一、背景
地图组的同学有一个需求需要在bq上使用一个自定义UDF,能够将经纬度转换为对应的行政区域,UDF出入参如下所示:
hive>select MatchDistrict("113.2222,24.33333", "formattedAddress")hive>中华人民共和国-广东省-肇庆市-四会市二、预研方案 初步预研得到如下两种方案:
地图组提供转换服务,在自定义UDF中访问该服务。 将转换方法封装在UDF中,直接UDF转换为行政区域。 两种方案的对比如下:
方案 好处 坏处 方案1 封装简单,实现快。UDF的jar包更小。 依赖外部服务,服务宕机则会造成UDF不可用。网络有开销,比本地计算性能要低。 方案2 性能高。无外部依赖。 实现复杂。有技术难点,需要考虑对离线资源处理。
对于一个平台来说,
稳定 和
性能 是首要考虑的因素,方案2相对方案1来说,没有外部依赖,没有网络IO开销,性能也更好,所以选择方案2。
三、实现方式
四、技术难点 地图组提供了对应的转换方法GeoRTreeData.java,
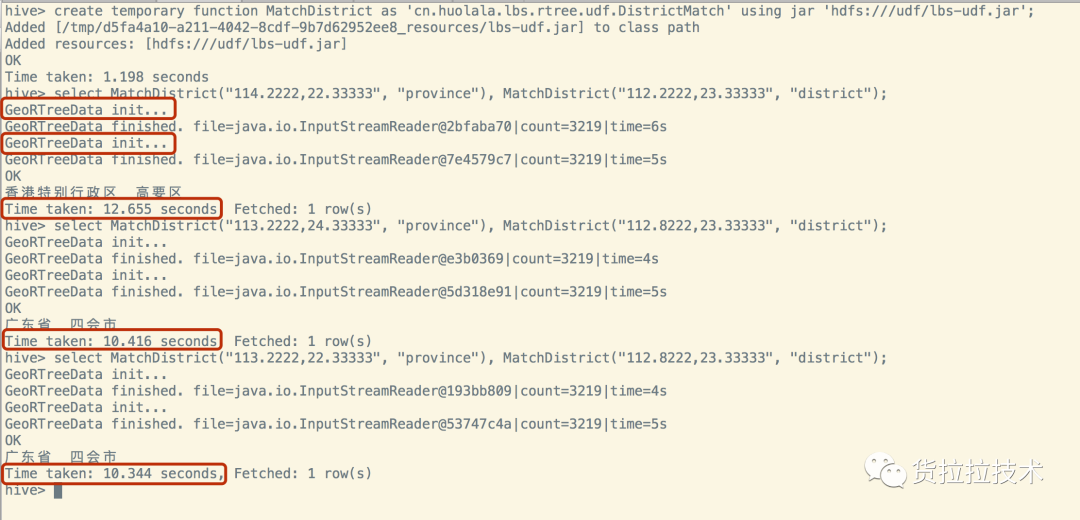
但需要加载一个外部资源lbs_geo_data.json ,该资源大小为157.4MB,本地加载耗时在5s左右。遇到的主要问题是:如下图所示,如果一个查询语句中使用2次该UDF,则总耗时在10s以上,产生问题的原因是
每次使用该UDF都需要初始化一次lbs数据 ,
加载资源占用了大量时间,而且数据都一样,重复加载其实是完全没有必要的 。在BQ对大数据查询使用该UDF的频率高,如果重复加载资源,则性能无法满足需求。
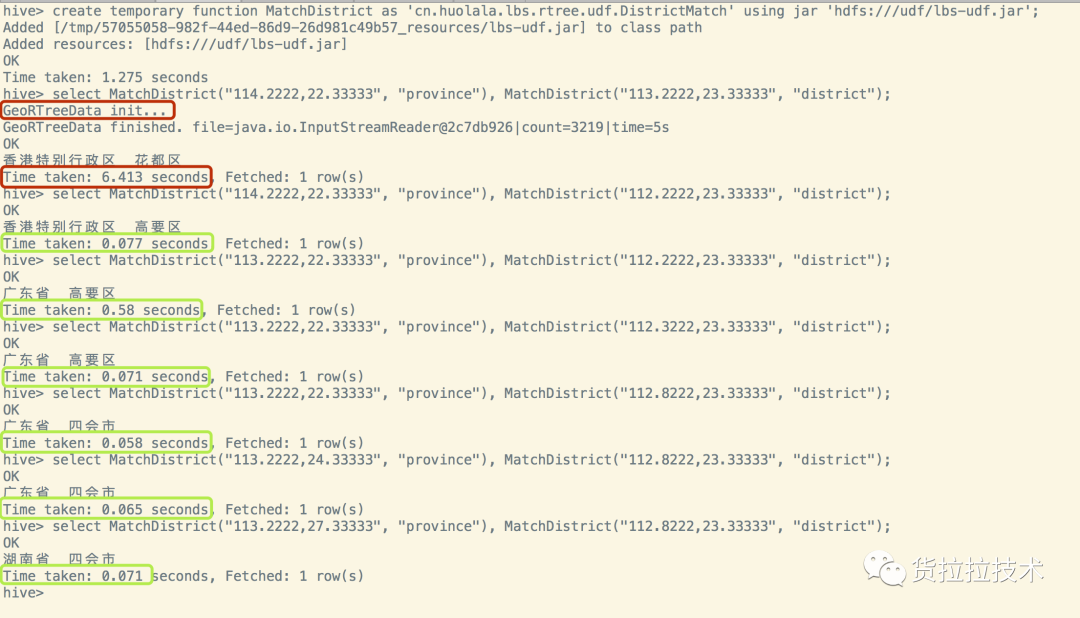
五、最终效果 最终优化效果如下图,只在
首次调用 UDF时加载资源,后续调用UDF不再加载资源,第一次查询耗时6s,后续每次耗时在
70ms 左右,相当于查询性能提升
约140倍 ,最终查询3亿条数据只要30+秒。
六、解决方法 在UDF类中定义GeoTreeData为static对象,在initialize中判断资源是否已经加载到GeoTreeData中,如果未加载,则加载资源,否则不加载资源。代码如下,最终实现起来比较简单,但原理相对要复杂些。
public class DistrictMatch extends GenericUDF { public static GeoRTreeData rTreeData; private static void initRTreeData() { InputStreamReader is = new InputStreamReader(DistrictMatch.class.getClassLoader() .getResourceAsStream("lbs_geo_data.json")); rTreeData = new GeoRTreeData(); rTreeData.init(is); } @Override public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException { if (arguments.length != 2) { throw new UDFArgumentException("method need 2 params"); } if (!