更长的形式:ORDER BY x ASC NULLS
LAST)的结果。索引也可以被后向扫描,产生满足ORDER BY x DESC(ORDER BY x DESC NULLS
FIRST, NULLS FIRST是ORDER BY DESC的默认情况)。
我们可以在创建B-tree索引时通过ASC、DESC、NULLS FIRST和NULLS LAST选项来改变索引的
排序,例如:
CREATE INDEX test2_info_nulls_low ON test2 (info NULLS FIRST);
CREATE INDEX test3_desc_index ON test3 (id DESC NULLS LAST);
一个以升序存储且将空值前置的索引可以根据扫描方向来支持ORDER BY x ASC NULLS FIRST或ORDER BY x DESC NULLS LAST。
读者可能会疑惑为什么要麻烦地提供所有四个选项,因为两个选项连同可能的后向扫描可以
覆盖所有ORDER BY的变体。在单列索引中这些选项确实有冗余,但是在多列索引中它们却很
有用。考虑(x, y)上的一个两列索引:它可以通过前向扫描满足ORDER BY x, y,或者通过
后向扫描满足ORDER BY x DESC, y DESC。但是应用可能需要频繁地使用ORDER BY x ASC,
y DESC。这样就没有办法从通常的索引中得到这种顺序,但是如果将索引定义为(x ASC, y
DESC)或者(x DESC, y ASC)就可以产生这种排序。
显然,具有非默认排序的索引是相当专门的特性,但是有时它们会为特定查询提供巨大的速
度提升。是否值得维护这样一个索引取决于我们会多频繁地使用需要特殊排序的查询。
组合多个索引
只有查询子句中在索引列上使用了索引操作符类中的操作符并且通过AND连接时才能使用单
一索引。例如,给定一个(a, b) 上的索引,查询条件WHERE a = 5 AND b = 6可以使用该索
引,而查询WHERE a = 5 OR b = 6不能直接使用该索引。
幸运的是,PostgreSQL具有组合多个索引(包括多次使用同一个索引)的能力来处理那些不
能用单个索引扫描实现的情况。系统能在多个索引扫描之间安排AND和OR条件。
例如,
WHERE x = 42 OR x = 47 OR x = 53 OR x= 99这样一个查询可以被分解成为四个独立的在x上索引扫描,每一个扫描使用其中一个条件。
这些查询的结果将被“或”起来形成最后的结果。另一个例子是如果我们在x和y上都有独立的索引,WHERE x = 5 AND y = 6这样的查询的一种可能的实现方式就是分别使用两个索引配合相应的条件,然后将结果“与”起来得到最后的结果行。
为了组合多个索引,系统扫描每一个所需的索引并在内存中准备一个位图用于指示表中符合
索引条件的行的位置。然后这些位图会被根据查询的需要“与”和“或”起来。最后,实际
的表行将被访问并返回。表行将被以物理顺序访问,因为位图就是以这种顺序布局的。
这意味着原始索引中的任何排序都会被丢失,并且如果存在一个ORDER BY子句就需要一个单独的排序步骤。
由于这个原因以及每一个附加的索引都需要额外的时间,即使有额外的索引可用,规划器有时也会选择使用单一索引扫描。
在所有的应用(除了最简单的应用)中,可能会有多种有用的索引组合,数据库开发人员必
须做出权衡以决定提供哪些索引。
有时候多列索引最好,但是有时更好的选择是创建单独的索引并依赖于索引组合特性。例如,如果我们的查询中有时只涉及到列x,有时候只涉及到列y,还有时候会同时涉及到两列,我们可以选择在x和y上创建两个独立索引然后依赖索引组合来处理同时涉及到两列的查询。我们当然也可以创建一个(x, y)上的多列索引。
当查询同时涉及到两列时,该索引会比组合索引效率更高,但是正如Section 11.3 中讨论的,它在只涉及到y的查询中几乎完全无用,因此它不能是唯一的一个索引。一个多列索引和一个y上的独立索引的组合将会工作得很好。
