






 本文介绍了Hive的四种优化模式:本地模式、并行模式、严格模式和Uber模式,以提高小任务执行速度、并行处理、防止不良查询及优化小作业。这些模式有助于提升Hive查询效率和资源利用率。
本文介绍了Hive的四种优化模式:本地模式、并行模式、严格模式和Uber模式,以提高小任务执行速度、并行处理、防止不良查询及优化小作业。这些模式有助于提升Hive查询效率和资源利用率。
Hive和MapReduce中拥有较多在特定情况下优化的特性,如何利用好相关特性,是Hive性能调优的关键。本文就介绍那些耳熟但不能详的几种Hive优化模式。
一、本地模式
当一个MapReduce任务的数据量和计算任务很小的时候,在MapReduce框架中Map任务和Reduce任务的启动过程占用了任务执行的大部分时间,真正的逻辑处理其实占用时间很少,但是给用户的感受就是:很小的任务,同样执行较长的时间。比如对一张码表进行计算,总时间可能接近1~2分钟,这个对于用户来说,感受很差。
那么在0.7版本之后,Hive引入了本地模式,那么对于小任务的执行,Hive客户端不再需要到Yarn上申请Map任务和Reduce任务,只需要在本地进行Map和Reduce的执行,大大的加快了小任务的执行时间,通常可以把分钟级别任务的执行时间降低秒级。
参数设置:
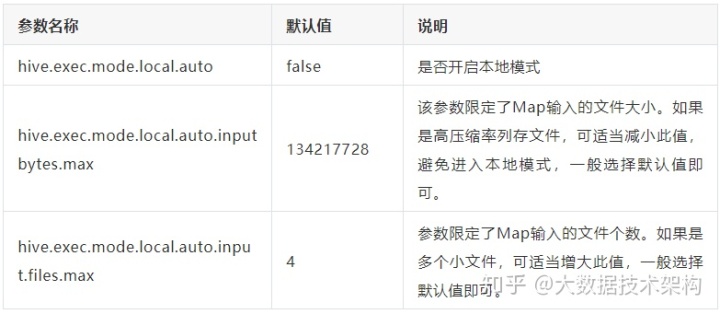
实际测试中,使用本地模式之后,对于小表的计算查询能从34秒减少到2秒。
二、并行模式
Hive的Parallel特性使得某些任务中的stage子任务以并行执行模式同时执行,相对于一直串行执行stage任务来说有效的提升资源利用率。
Parallel特性主要针对如下几种情况:
- 多个数据表关联
- 插入多个目标表
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3162
3162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









