





1创建分区
A、单分区建表语句:
hive> create table day_table(id int,
> content string)
> partitioned by (dt string)
> row format delimited foelds terminated by ',';【单分区表,按天分区,在表结构中存在id,content,dt三列;以dt为文件夹区分】
B、双分区建表语句:
hive> create table day_hour_table(id int,
> content string)
> partitioned by (dt string,hour string)
> row format delimited foelds terminated by ',';【双分区表,按天和小时分区,在表结构中新增加了dt和hour两列;先以dt为文件夹,再以hour子文件夹区分】
注意:在创建 删除多分区等操作时一定要注意分区的先后顺序,他们是父子节点的关系。分区字段不要和表字段相同。
2.添加表里面的分区
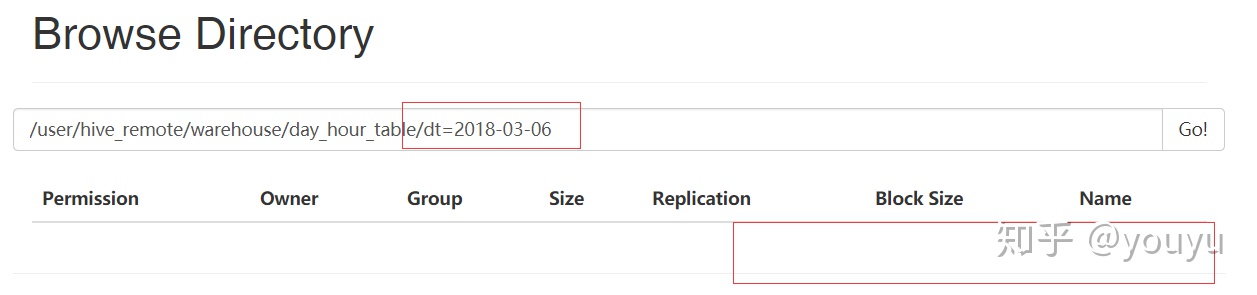
hive> alter table day_hour_table add partition (dt='2008-02-08', hour='07');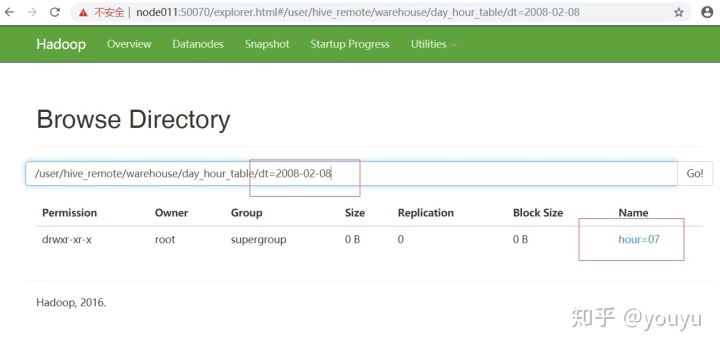
3.删除分区
hive> alter table day_hour_table drop partition (dt='2008-02-08',hour='07');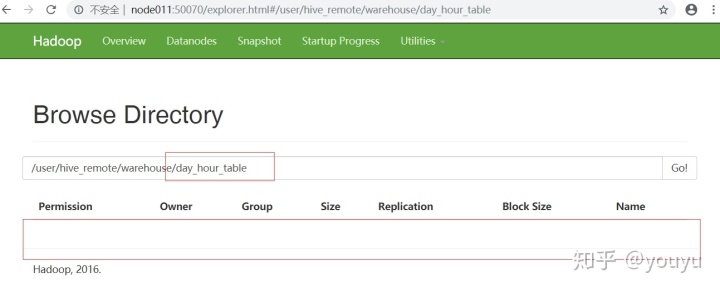
4.数据加载进分区中
语法:LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1,partcol2=val2 ...)]
