






2020.6.10:更新了部分解决方法和一个难点。
2020.1.22:更新有哪些可能有效的解决方法。
前言:
这是本专栏的第一篇文章,主要会讲述个人对图像分割这个领域里面的一些浅显的理解,后续还会更新显著物体检测,目标检测,图像生成等方面研究的文章,当然也会包括我的一些不靠谱的直觉和灵感,希望能够给其他人一些启发。如有讲不合适的地方,欢迎指正。
目录:
1,图像分割在研究什么?
2,图像分割的难点在哪里?
3,有哪些可能有效的的解决方法?
1,图像分割在研究什么?
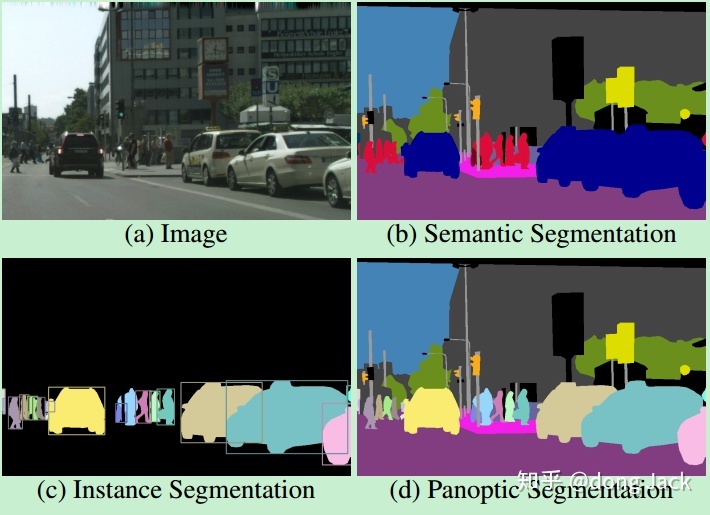
图像分割自始至终都在解决一个问题,那就是怎么恰当的把一幅图像分成不重叠的子区域。那么如何来定义这个‘恰当’呢?这个是由分割算法所服务的后续应用所决定的。就目前(9120年)来说,图像分割一般会分为图1所示的三种类型:能够区分不同的种类的物体-语义分割;能够区分同一类可数物体的不同实例-实例分割;能够区分同一类可数物体的不同实例以及不可数物体的种类-全景分割。分割能够把一幅图像解析得越精细,那么后续对后续的应用也就是更加友好的。
2,图像分割的难点在哪里?
虽然定义分割的种类不一样,但是分割领域里面存在一些共同的问题,一些常见的问题比如,因为相机和拍摄物体的距离远近引起的同一个物体在图像中可能占不同大小的画幅->多尺度问题;拍摄角度物体的不同->物体多姿态(或者多视角)问题;外界的光照不同->光照问题等。这些我就不细讲了,因为已经有相当多的论文和专栏在讲解这些。在这里我提几个关注的人还不太多的难点:
2.1,分割边缘不准的问题。

从常见的SegNet的分割示例(图2)可以看出,树干和车对应的分割区域边缘一直在震荡,变形。其边缘并没有得到很好的保留,就算换成现在分割效果很好的 deeplabv3+依然还是能发现这样的现象。究其最根本的原因,还是因为相邻临的像素对应感受野内的图像信息太过相似了,如果临近的像素都属于所需分割区域的内部,那么这种‘相似’是有利的,但是如果相邻 像素刚好处在所需分割区域的边界上,那么这种相似就是有害的了。
2.2,在同一副图像中不同类别或实例的像素不均衡的问题。不同物体分割的难度也并不一样。
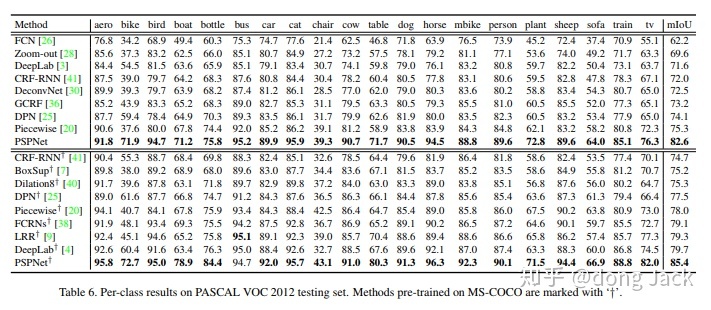
在大多数情况下,我们是直接把训练模型后面直接接一个 softmax,然后交叉熵训一波。但是这样训出来的模型,是建立在每个物体类别的像素数,以及每个物体的分割难度是差不多的假设下的。从图3可以看出往往样本少的,结构复杂不好分割的类别(如(sofa,bike,chair )效果会比较差,而且整体的结果的方差还是相对比较大的。
2.3,标注费事费力,且标注中是可能存在噪声的。