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)) { throw new UDFArgumentException("except String, but got:" + arguments[0].getTypeName()); } if (!arguments[1].getCategory().equals(ObjectInspector.Category.PRIMITIVE)) { throw new UDFArgumentException("except String, but got:" + arguments[0].getTypeName()); } if (rTreeData == null) { initRTreeData(); } return PrimitiveObjectInspectorFactory.writableStringObjectInspector; } }七、理论支撑 接下来将对上述解决方案的原理进行阐述,主要从3个方面进行介绍:
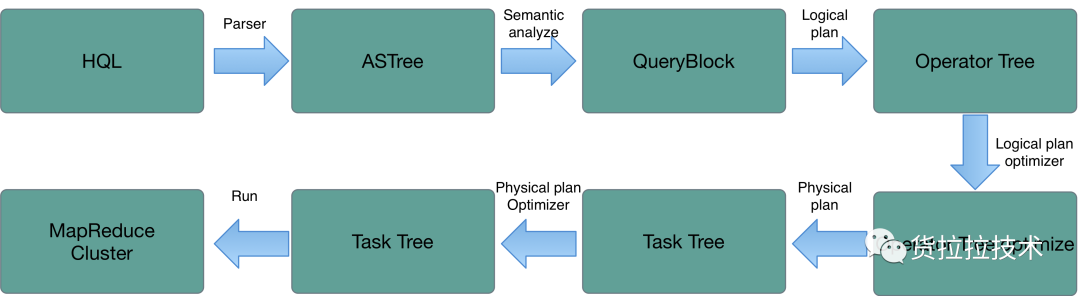
HQL执行的流程:HQL是如何最终变成MapReduce任务并运行的。 Generic UDF加载过程:UDF的初始化过程及initialize的使用。 jvm中static属性的加载:为什么要使用static关键字。 1. 执行HQL的流程 因为HiveSQ的执行最终是成一个或多个MapReduce任务,所以UDF最终是被MapReduceJob加载,先了解HQL到MapReduce的转过过程(如果通过jdbc访问HiveServer2,则必须是PermanentUDF)。如下图所示:
转化步骤解释:
Parser: Antlr定义的语法规则,完成SQL词法、语法解析,将SQL转化为抽象语法书ASTree。 Semantic analyze:遍历ASTree,抽象出查询的基本组成单元QueryBlock。 Logical plan:遍历QueryBlock,翻译为执行操作树OperatorTree。 Logical plan optimizer:逻辑层优化器进行OperatorTree转换,大部分逻辑层优化器通过变换OperatorTree,合并操作符,达到减少MapReduce Job(② ),减少shuffle数据量的目的(①)。各种优化器如下表所示:
名称作用
②SimpleFetchOptimizer 优化没有GroupBy表达式的聚合查询 ②MapJoinProcessor MapJoin,需要SQL中提供hint,0.11版本已不用 ②BucketMapJoinOptimizer BucketMapJoin ②GroupByOptimizer Map端聚合 ①ReducesSinkDeDuplication 合并线性的OperatorTree中partition/sort key相同的reduce ①PredicatePushDown 谓词前置 ①CorelationOptimizer 利用查询中的相关性,合并有相关性的Job,HIVE-2206 ColumnPruner 字段剪枝
表格中①的优化器均是一个Job干尽可能多的事情/合并。②的都是减少shuffle数据量,甚至不做Reduce。CorrelationOptimizer优化器非常复杂,都能利用查询中的相关性,合并有相关性的Job,参考 Hive Correlation Optimizer。
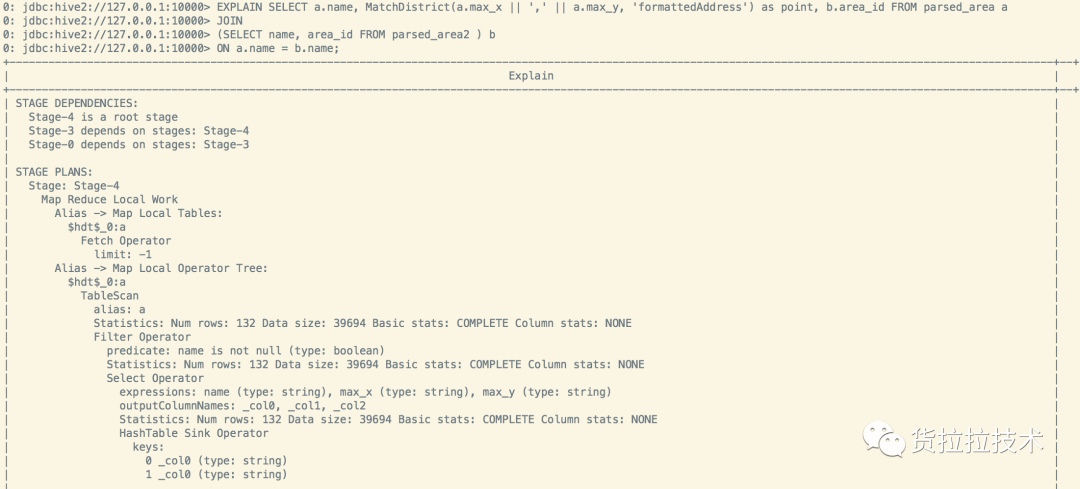
Physical plan:遍历OperatorTree,翻译为MapReduce任务。 Physical plan optimizer:物理层优化器进行MapReduce任务的变换,生成最终的计划。 Run:在Hadoop集群上运行对应的MapReduce任务。 接下来通过explain命令查看一个join任务最终执行的计划,对应的SQL如下面的代码, 很简单的一个join任务,关联了两张表a,b,然后选取了a,b两张表的部分字段,最终生成的plan如下图所示。 