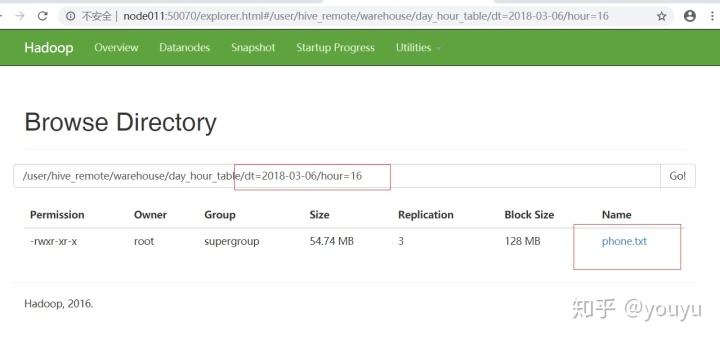
hive> load data local inpath '/test01/phone.txt' into table day_hour_table
> partition (dt='2018-03-06',hour='16');当数据被加载至表中时,不会对数据进行任何转换。Load操作只是将数据复制至Hive表对应的位置。数据加载时在表下自动创建一个目录基于分区的查询的语句:SELECT day_table.* FROM day_table WHERE day_table.dt >= '2018-03-06';
5.查看分区语句
hive> show partitions day_hour_table;
OK
dt=2018-03-06/hour=16
Time taken: 0.233 seconds, Fetched: 1 row(s)
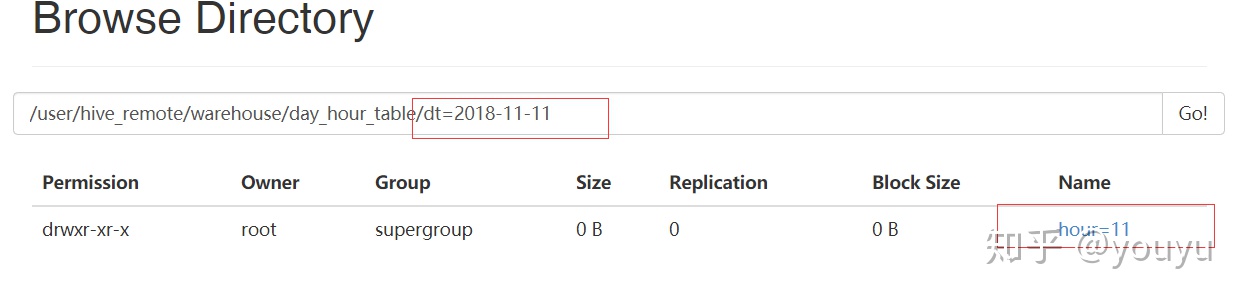
hive> 6.重命名分区
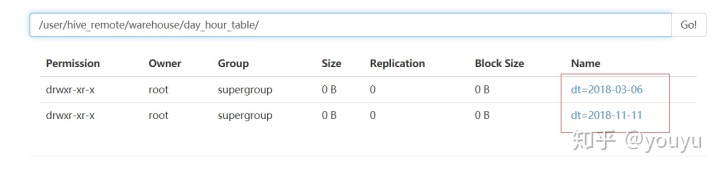
hive> alter table day_hour_table partition(dt='2018-03-06',hour='16') rename to
> partition (dt='2018-11-11',hour='11');
OK
Time taken: 0.596 seconds
hive>
7.动态分区--注意外部表
1.创建文件 a.txt,随便写入数据
aaa,us,ca
aaa,us,cb
bbb,ca,bb
bbb,ca,bc
2.创建表并加载数据
1>内部表加载
hive>和 create table t1(
> name string,
> cty string,
> st string)
> row format delimited fields terminated by ',';
OK
Time taken: 1.199 seconds
hive> load data local inpath '/test01/a.txt' into table t1;
Loading data to table default.t1
Table default.t1 stats: [numFiles=1, totalSize=40]
OK
Time taken: 0.85 seconds
hive> select * from t1;
OK
aaa us ca
aaa us cb
bbb ca bb
bbb ca bc
Time taken: 1.357 seconds, Fetched: 4 row(s)
注意:删除内部表2.外部表
hive> create external table t3(
> name string,cty string,st string)
> row format delimited fields terminated by ',';
hive> load data local inpath '/test01/a.txt' into table t3;区别:删除内部表和外部表的区别
hive> drop table t1;
OK
Time taken: 1.164 seconds
hive> drop table t3;
OK
hive> select * from t3;
FAILED: SemanticException [Error 10001]: Line 1:14 Table not found 't3'
hive>
删除t1表以后(如下图),内部表是删除,元数据+源数据
外部表删除, 元数据删除