文章[4]指出仅仅单独标注图像中单个物体所需的时间就可以达到40s,假设一张图里面大概有10个物体那么一张图也得标5分钟了,要是像Cityscape数据集那样精细的分割标注,估计怎么也得10-20分钟一张图。训练一个成熟的分割模型,怎么也得需要上万张的训练图像了。而且要是应用场景不一样,要想效果好,每个场景都得标一个这样得数据集。估计人都要没了。就算外包给公司标,时间和成本也是很大的问题。另外很重要的问题是由于标注规则可能人工定得不太合理,标注出来的数据集训出来的模型效果不好,还得返工。就算是现在公开的一些数据集有着很精细的标注,但是难免会有遗漏或者错标(噪声)。
2.4,如何对遮挡区域进行建模?
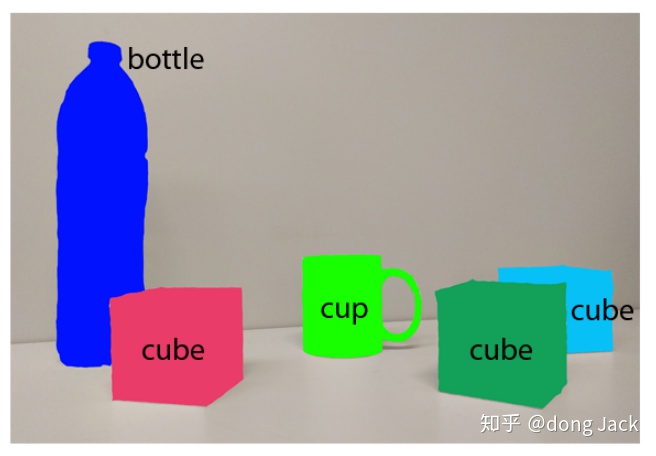
对于我们人类来说我们能够很好的处理遮挡问题,因为我们事先知道每一类事物的大致结构,我们能够想象出被遮挡的物体的大概区域在哪里。比如图4中的那只被遮挡的天蓝的方块,就算被绿色的方块遮挡到了,我们也能想象出它的大致形状。那么怎么让网络模型也具有这样的能力呢?,我们是否需要对被遮挡的区域进行单独的通道进行建模?或者直接对图像进行分层解析,即是把一张图像看成有多张包含不同语义(实例)图像的组合,这些都是未可知的问题。
2.5,CNN的分割网络耗显存的问题。
往往训一个 ResNet101分类模型,在一张12G的GPU上 batch_size还能设到32左右,但是要是训练一个以ResNet101为基础网络框架的分割模型,那么batch_size就只能掉到4左右甚至到1。这样导致的最严重的问题便是模型收敛速度会非常的慢。一张卡训一个大一点数据集,比如COCO,一两周是没跑了。并不是每个应用场景的硬件设备都有这么大的显存,也并不是每个研究组都有服务器集群可供训练模型。
本质的原因在于分割不光像分类一样需要高层的语言信息,它同时也需要高分辨率的特征图去恢复图像的细节特征。然而高语义一般需要更多的通道去表示,从而导致特征图具有高语义和高分辨率是两件不可兼的事情。但是真的是这样吗?这样的结论是建立在现有的FCN或者 Encoder Decoder的分割网络架构下的,这些结构的模型往往在最末端的特征图(映射成类别热图之前的特征图)有着较高的分辨率也有着较多的通道数。也许我们并不需要那么多的通道(显存)去对高分辨率的高频信息进行表示。
写到这里估计会有人说这不就和HRNet的思想变成一样了吗?,确实是有相似之处的,但是HRNet就是这这个思路的最终模型了吗?这是个是值得探讨的问题。也许我们是时候回到对图像进行小波变换的时代了。对图像中的高频,中频,低频信息分开建模也许是一个不错的构建网络模型的思路。
2.6 ,如何定义图像的上下文问题。
不管是在传统的图像分割方法,还是现在独占鳌头的 深度学习的方法中,大家都意识到图像的上下文是一个非常有用的东西。但是它又是一个比较模糊的概念,什么是上下文?每个像素的上下文都是都是相同的大小吗?怎么可视化每个像素的上下文?
