






Hive 支持通常的 SQL JOIN 语句,但是只支持等值连接,不支持非等值连接。
意思就是只能join1.id=join2.id不可以是join1.id!=join2.id或者join1.id>join2.id之类的
在hive中,关联有4种方式:
内关联:join on
左外关联:left join on
右外关联:right join on
全外关联:full join on
另外还有一种可实现hive笛卡儿积的效果(hive不支持笛卡儿积): 在on后面接为true的表达式,如on 1=1(需先设置非严格模式:set hive.mapred.mode=nonstrict);
如我有两个表:join1和join2,如下
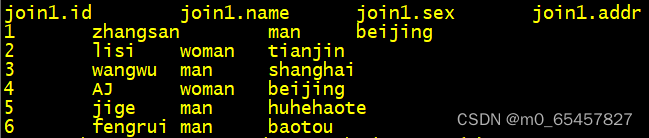
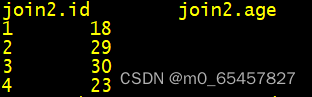
内关联:
select * from jion1 join join2 on jion1.id = jion2.id;
通常我们可以通过取别名的方式来进行关联,选取我们想要的字段,如:
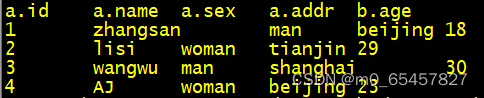
select a.id,a.name,a.sex,a.addr,b.age from join1 a join join2 b on a.id=b.id;
作用:将表1和表2的字段id相同的内容 关联到一个表里。
效果如下:
左外连接:
select * from jion1 left join join2 on jion1.id = jion2.id;
作用:以join左边的表为标准进行连接(即保留左边表的字段值,右边表不符合on条件的用null表示)。
效果如下:

右外连接:
select * from jion1 right join join2 on jion1.id = jion2.id;
作用:以join右边的表为标准进行连接(即保留右边表的字段值,左边表不符合on条件的用null表示)。
效果如下:

全外连接:
select * from jion1 full join join2 on jion1.id = jion2.id;
作用:两个表连接,表留所有字段的值,不符合on条件的用null表示。
效果如下:
















 5626
5626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