元数据:指文件的名字,时间,大小,属性值
源数据:指文件的存储的数据。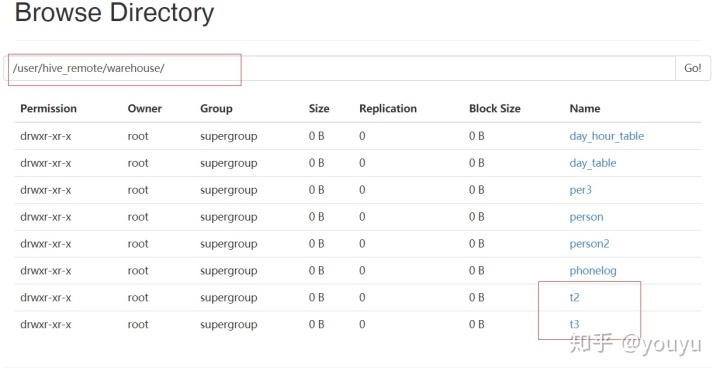
4.接着动态分区
1.参数配置
hive.exec.dynamic.partition
是否开启动态分区功能,默认false关闭。
使用动态分区时候,该参数必须设置成true;
hive> set hive.exec.dynamic.partition=true; hive.exec.dynamic.partition.mode
默认值:strict
动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。
hive> set hive.exec.dynamic.partition.mode=nonstrict;hive.exec.max.dynamic.partitions.pernode
默认值:100
在每个执行MR的节点上,最大可以创建多少个动态分区。
该参数需要根据实际的数据来设定。hive.exec.max.dynamic.partitions
默认值:1000
在所有执行MR的节点上,最大一共可以创建多少个动态分区。hive.error.on.empty.partition
默认值:false
当有空分区生成时,是否抛出异常。
一般不需要设置。创建b.txt文件
1,zs1,112,us
2,zs2,122,sh
3,zs3,132,cq
4,zs4,142,us
5,zs5,152,sh
6,zs6,162,cq
7,zs7,142,us1
8,zs8,152,sh
9,zs9,162,cq1.临时表:
hive> create table t7(id int,name string,age int,address string)
> row format delimited fields terminated by ',';
hive> load data local inpath '/test01/b.txt' overwrite into table t7;
hive> select * from t7;
OK
1 zs1 112 us
2 zs2 122 sh
3 zs3 132 cq
4 zs4 142 us
5 zs5 152 sh
6 zs6 162 cq
7 zs7 142 us1
8 zs8 152 sh
9 zs9 162 cq
Time taken: 0.166 seconds, Fetched: 9 row(s)set hive.exec.dynamic.partition=true;
将严格模式改为非严格模式:
set hive.exec.dynamic.partition.mode=nonstrict
2.动态表
create table t9(id int, name string,age int)
partitioned by (address string) row format delimited fields terminated by ',';3.执行
from t7
insert overwrite table t9 partition(address)
select id,name,age,address distribute by address;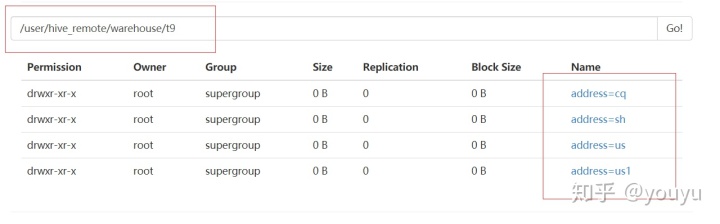
操作命令:
hive> show tables;
查看 存在的表
hive> set;
查看可以配置的命令













 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









