






有时看到好的文章,想要摘录(照搬)局部或全部文字,可它是PDF文件,这时就需要转换成可编辑的word。
一般来说有几种通用的方式:
- 将整个PDF文件通过工具转换成word文件,此类工具如smallPDF、ilovePDF等在线网站。但基本都是付费的,还有一部分是手机上的软件,比如小程序pdf转成word(没用过小程序的可以试试,还挺方便,小巧易用)

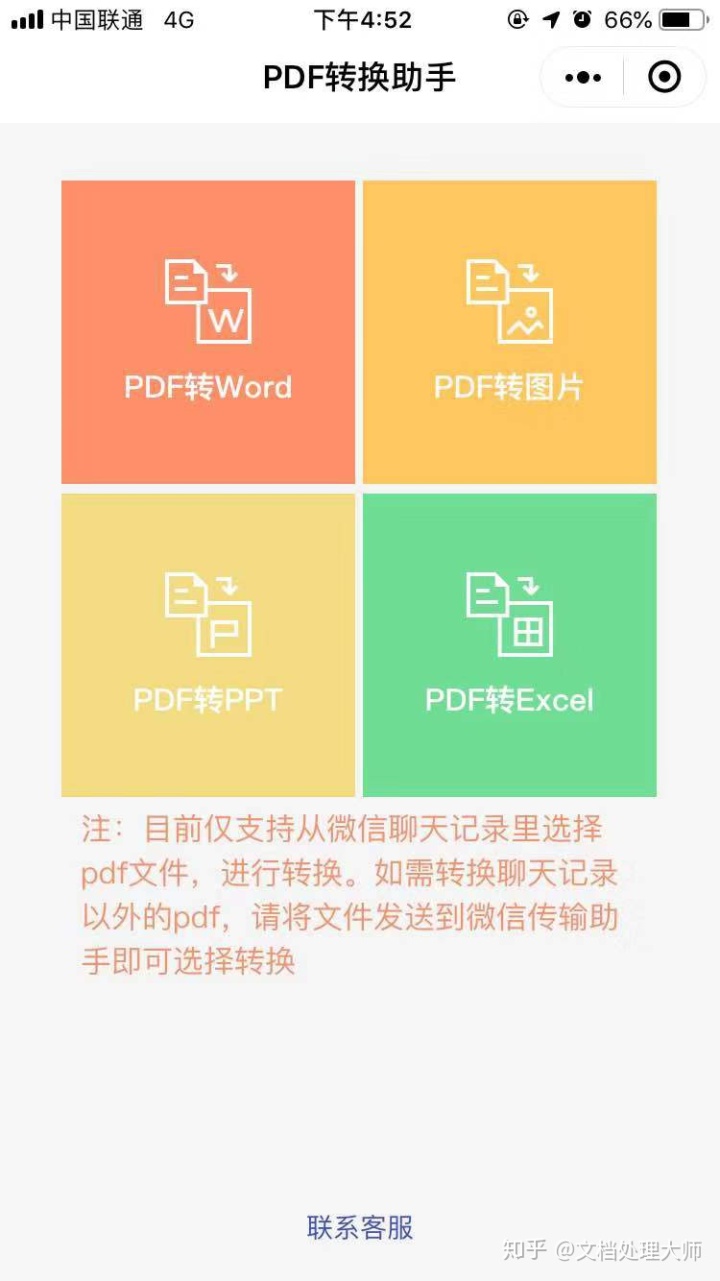
但这部分软件其实都是有利有弊的,他的问题在于:无法保证100%的准确率,当然这个无可厚非,毕竟都是机器转换。而且pdf里面的内容复杂, 有的是图片,有的是表格。对校核转换之后的准确率要求也比较高,后面转换本身可能要花点修改时间;
2、比如,如果你的pdf是扫描件或者图片形式的,那上面直接转换的方法可就不管用了。他只适合是文字类型的,如果不是的话,即使转换成了word,那里面还是图片格式。还是不能编辑的。
那要提取这种类型pdf中的图片文字,无法用直接转换的方式,而要用其它途径,如图像文字识别(亦称光学文字识别)(Optical Character Recognition,OCR),其可将图片中的字符翻译成文字,是当前比较热门的一种算法,涉及到机器学习。这里也可以给你推荐个微信小程序:
识字传图神器 | 知晓程序minapp.com