2.7,模型的设计上缺少显示的不同图像中语义相同区域特征的交互。
目前大多数的模型都是在把每张图像当成独立的样本来训练模型,各个样本之间的信息交互是靠共享模型的权重来完成的。但是这样做对于图像的语义特征的提取和表征就是最好的了吗?不同图像中对同一种语义的表示可能都是有差异的,那么不同图像中同一种语义表示的“相同”和“差异”又代表了什么含义呢?我们是否能够利用这些特性构造出语义表达能力更强的CNN,或加速网络的训练过程?
2.8,如何简单有效区分同一类物体的不同实例?
在SOLO系列出来之前,实例分割主要分为两个大类:两阶段的MaskRCNN系列以及一阶段的Associative Embedding系列。MaskRCNN系列效果好,但是因为引入了roi_crop,proposal network等过程,会让模型变得比较复杂。Associative Embedding系列简单直接但是因为分割是像素级别的聚类,所需聚类的实例较多,不同类别之间的边界网络学得也并不清晰,所以导致最后的分割结果边界会有明显的粘连现象。当SOLO系列出来后一举改变了局面,现在的情况是一阶段的SOLO系列的论文在各个数据集上吊打MaskRCNN。
但是SOLO系列需要分割的类别是 SxSxC个类别,也就是SxSxC个通道的分数图,如果小物体较多,就需要把S设得较大,如果类别较多SxSxC这个数也就会变得很大,所以如何设计网络结构,减少SxSxC的值。以及如何简单有效区分同一类物体的不同实例?依然是一个开放的问题。
这个问题我目前也还没有特别好的想法,各位炼丹师可以自由的发挥自己的想象空间。
可参考的论文:
SOLOv2: Dynamic, Faster and Stronger
Conditional Convolutions for Instance Segmentation
End-to-End Object Detection with Transformers
3,有哪些可能有效的的解决方法?
