





本文翻译自:http://www.cs.rochester.edu/~scott/papers/1996_PODC_queues.pdf
由于本人才疏学浅,翻译难免有误,望各位不吝惜指正。
概述
借鉴前人的成果,我们发明了一个新的非阻塞并行队列算法和一个新的入队和出队操作可以并行的双锁队列算法。这两个算法都很简单,高效,实用,但令我们吃惊的是在文献中尚未有有关它们的记录。我们在12个结点的SGI挑战者多处理器上实验了两个算法,结果表明新的非阻塞队列始终比现在已知的其它方法表现得好。该算法非常适合提供了通用原子原语(比如compare and swap或load linked/store conditiona)的机器。双锁并行队列在多个处理器同时访问时表现好于单锁队列,非常适合具备非通用原子原语(比如test_and_set),且队列操作频繁的场景。
1.引言
并行队列在并行程序和操作系统中被广泛使用。为了确保正确性,并行访问共享队列需要进行同步操作。一般而言,并行数据结构算法分为两大类:阻塞和非阻塞。阻塞算法允许较慢的进程或被延迟的进程阻止较快的进程完成在共享数据结构上的操作。非阻塞算法保证如果有一个或多个进程尝试在一个共享数据结构上执行操作,操作在有限的时间内就可以完成。在异步(尤其是多道程序设计的系统)多处理机系统上,当一个进程宕掉或在一个不合适的时候被延迟,阻塞算法的性能会明显下降,而这对非阻塞算法影响不大。
目前,已经有很多并行队列的无锁算法被提出。Hwang和Briggs[7],Sites[17]和Stone[20]发表了基于CAS的无锁算法。这些算法不够完整,省略了很多需要处理的细节问题,比如对空队列和单个元素的队列,并行入队,出队的处理,Lamport[9]发表了一个要求只有一个进程入队和一个进程出队的无等待并行算法。
Gottlieb et al.[3]和Mellor-Crummey[11]发表了一个无锁但不是非阻塞的算法:不使用锁,但允许较慢的进程延迟较快的进程。
Treiber[21]发表了一个非阻塞但不高效的算法:出队操作花费的时间和队列中元素的个数成正比。Herlihy[6];Prakash,Lee和Johnson[15];Turek,Shasha和Prakash[22];Barnes[2]提出了一个通用的将串行或基于锁的并行算法转换为非阻塞算法的方法。但转换生成的算法不如专用算法高效。
Massalin和Pu[10]发表了基于double compare and swap原语(同时在两个内存位置操作数据,似乎只有摩托罗拉68000家族的后期成员支持这一原语)的无锁算法。Herlihy和Wing[4]发表了一个基于数组,但对数组有一定要求的算法。Valois[23]发表了一个基于数组的算法,但需要使用非对齐compare and swap原语或类似摩托罗拉的double compare and swap原语。
Stone[18]发表了一个阻塞的,不可线性化的无锁队列算法。较慢的进程可能会造成较快的进程入队结点后检查队列,却发现队列以及为空,尽管入队的结点并没有出队。并且,该算法是阻塞的,较慢的进程可以无限期延迟较快的进程执行。我们的实验结果也表明,一个较慢进程的出队操作和其它较快进程的入队,出队操作会造成已经入队的结点永久丢失。Stone还发表了一个循环单链表非阻塞算法,这一算法使用锚点指针取代Head 和Tail 指针来管理队列,我们的实验结果表明发生竞争时,较慢的出队进程会造成已经入队的结点永久丢失。
Prakash,Lee和Johnson[14,16]发表了一个可线性化的非阻塞算法,这一算法通过快照决定队列操作的优先级,允许较快的进程先完成队列操作,而不是等待较慢的进程完成操作。
