





为什么需要分页:
试想一下,你看一本从开头到结尾,没有章节名称,没有句号的书,一打开书,映入眼帘的密密麻麻的文字,相信你第一感官就是头皮发麻吧,哪怕这本书写的在好,估计你也不会去提起读取它的欲望。
数据也是这样,当大量数据没有进行有规则的划分,一股脑的展示,先不考虑带宽、效率、和浏览器页面的展示,光是用户体验就是0分,哪怕你的数据在有价值也是白搭,由此可见分页的必要性
分页的作用:
1, 在网页进行大量数据展示的时候,可以通过分页技术来将数据分成若干页面展示
2, 每次请求查询,不需要查询所有,通过定制页码或者别的方式,只需要查询数据的一 部分,将数据看作一本书,通过页码可以跳转可见数据,直到找到自己想要的
3, 分页查询可以减少带宽的使用,提高访问效率
分页的三个基本特征:
1, 每页有几条记录
2, 当前页号
3, 记录总数totalCount
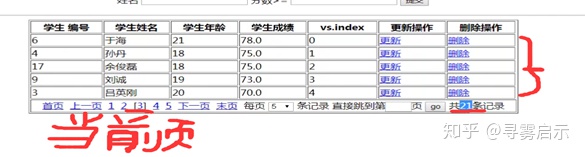
知道了记录总数、每页的数据条数,当前页数,那么分页的页数、上一行、下一行等等一系列操作都可以在这基础上进行演化。
从哪分页:
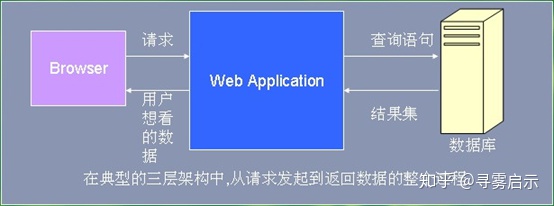
由上可知,一个数据的请求过程,浏览器向web服务器发送请求,服务器在像数据库发送查询语句,数据库返回结果集,web服务器在将结果集返回给浏览器
这三者之间都是通过网站进行数据传输,所以理所当然的,传输的数据越小,速度越快,所以我们可以先将浏览器给排除了,剩下的web服务器和数据库呢?
从上图来看,如果等数据库将数据传输给web服务器,web服务器在进行数据的过滤,那么这无疑是浪费效率,所以最好是就在数据库中进行分页,因为数据库的技术成熟完善,只需要编写相应的sql语句即可,用户每次翻页的时候浏览器发送请求,数据库只需要查询相应大小的数据返回
所以分页方式大致分为了两种:
1, 逻辑分页(内存分页)
这种分页方式,通过内存去实现,实现原理很简单,就是在第一次查询的时候
将数据库中的数据全部查询出来,存放在一个容器中,假设这个容易为一个list集合,我们每次翻页的时候,只需要从集合中去获取指定的数据条数即可,
优点:
操作简单,因为不需要每次都查询数据库,所以翻页比较快
缺点:
第一次查询比较慢,因为需要查询所有的数据
如果数据量大的话,可能造成数据溢出
2. 物理查询(数据库分页)
这种分页方式,在数据库来完成分页,mysql依赖于limit,Oracle通过子查询
每次翻页都从数据库中查询指定的条数
优点:
每次只查询一部分数据进行查询,不必担心内存溢出
缺点:
每次翻页都需要访问数据库,相对来说,效率没有物理查询快
物理分页的大致步骤:
(通过sql进行分页)
需要两个基础的数据:
CurrentPage=1 ;当前页数 因为通常第一次显示的页数都是第一页
Pagesize=10 ;每页多少数据 这里默认是10条
通过sql查询(两条sql)
第一条sql:查询符合条件的结果(totalCount) (返回数据的总数)
Select count(*) from 表名
第二条sql:查询符合条件的结果集 (返回指定区域的数据)
1,先将表数据通过ORDER BY进行排序
2,Select *from 表名 [where 条件] limit beginindex,pageSize;
Beginindex:从哪一条数据的索引位置开始截取(一般开头以0结尾)
Beginindex=(CurrentPage-1)* pageSize (计算开始截取的位置)
pageSize:每次截取多少条数据
后台计算:
beginPage:1: 首页/第一页,默认是1
prevPage:上一页
nextPage:下一页
totalPage:总页数/末页
totalPage= totalCount%pageSize==0?totalCount% pageSize:(totalCount%pageSize)1 ;
prevPage= CurrentPage-1>=1? CurrentPage-1:1 ;
nextPage= CurrentPage+1<= totalPage? CurrentPage+1: totalPage;















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