3.1,对网络输出的分割的边界增加额外的损失,或者让网络对边界的特征和区域内部的特征分开建模学习。其本质上的思想还是让网络同时做两个任务:分割和边缘检测。另外,提高输入图像的输入分辨率和中间层特征图的分辨率同样也是简单有效的。
增加额外的损失的可以参考的论文有:
Salient Object Detection with Pyramid Attention and Salient Edges
Attentive Feedback Network for Boundary-Aware Salient Object Detection
这两篇文章就是让网络在原来的分割的loss基础上多了一个做边缘检测的loss。
对边界的特征和区域内部的特征分开建模学习的论文有:
Selectivity or Invariance: Boundary-aware Salient Object Detection
正如论文中所提到的,要做好分割,我们希望物体边缘的特征和周围特征是非常具有区分性的,而物体内部的特征和周围相似即可。
但是从目前的的研究来看,评价边缘的方式基本靠目测,没有具有针对性的指标来评价边缘的好坏(这个是面试时一个大佬说的,不是我想到的)。可以尝试从GT提取出一个物体的边缘出来,然后把这个边缘贴到预测的mask上,用边缘上的每个点到预测的mask最近的外边缘像素个数之和 除以 Mask本身的像素数 来做一个新的指标(本人未尝试过,只是目测可行)。另外,边缘检测和分割两个任务如何相互辅助,有没有比合并(堆叠和相加))特征图更加有效的方式也是值得探索的。
3.2,利用loss动态加权或者在图像二维空间上采样来解决同一张图像中不同语义的像素个数不均衡以及学习的难易程度不同的问题。
这个思路目前最受关注的文章应该就是 凯明大大的 PointRend: Image Segmentation as Rendering这篇文章了。有人会有疑问说这不就是OHEM 或Focal Loss的思路吗?没有特别的新鲜感,但是要注意到PointRend这篇文章的设计的难样本挖局的方法在提高边界分割准确度的同时没有增加过多的计算量,并且还能抗边界锯齿。这对降低目前大多数分割方法为了追求精确的分割边界而设计的臃肿的Decoder 有很大的启发性。
那难样本挖掘为啥就能帮助优化边界和类别不均衡呢?那是因为 往往挖掘出来的难样本就是边界上的像素点,以及语义类别中样本个数较少的像素点。所以做难样本挖掘往往比做单纯的类别不均的方法更加有效。
也可以适当参考一些图像分类里面应对数据不均衡的Loss的设计比如:Focal Loss,DR Loss等。
3.3,利用半监督或者弱监督学习的方法减少标注昂贵的问题。利用多个标签有噪声的样本或其特征构建虚拟的标签干净的虚拟样本或特征来减少标签的噪声。
目前来看,对于分割来说,无标签数据能够为神经网络的训练带来三点好处:
- 通过标签传播的方法增加训练数据。
- 通过无标签数据的输出构建正则项获得额外的监督信号。
- 用无标签数据来学习到数据的一些分布特征或者像素空间结构特征。
目前我最看好的半监督方法是基于GAN的方法它能同时实现2和3,具体可以参考SaliencyGAN:Deep Learning Semi-supervised Salient Object Detection 这篇文章。但是GAN的难训练以及收敛慢也是一个老大难的问题,不太好保证收敛结果的稳定性,但是我相信随着GAN的迭代发展,这些问题会慢慢得到解决。也可适度参考一些图像分类上的半监督方法,比如 MixMatch 系列。
而我觉得目前减少训练数据比较实用的方法是弱监督和半监督学习结合的一些算法,比如说分类任务(弱监督)和分割任务(强监督)相互促进的一些算法。因为图像级别的类别能够帮模型学到很好的图像特征提取器,而少量的像素标签能够帮助模型学好如何利用底层特征恢复出高清的分割mask。
具体可以参考的论文有:On Symbiosis of Attribute Prediction and Semantic Segmentation。
减少标签的噪声相关的研究方向是:learning from noisy labels
可参考的文章有:
MetaCleaner: Learning to Hallucinate Clean Representations for Noisy-Labeled Visual Recognition。
Training Convolutional Networks with Noisy Labels。
3.4,利用合理的上下文的建模机制,帮助网络猜测遮挡部分的语义信息。
这部分可以参考
Adaptive Pyramid Context Network for Semantic Segmentation
Learning to Predict Context-adaptive Convolution for Semantic Segmentation
两篇文章。
3.5,在网络中构建不同图像之间损失或者特征交互模块。
这部分可以参考的分类任务的文章是:
Learning Attentive Pairwise Interaction for Fine-Grained Classification
相关的方向有 co-saliency,co-segmentation等。
Panoptic Segmentationarxiv.org https://towardsdatascience.com/review-segnet-semantic-segmentation-e66f2e30fb96towardsdatascience.com https://arxiv.org/pdf/1612.01105.pdfarxiv.org https://arxiv.org/pdf/1903.06874.pdfarxiv.org https://arxiv.org/pdf/1704.06857.pdfarxiv.org














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