Valois[23,24]发表了一个非阻塞算法,这一算法可以避免Prakash et al.的算法由于快照导致的竞争问题,它在链表中增加了一个空的头结点,简化了空链表和只有一个元素的链表的处理(由Sites[17]提出)。然而,该算法的Tail 指针在Head 指针之后进行操作,导致出队进程不能安全地进行出队结点的内存释放或重用出队结点。如果一个进程释放了出队的结点内存,链表可能会断开,导致之前入队的结点也丢失掉。除此之外,内存是一个有限的资源,不能够重用结点是不能让人接受的。所以,Valois提出了一个特殊的机制来完成释放和分配内存。这一机制对每个结点关联了一个引用计数。每次指针指向一个结点时,这个结点的关联的引用计数就自动增加,当指针不需要访问这个结点时,结点关联的引用计数自动减少。当没有指针指向它时,结点内存才可以被释放。
我们讨论了这一内存管理机制和与之相关的非阻塞算法[13],它存在很多问题:该内存管理机制不能够保证一直能满足该算法的内存需要。考虑一个进程引用了一个结点,然后被延迟,这导致其它进程也无法释放该结点的next 域所链接的一连串结点(因为引用计数的原因),这种情况下,即使队列只有常数大小,也会很快将内存耗尽。我们使用了一个最大长度为12的队列,进行一千万次次入队和出队操作,很快就耗尽了内存。
上面讨论的算法大部分是基于CAS操作的,必须对ABA问题进行处理:一个进程读取了共享内存上的一个值,然后计算出了一个新值,尝试使用CAS操作将其写入共享内存,在读取操作和CAS操作之间可能有其它进程将A改为B,然后又将B改为A,这就造成CAS操作在它不应该成功时成功进行。解决这一问题的一个做法就是使用计数器,在成功进行CAS操作时增加计数器的值,这一方法不能保证ABA问题一定不会出现,但使ABA问题出现的机率变得非常小。使用这一方法需要双字CAS支持,或者使用数组索引代替指针,从而节约掉一个字的计数器。Valois的引用计数技术可以防止ABA问题,并且不需要修改计数器和进行双字CAS操作。Mellor-Crummey的无锁队列算法[11]使用fetch_and_store-修改-compare_and_swap这一序列执行操作,不需要特殊的机制来避免ABA问题,然而这也造成该算法成为一个阻塞算法。
在第二节,我们给出了两个新的并行队列算法,它们由上面的提到的算法启发而来。这两个算法都非常的简单,实用。其中一个算法是非阻塞的,另一个使用了两个锁。我们在第三节对两个算法的正确性进行了证明。在第四节给出了使用12个结点的SGI多处理机进行实验的结果。我们比较它们和单锁队列,Mellor-Crummey的阻塞算法[11],Prakash et al.的非阻塞算法[16]以及Valois的非阻塞算法[24],结果证明我们的非阻塞算法非常适合在多道程序设计的系统下使用,双锁队列算法在多道程序设计系统下表现不佳,但也好于单锁队列在多个进程竞争时的表现。在第五节,我们对文章进行了总结。
2.算法


图1中的伪代码展示了我们的无锁队列算法。算法的数据结构采用一个带有Head 和Tail 指针的单链表实现。和Valois的算法一样,Head 指针永远指向一个位于链表头部的空结点。Tail 指针指向链表的最后一个或倒数第二个结点。这一算法使用CAS原语和计数器来避免ABA问题。为了允许出队进程释放出队后的结点,出队操作保证Tail 指针不会指向已经出队的结点及其之前的结点。这也意味着出队的结点可以安全地被重复使用。
为了确保数据一致性,算法对之前读取的值进行检查,保证它们没有发生改变。这一部分代码和Prakash et al.的代码相似,但更加简单(我们只检查了一个共享变量,而不是Prakash代码的两个)。类似的技巧也可以用在Stone的阻塞算法中来防止出现竞争情况。我们使用类似Treiber的简单高效的非阻塞栈算法[2]来实现无锁队列。