多列索引可以用于那些只涉及到x的查询,尽管它比x上的独立索引更大且更慢。最后一种选择是创建所有三个索引,但是这种选择最适合表经常被执行所有三种查询但是很少被更新的情况。如果其中一种查询要明显少于其他类型的查询,
我们可能需要只为常见类型的查询创建两个索引。
唯一索引
索引也可以被用来强制列值的唯一性,或者是多个列组合值的唯一性
CREATE UNIQUE INDEX name ON table (column [, ...]);当前,只有B-tree能够被声明为唯一。
当一个索引被声明为唯一时,索引中不允许多个表行具有相同的索引值。空值被视为不相
同。一个多列唯一索引将会拒绝在所有索引列上具有相同组合值的表行。
PostgreSQL会自动为定义了一个唯一约束或主键的表创建一个唯一索引。该索引包含组成主
键或唯一约束的所有列(可能是一个多列索引),它也是用于强制这些约束的机制。
不需要手工在唯一列上创建索引,如果那样做也只是重复了自动创建的索引而已。
表达式索引
一个索引列并不一定是底层表的一个列,也可以是从表的一列或多列计算而来的一个函数或
者标量表达式。这种特性对于根据计算结果快速获取表中内容是有用的。
例如,一种进行大小写不敏感比较的常用方法是使用lower函数
SELECT * FROM test1 WHERE lower(col1) = 'value'这种查询可以利用一个建立在lower(col1)函数结果之上的索引:
CREATE INDEX test1_lower_col1_idx ON test1 (lower(col1))如果我们将该索引声明为UNIQUE,它将阻止创建在col1值上只有大小写不同的行
另一个例子,如果我们经常进行如下的查询:
SELECT * FROM people WHERE (first_name || ' ' || last_name) = 'John Smith';那么值得创建一个这样的索引:
CREATE INDEX people_names ON people ((first_name || ' ' || last_name))正如第二个例子所示,CREATE INDEX命令的语法通常要求在被索引的表达式周围书写圆括
号。而如第一个例子所示,当表达式只是一个函数调用时可以省略掉圆括号;
索引表达式的维护代价较为昂贵,因为在每一个行被插入或更新时都得为它重新计算相应的
表达式。然而,索引表达式在进行索引搜索时却不需要重新计算,因为它们的结果已经被存
储在索引中了。
在上面两个例子中,系统将会发现查询的条件是WHERE indexedcolumn= 'constant',因此查询的速度将等同于其他简单索引查询。因此,表达式索引对于检索速度远比插入和更新速度重要的情况非常有用。
部分索引
一个部分索引是建立在表的一个子集上,而该子集则由一个条件表达式(被称为部分索引
的谓词)定义。而索引中只包含那些符合该谓词的表行的项。部分索引是一种专门的特性,
但在很多种情况下它们也很有用。
使用部分索引的一个主要原因是避免索引公值。由于搜索一个公值的查询(一个在所有表行
中占比超过一定百分比的值)不会使用索引,所以完全没有理由将这些行保留在索引中。这
可以减小索引的尺寸,同时也将加速使用索引的查询。它也将加速很多表更新操作,因为这
种索引并不需要在所有情况下都被更新。Example 11.1 展示了一种可能的应用:
Example 11.1. 建立一个部分索引来排除公值
假设我们要在一个数据库中保存网页服务器访问日志。大部分访问都来自于我们组织内的IP
地址,但是有些来自于其他地方(如使用拨号连接的员工)。如果我们主要通过IP搜索来自
于外部的访问,我们就没有必要索引对应于我们组织内网的IP范围。
假设有这样一个表:
CREATE TABLE access_log (
url varchar,
client_ip inet,
...