EXPLAIN SELECT a.name, MatchDistrict(a.max_x || ',' || a.max_y, 'formattedAddress', 'wgs84') as point, b.area_id FROM parsed_area a JOIN (SELECT name, area_id FROM parsed_area2 ) b ON a.name = b.name;这里分成了3个Stage, Stage4–>Stage3–>Stage0逐级依赖。有2个MapReduce任务:Stage4和Stage3, Stage4是本地MapReduce任务。Stage4任务如下,经过4个步骤,最终从a表选出得到3列并输入到内存HashTable中,注意这里是3列,
没有 将max_x和max_y进行MatchDistrict UDF操作。
再看下Stage3的流程,由于没有Group By等聚合指令且表的数据量不是很大,所以Stage3也只有Map任务(在MapReduce中的join有两种,一种是Repartition连接,另外一种是Replication连接,Replication连接只有Map任务,执行效率高于Repartition连接,在Hive0.11版本之后,会根据文件大小来将Repartition连接转换为Replication连接,所以这里使用的是Replication的普通Map连接)。大致流程是先扫描b表,选取其中的name和area_id字段,然后和Stage4的HashTable进行join,在选取join之后需要的字段,最终输出到HDFS。注意如图中标红的Select Operator中,在Stage3中仍然没有直接使用MatchDistrict计算出最终结果,只是将参数作为一个Array进行了输出,这里判断是在File Output Operator中调用了UDF(MathDistrict)。
最后Stage0则是从HDFS中读取所需要的数据并返回。
2. Generic UDF加载过程 UDF全称是User Defined Function, HiveQL内置了较多的UDF,同时也支持用户上传jar包导入用户自定义的UDF。jar包导入到HDFS之后,可以通过如下命令创建UDF,UDF包括临时UDF和永久UDF。
CREATE TEMPORARY FUNCTION function_name AS class_name;CREATE FUNCTION [db_name.]function_name AS class_name [USING JAR|FILE|ARCHIVE 'file_uri' [, JAR|FILE|ARCHIVE 'file_uri'] ];
UDF在Hive的定义在org.apache.hadoop.hive.ql.udf包下,包括如下3中:
UDF(User-Defined Function):one-to-one row mapping upper substr 一行对一行的映射 UDAF:Aggregation(聚合) Many-to-one row mapping sum/min UDTF:Table-generating one-to-many lateral view explode() 对于UDF的加载可以分为两步来看, 1. 注册Generic UDF;2. 使用Generic UDF。
(1) 注册Generic UDF 注册UDF是将jar包定义的继承Generic UDF的类注册到Registry中,查看FunctionRegistry源码:
public static FunctionInfo registerTemporaryUDF( String functionName, Class> udfClass, FunctionResource... resources) { return SessionState.getRegistryForWrite().registerFunction( functionName, udfClass, resources);}