图2中的伪代码展示了我们的双锁队列算法。这一算法使用了两个独立的Head 和Tail 锁,允许入队和出队操作并行。和无锁队列相同,我们使用了一个空的头结点。由于这个空的头结点存在,入队进程不需要访问Head 指针,出队进程不需要访问Tail 指针,从而避免了由于进程之间以不同的顺序尝试获取锁可能造成的死锁问题。
3.正确性证明
3.1 安全性
我们给出的算法满足下面这些属性,所以它是安全的:
- 链表总是连通的。
- 只在链表的最后一个结点之后插入结点。
- 只从链表的头部移除结点。
- Head 指针总是指向链表的第一个结点。
- Tail 指针总是指向链表中的一个结点。
初始时,上面的所有属性都被满足。我们使用归纳法证明这些属性可以一直被满足。
- 链表总是连通的,因为一个结点被插入之后,它的next 指针在结点被释放之前不会被设置为NULL,并且所有结点从头部被删除后才会被释放(属性3)。
2. 在无锁算法中,结点只在链表尾部插入,这是因为结点是通过Tail 指针插入链表尾部,而Tail 指针总是指向链表中的一个结点(属性5),并且被插入的结点是被一个next 域为NULL的结点所连接,链表中这样的结点只有链表的最后一个结点这一个(属性1)。
在基于锁的算法中,结点只在链表尾部插入,这是因为结点在Tail 指针指向它之后才被插入,而Tail 指针在未被锁保护时,总是指向链表中的最后一个结点。
3. 结点只从链表头部移除,只有结点被Head 指针指向时才能被移除,而Head 指针总是指向链表中的第一个结点(属性4)。
4. Head 指针总是指向链表中的第一个结点,这是因为它的值只被原子地改变(使用锁或CAS)指向下一个结点。当它改变时,它之前指向的结点从链表中移除。Head 指针的值不可能为NULL ,这是因为链表中至少存在一个结点(头结点)。
5. Tail 指针总是指向链表中的一个结点,这是因为它指向的结点总是位于Head 指针指向的结点之后,所以它不可能指向一个已经被移除的结点。当Tail 指针的值改变时,它会指向链表中的下一个结点。当Tail 指针指向的结点的next 域为NULL 时,它不会改变。
3.2 线性化
我们给出的算法是可以线性化的,入队和出队操作都会在某个特定点生效。当分配的结点被链接到链表的最后一个结点时,入队操作生效。当Head 指针指向链表中的下一个结点时,出队操作生效。并且,根据前一节,队列使用的变量总是反应队列的当前状态,不存在瞬时的可能造成错误的状态(比如,一个非空队列的变量反应队列当前为空)。
3.3 无锁算法是非阻塞的
无锁算法是非阻塞的,它没有延迟进程在队列上进行操作的尝试,操作可以保证在有限的时间内完成。
入队操作的循环只有在行E7,行E8的条件检测失败或行E9的CAS操作失败才会进行。出队操作的循环只有在D5的条件检测失败,行D6的条件检测成立(队列非空)或行D13的CAS操作失败才会进行。
我们通过证明一个进程在其它进程操作队列时,不会执行超过一个有限数量的循环来证明算法是非阻塞的。
- 行E7的条件失败,说明Tail 指针被另一个进程执行行E5重写。Tail 指针总是指向链表的最后一个或倒数第二个结点,当Tail 指针改变时,它会指向之前指向结点的next 域指向的结点。所以,如果行E7的条件失败超过一次,说明另一个进程完成了一个完整的入队操作。
- 行E8的条件失败,说明Tail 指针正在改变它的值从指向链表的倒数第二个结点到指向最后一个结点。在行E13后,Tail 指针一定指向最后一个结点,除非此时另一个进程成功地将一个新的结点入队。所以,如果行E8的条件失败超过一次,说明另一个进程完成了一个完整的入队操作。