)用以下命令可以创建适用于我们的部分索引:
CREATE INDEX access_log_client_ip_ix ON access_log (client_ip)
WHERE NOT (client_ip > inet '192.168.100.0' AND
client_ip < inet '192.168.100.255')一个使用该索引的典型查询是:
SELECT *
FROM access_log
WHERE url = '/index.html' AND client_ip = inet '212.78.10.32';一个不能使用该索引的查询:
SELECT *
FROM access_log
WHERE client_ip = inet '192.168.100.23';可以看到部分索引查询要求公值能被预知,因此部分索引最适合于数据分布不会改变的情
况。当然索引也可以偶尔被重建来适应新的数据分布,但是这会增加维护负担。
Example 11.2 展示了部分索引的另一个可能的用途:从索引中排除那些查询不感兴趣的值。
这导致了上述相同的好处,但它防止了通过索引来访问“不感兴趣的”值,即便在这种情况
下一个索引扫描是有益的。显然,为这种场景建立部分索引需要很多考虑和实验。
Example 11.2. 建立一个部分索引来排除不感兴趣的值
如果我们有一个表包含已上账和未上账的订单,其中未上账的订单在整个表中占据一小部分
且它们是最经常被访问的行。我们可以通过只在未上账的行上创建一个索引来提高性能。创
建索引的命令如下:
CREATE INDEX orders_unbilled_index ON orders (order_nr)
WHERE billed is not true使用该索引的一个可能查询是:
SELECT * FROM orders WHERE billed is not true AND order_nr < 10000;然而,索引也可以用于完全不涉及order_nr的查询,例如
SELECT * FROM orders WHERE billed is not true AND amount > 5000.00;这并不如在amount列上部分索引有效,因为系统必须扫描整个索引。然而,如果有相对较少
的未上账订单,使用这个部分索引来查找未上账订单将会更好。
注意这个查询将不会使用该索引:
SELECT * FROM orders WHERE order_nr = 3501;订单3501可能在已上账订单或未上账订单中。
Example 11.2 也显示索引列和谓词中使用的列并不需要匹配。PostgreSQL支持使用任意谓词
的部分索引,只要其中涉及的只有被索引表的列。然而,记住谓词必须匹配在将要受益于索
引的查询中使用的条件。更准确地,只有当系统能识别查询的WHERE条件从数学上索引的谓
词时,一个部分索引才能被用于一个查询。PostgreSQL并不能给出一个精致的定理证明器来
识别写成不同形式在数学上等价的表达式(一方面创建这种证明器极端困难,另一方面即便
能创建出来对于实用也过慢)。系统可以识别简单的不等蕴含,例如“x < 1”蕴含“x
< 2”;否则谓词条件必须准确匹配查询的WHERE条件中的部分,或者索引将不会被识别为可
用。匹配发生在查询规划期间而不是运行期间。因此,参数化查询子句无法配合一个部分索
引工作。例如,对于参数的所有可能值来说,一个具有参数“x < ?”的预备查询绝不会蕴
含“x < 2”。
部分索引的第三种可能的用途并不要求索引被用于查询。其思想是在一个表的子集上创建一
个唯一索引,如Example 11.3 所示。这对那些满足索引谓词的行强制了唯一性,而对那些不
满足的行则没有影响。
Example 11.3. 建立一个部分唯一索引
假设我们有一个描述测试结果的表。我们希望保证其中对于一个给定的主题和目标组合只有
一个“成功”项,但其中可能会有任意多个“不成功”项。实现它的方式是:
CREATE TABLE tests (
subject text,
target text,
success boolean,
...
)CREATE UNIQUE INDEX tests_success_constraint ON tests (subject, target)
WHERE success;当有少数成功测试和很多不成功测试时这是一种特别有效的方法。
最后,一个部分索引也可以被用来重载系统的查询规划选择。同样,具有特殊分布的数据集
可能导致系统在它并不需要索引的时候选择使用索引。在此种情况下可以被建立,这样它将
不会被那些无关的查询所用。通常,PostgreSQL会对索引使用做出合理的选择(例如,它会
在检索公值时避开索引,这样前面的例子只能节约索引尺寸,它并非是避免索引使用所必需
的),非常不正确的规划选择则需要作为故障报告。
记住建立一个部分索引意味着我们知道的至少和查询规划器所知的一样多,尤其是我们知道
什么时候一个索引会是有益的。构建这些知识需要经验和对于PostgreSQL中索引工作方式的
理解。在大部分情况下,一个部分索引相对于一个普通索引的优势很小。
关于部分索引的更多信息可以在[ston89b]、[olson93]和[seshadri95]中找到















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