这里获取了Session的registry,这也印证了TemporaryUDF只在一个session中有效,同时也说明了Session的registry和永久UDF的registry是分开存放的,后面发现其实session的registry是一个单独的Map。继续查看Registry的registerGenericUDF方法:
public FunctionInfo registerGenericUDF(String functionName, Class extends GenericUDF> genericUDFClass, FunctionResource... resources) { validateClass(genericUDFClass, GenericUDF.class); FunctionInfo fI = new FunctionInfo(isNative, functionName, ReflectionUtils.newInstance(genericUDFClass, null), resources); addFunction(functionName, fI); return fI;}
流程是先反射了一个genericUDF的实例,然后调用addFunction方法加入到registry中,addFunction是put实例到map中,这里就看下ReflectionUtils.newInstance的代码:
public static T newInstance(Class<T> theClass, Configuration conf) { Object result; try { Constructor meth = (Constructor)CONSTRUCTOR_CACHE.get(theClass); if (meth == null) { meth = theClass.getDeclaredConstructor(EMPTY_ARRAY); meth.setAccessible(true); CONSTRUCTOR_CACHE.put(theClass, meth); } result = meth.newInstance(); } catch (Exception var4) { throw new RuntimeException(var4); } setConf(result, conf); return result;}
ReflectionUtils会将已经反射的class的构造方法存入缓存,并调用了构造函数的newInstance方法得到真正的UDF实例。而当前还是在注册Generic UDF阶段,所以从执行CREATE TEMPORARY FUNCTION这行指令的时候,就已经生成了Generic UDF实例。
(2)使用Generic UDF Hive在解析语法树之后,最终会为树中的每个节点生成一个ExprNodeDesc对象,存放该Node所具有的操作信息。每个ExprNodeDesc有对应的ExprNodeEvaluator进行最终的节点的任务执行。ExprNodeEvaluator持有UDF对象,ExprNodeEvaluator在initialize方法中会调用UDF的initialize方法。那 ExprNodeEvaluator的initialize是何时调用的呢?查看源码如下, 这里以FilterOperator为例,Operator在processOp方法中会调用ExprNodeEvaluator的initialize方法,继续向上追溯则会到Operator Tree遍历的forward方法中,就不继续深究了。