- 行E9的CAS操作失败,说明此时另一个进程成功地将一个新的结点入队。
- 行D5的条件和行D13的CAS操作失败,说明Head 指针被另一个进程重写。而Head 指针只在进程成功地将一个结点出队时才会被重写。
- 行D6的条件满足(队列非空),说明Tail 指针正从指向链表中的倒数第二个结点变为指向倒数第一个结点(在这种情况下,也是链表中第一个结点)。在行D10的CAS操作之后,Tail 指针必定指向链表中的最后一个结点,除非另一个进程此时成功地将一个新的结点入队。所以,如果行D6的条件满足超过一次,必定有另一个进程完成了一个完整的入队操作(与之相同,或有另一个进程成功将一个结点出队)。
双锁算法不会发生死锁
双锁算法不包含任何循环。如果使用的互斥锁算法不会发生死锁,那么双锁算法也就不会发生死锁。目前存在很多互斥锁算法不会发生死锁[12]。
4.性能
我们使用12核的Silicon Graphics Challenge处理器比较了新算法和之前的单锁算法,Prakash et al.[16]的算法,Valois的算法[24](修改了内存管理机制[13])和Mellor-Crummey的算法[11]。Prakash et al.的算法在过去被认为是最好的无锁队列算法,Mellor-Crummey的算法是无锁的但却是阻塞算法,它的代码比Prakash et al.的算法代码简单,应该具有较低的常数开销,但在多道程序设计的系统下应该表现不佳。我们使用Valois的算法做比较来证明在多道程序设计的系统上不够高效的非阻塞算法也比阻塞算法表现得好。
对于双锁队列算法,我们使用了test_and_set锁,并对实验结果进行了一定的补偿。
为了确保实验结果得准确性,实验时,我们独占地使用了多处理器,阻止其它用户访问它。除此之外,我们还使用了挑战者机器绑定进程到特定核心这一功能。这样做,我们就可以模拟出不同数量的处理器进行实验。
实验开始时,所有队列都是空的,每个进程入队一个结点,做一些其它的工作,然后出队一个结点,做一些其它工作,反复进行。假设使用
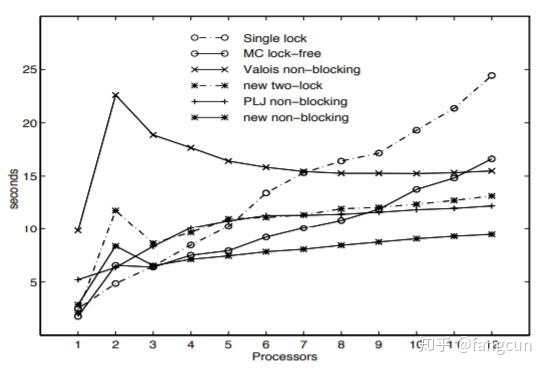
图3显示了进行一百万次入队和出队操作的净耗时。这个数据粗略等于一次入队和出队操作的毫秒耗时。更准确的,对于
只使用一个处理器时,除了第一次循环外,所有内存访问都命中缓存,操作完成的时间也非常短。使用两个处理器时,Head 指针,Tail 指针以及队列元素的争夺造成了很高比例的缓存命中失败,造成操作完成时间较长。处理器2的队列操作可以发生在处理器1进行其它工作时,换句话说,使用两个处理器时,我们统计的是一个处理器完成
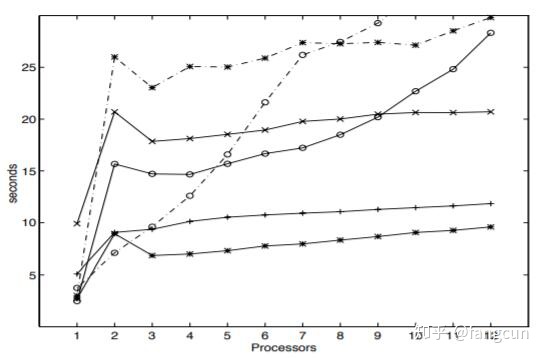
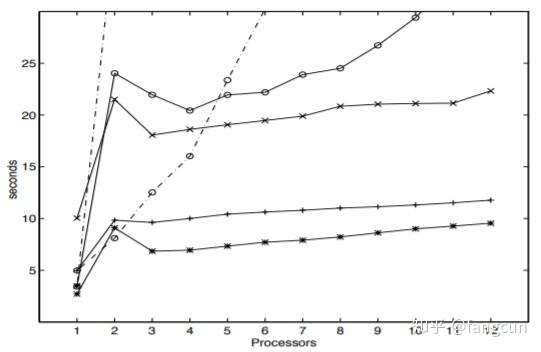
图4和图5是分别在每个处理器上执行两个和三个进程运行算法的结果,操作系统调度进程大概花费了10ms。如之前所预料的,阻塞算法在多道程序设计的系统下表现非常差,一个不合时宜的进程抢占就会阻塞每一个进程,随着进程数的增加性能下降剧烈。
从实验结果我们可以看出新的非阻塞算法在使用三个或更多处理器时表现得比其它算法好。对于使用一个或两个处理器得情况,它的表现也足够不错,可以认为新的非阻塞算法适用于所有场景。双锁队列算法在专用系统上使用超过5个处理器时表现得比单锁算法好,非常适合非多道程序设计,缺乏通用原子原语(compare_and_swap或load_linked/store_conditional)的系统使用。
5.总结