这就是利用到机器学习将图片上的文字识别出来,可以复制也可以转成word。
但它的准确程度是和你图片的质量有关的, 就是图片质量越清晰,那识别的越准确。始终还是绕不开准确率的问题。就我个人体验来说,上面这个小程序准确率还是比较高的。和开发者沟通过,说是用的百度AI的。也就能理解了。
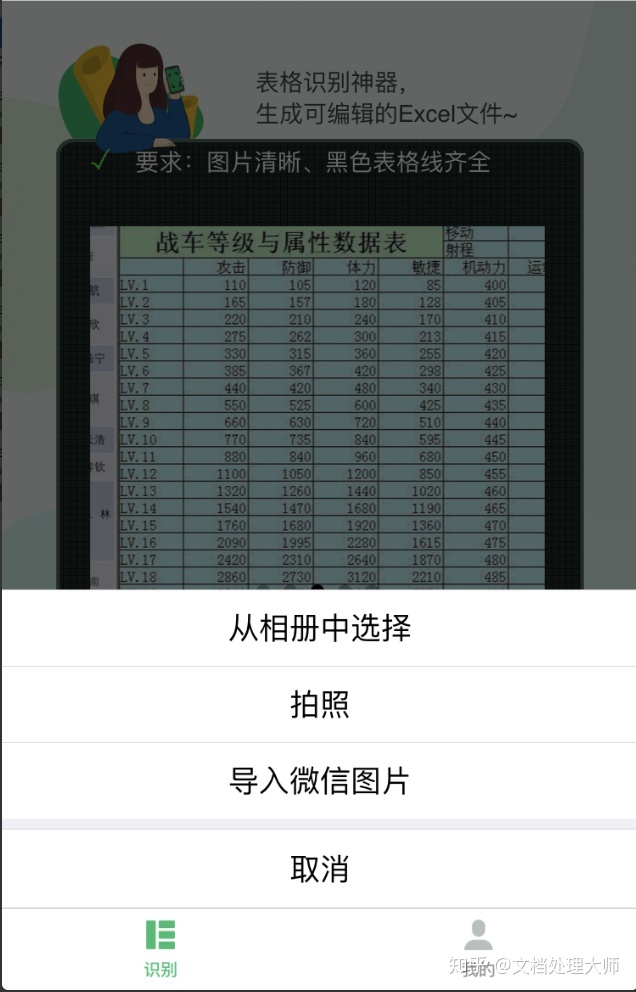
当然了,有的人的pdf里面是一些表格图片,这类图片也是不能用文字OCR,用的是表格OCR。就是专门识别表格图片的。自动给你生成表格。简直就是解放双手的利器!!再也不用加班了!推荐给你使用。一般人我不告诉他。
表格识别君 | 知晓程序minapp.com
那针对非扫描版PDF,不加密。最传统的方式也有,下面介绍一些。
就是——直接从文件中拷贝文字至word中。不用担心准确率的问题,但如果你有过类似的经历,会发现拷至word后经常排版很丑,当然也很慢。效率低。尤其是对于使用双栏分布的PDF文件。
(针对图片形式的PDF文件,方式一失效)

(双栏分布的PDF)
本文将介绍方式3的小技巧,帮助提高工作效率。
针对“从PDF拷贝文字至word中,如何处理更高效问题”,传统的有下面两种方法。
方法一
常用:巧用替换功能
从某些PDF拷出来后会发现有很多的段落标记(即那些回车符号)。