public FilterOperator() { super(); consecutiveSearches = 0;} ... ...@Overridepublic void processOp(Object row, int tag) throws HiveException { ObjectInspector rowInspector = inputObjInspectors[tag]; if (conditionInspector == null) { conditionInspector = (PrimitiveObjectInspector) conditionEvaluator .initialize(rowInspector); }
通过注释也会发现,Generic UDF的initialize针对每个对象只会调用一次,那是因为Operator Tree节点遍历只会有一次,所以Operator的processOp方法或者initializeOp也只会调用一次,调用过程如下图:
对于一个HIveSql任务,可以是MR任务,也可以是Tez任务和Spark任务,
实例化UDF的个数取决于本身task的数量 ,也就是进程的数量。同时也取决于UDF的使用次数(对应Operator Tree中的多个节点)。
task数记为n,一个SQL中UDF使用了m次,那么实例化个数为n*m 。回到最开始的lbs的加载数据的问题,通过分析不适合直接将加载lbs资源的动作放在initialize方法中了,因为initialize对于每个实例都会被调用,每个实例都需要初始化加载lbs数据,这个是没有必要的,可以通过static关键字让多个UDF对象公用一份lbs数据,initialize只去检测资源是否已经加载,未加载的时候再加载。
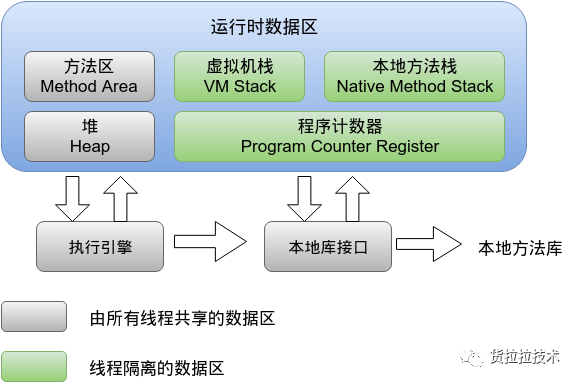
3. jvm中static属性的加载 首先看下jvm的内存模型:
其中静态变量存在方法区中,是所有线程共享的数据区,从而达到一个进程多个对象公用一份lbs数据的目的。另外一个问题是:可以在静态代码块中初始化lbs数据,也可以在initialize中初始化lbs数据,不过建议还是在initialize中初始化lbs数据,因为如下图所示,静态代码块在注册UDF的时候就会被调用,现实场景中注册了函数也不一定会用,所以放在initialize方法中懒加载会好一些。
其中静态代码块属性和构造函数调用的顺序如下:1、初始化父类的静态变量,静态代码块,初始化的顺序按照出现顺序。2、初始化子类的静态变量,静态代码块。3、初始化父类的成员变量。4、执行父类的构造函数。5、初始化子类的成员变量。6、构造代码块创建对象时执行。7、执行子类的构造函数。
八、横向扩展 后续在UDF中需要进行文件加载,网络资源请求等操作,可以预先将资源加载并存储为static对象,避免每次实例化加载。为什么不用static代码块,在加载类的时候就直接加载 GeoRTreeData:因为有可能create temporary function,但实际没调用, 则避免浪费空间
九、备注其他
在本地测试,发现hive的heap size设置为512MB的时候,加载UDF会出现OOM,设置hive的heap size为1G解决该问题, 其中hive的heap size不能超过hadoop设置的hadoop client(export HADOOP_CLIENT_OPTS=”-Xmx4096m $HADOOP_CLIENT_OPTS”)的Xms大小。 另外设置hadoop的单个节点的map使用内存大小使用如下配置: <property> <name>mapred.child.java.optsname> <value>-Xmx512mvalue> property>在MapReduce运行没有问题,但是在Tez引擎上运行出现各种奇妙的问题,在鹏哥的指导下,发现是依赖包的问题,解决方法是将hive-exec依赖相关的包不要打入到UDF的jar包中。 十、未来展望 Hive On Tez, Hive On Spark, UDAF,UDTF