队列在并行程序中被广泛使用,并且它们的性能是人们的主要关注点。我们在这里给出了一个简单,非阻塞,并且高效的并行队列算法。这一算法尚未出现在文献中,非常适合带有通用原子原语(比如compare_and_swap或loadlinked/store_conditional)的多处理机上使用。
我们还给出了一个使用两个独立的Head 和Tail 锁的队列算法。它的数据结构和无锁队列类似,但在同一刻,只允许一个入队和一个出队操作。它可以工作在支持类似test_and_set原子原语的机器上。我们推荐在只有一个或两个进程访问队列时使用它。
这篇论文是一项更大工程的一部分,这项工程旨在寻找常用数据结构的并行替代。该工程包括栈,队列,堆,搜索树,哈希表,单锁算法,特定数据结构多锁算法,特定和非特定非阻塞算法,功能集中管理系统。
与其它算法相比[8,25,26],我们的算法非常适合在调度程序中使用来避免不合理的进程抢占。避免延迟进程是非阻塞并行算法的主要好处,我们计划在多道程序设计系统下对它们进行这方面的比较。
参考文献
[1] T. E. Anderson. The Performance of Spin Lock Alternatives for Shared-Memory Multiprocessors. IEEE Transactions on Parallel and Distributed Systems, 1(1):6–16, January 1990.
[2] G. Barnes. A Method for Implementing Lock-Free Data Structures. In Proceedings of the Fifth Annual ACM Symposium on Parallel Algorithms and Architectures, Velen, Germany, June – July 1993.
[3] A. Gottlieb, B. D. Lubachevsky, and L. Rudolph. Basic Techniques for the Efficient Coordination of Very Large Numbers of Cooperating Sequential Processors. ACM Transactions on Programming Languages and Systems, 5(2):164–189, April 1983.
[4] M. P. Herlihy and J. M. Wing. Axions for Concurrent Objects. In Proceedings of the 14th ACM Symposium on Principles of Programming Languages,pages 13– 26, January 1987.
[5] M. P. Herlihy and J. M. Wing. Linearizability: A Correctness Condition for Concurrent Objects. ACM Transactions on Programming Languages and Systems, 12(3):463–492, July 1990.
[6] M. Herlihy. A Methodology for Implementing Highly Concurrent Data Objects. ACM Transactions on Programming Languages and Systems, 15(5):745–770, November 1993.