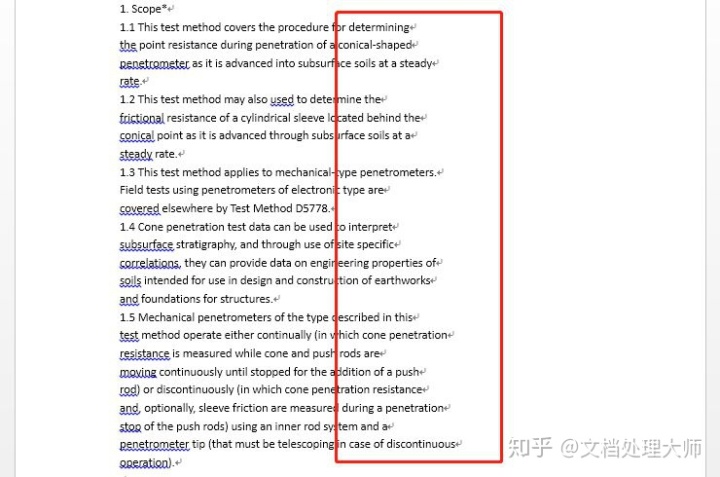
对于这一类型的排版处理,当然你可以说“我比较怀旧,想一个一个删”,未尝不可,不过你可以想象手动删除的步骤有多繁琐:
按下“delete”键→下移光标→再按下“delete”键→重复以上操作……
如果遇到英文,考虑到英文单词间的空格,步骤则变成:
按下“delete”键→下移光标→敲空格→再按下“delete”键→重复以上操作……
如果文字行数不多还好,如果行数在100行以上,那就……展示灵活手速的时候到了。

(图片来源于网络)
其实这种批量处理的工作,借助word自带“替换”功能便能很快处理。
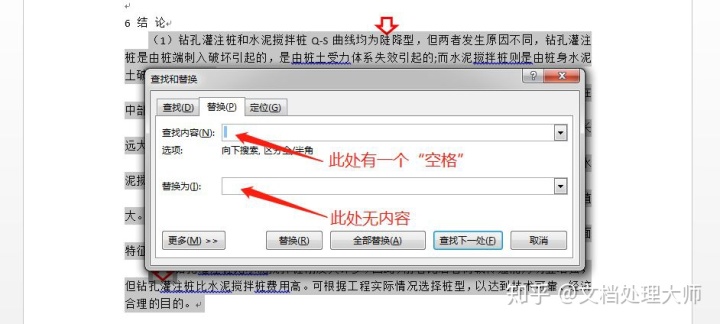
Step1:按Ctrl+H召唤“替换”界面,在【查找内容】一栏选择“段落标记”,或者手动输入“^p”,而在【替换为】一栏无内容(如果是针对英文,由于单词之间或符号与单词之间存在空格,则此处输入1个空格)。

Step2:完成后得到如下结果。如果所选文字含有多个段落,则此时需要手动分段,或者可在step1时分别针对单独段进行替换。但我觉得前者更快,因为只是“浏览一眼”→“敲回车”即可。

处理结果如下两张图。


方法二
更高效:巧用Chrome浏览器
Chrome浏览器很好用,小巧快速,而且由于Chrome浏览器内置了PDF文档查看器,可以浏览PDF文件。
Step1:用Chrome浏览器打开PDF文件。右键单击PDF文件,在打开方式一栏选择Chrome。

Step2:用同样的方式,对所需要的文字部分进行Ctrl+C拷贝,Ctrl+V粘贴至word中,会发现中间的段落标记都没有出现。这就相当于方法一中所有段落标记被替换掉后的结果,只需要简单的手工分段即可。所以相比而言,方法二少了一个“替换”步骤。


(从Chrome中直接拷出来的结果)
Step3:分段完成后稍微排一下版,会发现有个问题:某些字之间有1个空格(如红色箭头所示)。原来Chrome用空格取代了段落标记。如果你觉得空格无伤大雅,不影响阅读或者使用,那至此为止已经完成了所有操作,可以收工了。如果你仍觉得不行,再加一个步骤。但对于英文,不存在“多1个空格”的问题,所以用Chrome复制英文有奇效。

Step4:这个步骤很简单,原理还是“替换”功能。一次性选中需修改的文字段落,快捷键Ctrl+H召唤“替换”界面,简单设置即可点击“全部替换”。
最终处理结果如下。

End,希望能对你有点帮助,分享一下,让更多的人获益吧~

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