十一、参考文献 https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-CreateFunctionhttps://cwiki.apache.org/confluence/display/Hive/HivePlugins#HivePlugins-DeployingJarsforUserDefinedFunctionsandUserDefinedSerDeshttps://blog.csdn.net/moon_yang_bj/article/details/31744381https://www.jianshu.com/p/660fd157c5ebhttps://www.cnblogs.com/nashiyue/p/5751102.html作者介绍:黄政(asce.huang),大数据专家







 转化步骤解释:
转化步骤解释:
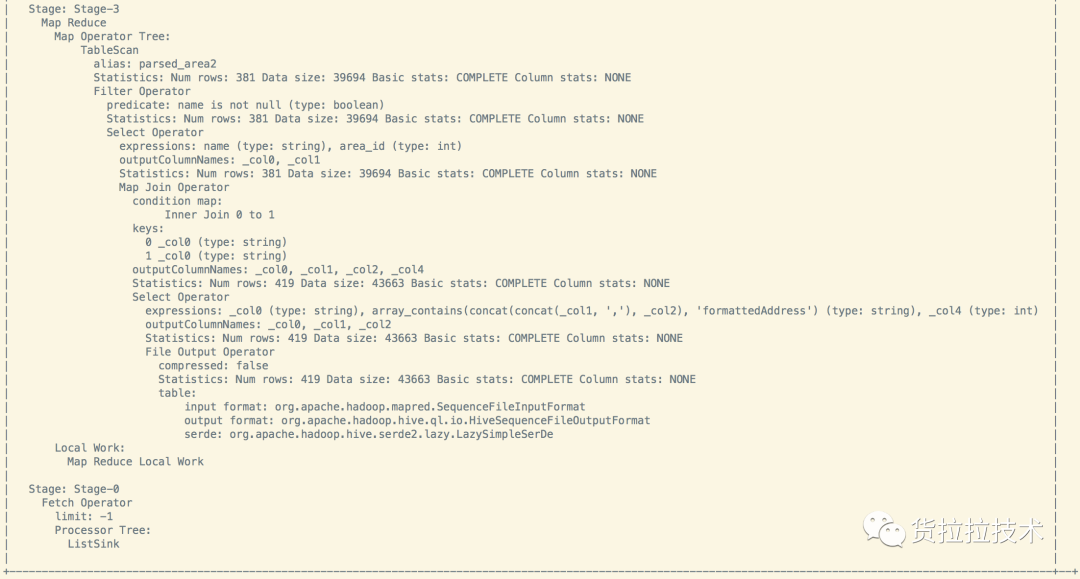 这里分成了3个Stage, Stage4–>Stage3–>Stage0逐级依赖。有2个MapReduce任务:Stage4和Stage3, Stage4是本地MapReduce任务。Stage4任务如下,经过4个步骤,最终从a表选出得到3列并输入到内存HashTable中,注意这里是3列,
没有将max_x和max_y进行MatchDistrict UDF操作。
这里分成了3个Stage, Stage4–>Stage3–>Stage0逐级依赖。有2个MapReduce任务:Stage4和Stage3, Stage4是本地MapReduce任务。Stage4任务如下,经过4个步骤,最终从a表选出得到3列并输入到内存HashTable中,注意这里是3列,
没有将max_x和max_y进行MatchDistrict UDF操作。
 再看下Stage3的流程,由于没有Group By等聚合指令且表的数据量不是很大,所以Stage3也只有Map任务(在MapReduce中的join有两种,一种是Repartition连接,另外一种是Replication连接,Replication连接只有Map任务,执行效率高于Repartition连接,在Hive0.11版本之后,会根据文件大小来将Repartition连接转换为Replication连接,所以这里使用的是Replication的普通Map连接)。大致流程是先扫描b表,选取其中的name和area_id字段,然后和Stage4的HashTable进行join,在选取join之后需要的字段,最终输出到HDFS。注意如图中标红的Select Operator中,在Stage3中仍然没有直接使用MatchDistrict计算出最终结果,只是将参数作为一个Array进行了输出,这里判断是在File Output Operator中调用了UDF(MathDistrict)。
再看下Stage3的流程,由于没有Group By等聚合指令且表的数据量不是很大,所以Stage3也只有Map任务(在MapReduce中的join有两种,一种是Repartition连接,另外一种是Replication连接,Replication连接只有Map任务,执行效率高于Repartition连接,在Hive0.11版本之后,会根据文件大小来将Repartition连接转换为Replication连接,所以这里使用的是Replication的普通Map连接)。大致流程是先扫描b表,选取其中的name和area_id字段,然后和Stage4的HashTable进行join,在选取join之后需要的字段,最终输出到HDFS。注意如图中标红的Select Operator中,在Stage3中仍然没有直接使用MatchDistrict计算出最终结果,只是将参数作为一个Array进行了输出,这里判断是在File Output Operator中调用了UDF(MathDistrict)。