[7] K. Hwang and F. A. Briggs. Computer Architecture and Parallel Processing. McGraw-Hill, 1984.
[8] L. Kontothanassis and R. Wisniewski. Using Scheduler Information to Achieve Optimal Barrier Synchronization Performance. In Proceedings of the Fourth ACM Symposium on Principles and Practice of Parallel Programming, May 1993.
[9] L. Lamport. Specifying Concurrent Program Modules. ACM Transactions on Programming Languages and Systems, 5(2):190–222, April 1983.
[10] H. Massalin and C. Pu. A Lock-Free Multiprocessor OS Kernel. Technical Report CUCS-005-91, Computer Science Department, Columbia University, 1991.
[11] J. M. Mellor-Crummey. Concurrent Queues: Practical Fetch-and-Φ Algorithms. TR 229, Computer Science Department, University of Rochester, November 1987.
[12] J. M. Mellor-Crummey and M. L. Scott. Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors. ACM Transactions on Computer Systems, 9(1):21–65, February 1991.
[13] M. M. Michael and M. L. Scott. Correction of a Memory Management Method for Lock-Free Data Structures. Technical Report 599, Computer Science Department, University of Rochester, December 1995.
[14] S. Prakash, Y. H. Lee, and T. Johnson. A Non-Blocking Algorithm for Shared Queues Using Compare-and Swap. In Proceedings of the 1991 International Conference on Parallel Processing, pages II:68–75, 1991.
[15] S. Prakash, Y. H. Lee, and T. Johnson. Non-Blocking Algorithms for Concurrent Data Structures. Technical Report 91-002, University of Florida, 1991.
[16] S. Prakash, Y. H. Lee, and T. Johnson. A Nonblocking Algorithm for Shared Queues Using Compare-and-Swap. IEEE Transactions on Computers, 43(5):548–559, May 1994.
[17] R. Sites. Operating Systems and Computer Architecture. In H. Stone, editor, Introduction to Computer Architecture, 2nd edition, Chapter 12, 1980. Science Research Associates.
[18] J. M. Stone. A Simple and Correct Shared-Queue Algorithm Using Compare-and-Swap. In Proceedings Supercomputing ’90, November 1990.
[19] J. M. Stone. A Non-Blocking Compare-and-Swap Algorithmfor a Shared Circular Queue. In S. Tzafestas et al., editors, Parallel and Distributed Computing in Engineering Systems, pages 147–152, 1992. Elsevier Science Publishers.
[20] H. S. Stone. High Performance Computer Architecture. Addison-Wesley, 1993.
[21] R. K. Treiber. Systems Programming: Coping with Parallelism. In RJ 5118, IBM Almaden Research Center, April 1986.
[22] J. Turek, D. Shasha, and S. Prakash. Locking without Blocking: Making Lock Based Concurrent Data Structure Algorithms Nonblocking. In Proceedings of the 11th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, pages 212–222, 1992.
[23] J. D. Valois. Implementing Lock-Free Queues. In Seventh International Conference on Parallel and Distributed Computing Systems, Las Vegas, NV, October 1994.
[24] J. D. Valois. Lock-Free Data Structures. Ph. D. dissertation, Rensselaer Polytechnic Institute, May 1995.
[25] R. W. Wisniewski, L. Kontothanassis, and M. L. Scott. Scalable Spin Locks for Multiprogrammed Systems. In Proceedings of the Eighth International Parallel Processing Symposium, pages 583–589, Cancun, Mexico, April 1994. Earlier but expanded version available as TR 454, Computer Science Department, University of Rochester, April 1993.
[26] R. W. Wisniewski, L. I. Kontothanassis, and M. L. Scott. High Performance Synchronization Algorithms for Multiprogrammed Multiprocessors. In Proceedings of the Fifth ACM Symposium on Principles and Practice of Parallel Programming, Santa Barbara, CA, July 1995.














 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