 最后Stage0则是从HDFS中读取所需要的数据并返回。
最后Stage0则是从HDFS中读取所需要的数据并返回。
 对于一个HIveSql任务,可以是MR任务,也可以是Tez任务和Spark任务,
实例化UDF的个数取决于本身task的数量,也就是进程的数量。同时也取决于UDF的使用次数(对应Operator Tree中的多个节点)。
task数记为n,一个SQL中UDF使用了m次,那么实例化个数为n*m。回到最开始的lbs的加载数据的问题,通过分析不适合直接将加载lbs资源的动作放在initialize方法中了,因为initialize对于每个实例都会被调用,每个实例都需要初始化加载lbs数据,这个是没有必要的,可以通过static关键字让多个UDF对象公用一份lbs数据,initialize只去检测资源是否已经加载,未加载的时候再加载。
对于一个HIveSql任务,可以是MR任务,也可以是Tez任务和Spark任务,
实例化UDF的个数取决于本身task的数量,也就是进程的数量。同时也取决于UDF的使用次数(对应Operator Tree中的多个节点)。
task数记为n,一个SQL中UDF使用了m次,那么实例化个数为n*m。回到最开始的lbs的加载数据的问题,通过分析不适合直接将加载lbs资源的动作放在initialize方法中了,因为initialize对于每个实例都会被调用,每个实例都需要初始化加载lbs数据,这个是没有必要的,可以通过static关键字让多个UDF对象公用一份lbs数据,initialize只去检测资源是否已经加载,未加载的时候再加载。
 其中静态变量存在方法区中,是所有线程共享的数据区,从而达到一个进程多个对象公用一份lbs数据的目的。另外一个问题是:可以在静态代码块中初始化lbs数据,也可以在initialize中初始化lbs数据,不过建议还是在initialize中初始化lbs数据,因为如下图所示,静态代码块在注册UDF的时候就会被调用,现实场景中注册了函数也不一定会用,所以放在initialize方法中懒加载会好一些。
其中静态变量存在方法区中,是所有线程共享的数据区,从而达到一个进程多个对象公用一份lbs数据的目的。另外一个问题是:可以在静态代码块中初始化lbs数据,也可以在initialize中初始化lbs数据,不过建议还是在initialize中初始化lbs数据,因为如下图所示,静态代码块在注册UDF的时候就会被调用,现实场景中注册了函数也不一定会用,所以放在initialize方法中懒加载会好一些。
 其中静态代码块属性和构造函数调用的顺序如下:1、初始化父类的静态变量,静态代码块,初始化的顺序按照出现顺序。2、初始化子类的静态变量,静态代码块。3、初始化父类的成员变量。4、执行父类的构造函数。5、初始化子类的成员变量。6、构造代码块创建对象时执行。7、执行子类的构造函数。
其中静态代码块属性和构造函数调用的顺序如下:1、初始化父类的静态变量,静态代码块,初始化的顺序按照出现顺序。2、初始化子类的静态变量,静态代码块。3、初始化父类的成员变量。4、执行父类的构造函数。5、初始化子类的成员变量。6、构造代码块创建对象时执行。7、执行子类的构造函数。















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









