





这个AES的Chisel实现是两年前写的,当时学了一段时间的Chisel后想要练下手,就当是个大作业。AES相对简单,有明确的算法描述和golden vector,设计、验证都会比较方便。前后大概用了一两周的业余时间把它写出来调通了,但当时注释写的比较少,好在我当时写的代码还算直观,回忆一下还是可行的。今天就当事后补的非正规文档(正常开发流程可不是这样,一定是先文档后代码的)。不算是文档,更多的是如何设计一个模块、思考设计中需要注意的问题。
先简单说一下我实现的功能,FIPS-197的AES实现,支持Nk=4, 6, 8,但无法同时支持,每次综合出来的硬件只能对应一个配置,因为是当作一个练习,就没有做更高要求。AES标准就不多介绍了,现在使用及其广泛的对称加密标准。很多领域如块存储设备的加密系统是基于AES的如XTS-AES。因为AES算法的工整性,解密和加密的过程很类似,硬件实现也很类似,然而我并没有复用加密、解密的硬件,如果是对面积非常敏感的话,可以考虑对部分硬件逻辑的复用(SBox这种 LUT是没法复用的)。需要注意的是本实现只是实现了AES的算法,没有其他方面的考量,并不能直接用于安全系统中,否则分分钟被攻破。如何提高AES实现的安全等级有很多学问,并不在本文讨论范围之内。
1. Algorithm
AES的解密和加密很类似,本文就以加密为例。加密算法的伪代码如下:
Cipher(byte in[4*Nb], byte out[4*Nb], word w[Nb*(Nr+1)])
begin
byte state[4,Nb]
state = in
AddRoundKey(state, w[0, Nb-1]) // See Sec. 5.1.4
for round = 1 step 1 to Nr–1
SubBytes(state) // See Sec. 5.1.1
ShiftRows(state) // See Sec. 5.1.2
MixColumns(state) // See Sec. 5.1.3
AddRoundKey(state, w[round*Nb, (round+1)*Nb-1])
end for
SubBytes(state)
ShiftRows(state)
AddRoundKey(state, w[Nr*Nb, (Nr+1)*Nb-1])
out = state
end理解一个算法或设计,首先看它的输入和输出。AES cipher的输入是明文128 bits,即4个4-byte的word,输出也是一样的(要不说是对称加密呢),另外就是round key,我们从伪代码上可以看到round key是Nr+1倍的输入数据宽度,这里的Nr+1是迭代的次数(Nr和Nk即key的长度有关:Nr=Nk+6),每次迭代使用其中的一段。最后一次迭代和之前相比少了MixColumns,我们可以考虑最后一级将其bypass掉。
我们知道AES的秘钥长度是128-bit, 192-bit或256-bit,如何生成这么长的round key呢?就是靠key expansion了,具体算法spec中有详细描述。本实现中key expansion是加密、解密逻辑共享的,是需要在加密、解密运算前单独trigger运算,如果对于实际应用来说应该需要加个wrapper来控制key expansion的,其实对于XTS-AES也是这个道理。
Key expansion相对独立,在spec中有单独的算法描述。可以看出来key expansion也是个迭代的过程。算法的伪代码的主要部分如下:
while (i < Nk)
w[i] = word(key[4*i], key[4*i+1], key[4*i+2], key[4*i+3])
i = i+1
end while
i = Nk
while (i < Nb * (Nr+1)]
temp = w[i-1]
if (i mod Nk = 0)
temp = SubWord(RotWord(temp)) xor Rcon[i/Nk]
else if (Nk > 6 and i mod Nk = 4)
temp = SubWord(temp)
end if
w[i] = w[i-Nk] xor temp
i = i + 1
end while怎么确保自己对算法理解正确了呢?动手写个reference model吧,也可以作为之后验证的model。由于我打算用Chisel来写AES的设计,用Scala来实现reference model是个很自然的想法。具体请参考AesRef.scala。
2. Microarchitecture
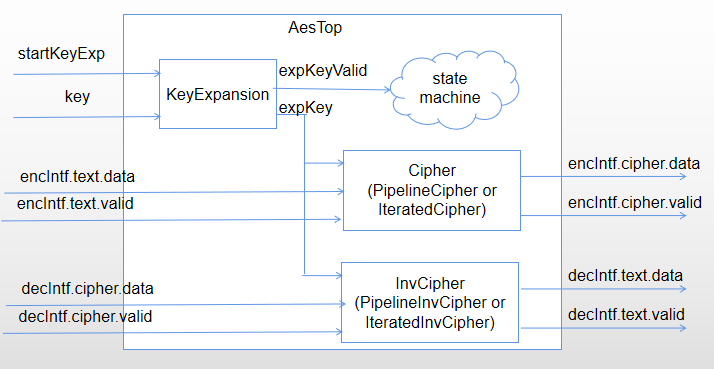
先来个整体的框图有个直观印象。

2.1. Key expansion
由于key expansion在实际使用的时候调用频率不高,我们可以考虑就用迭代方式实现以减小面积、功耗。Key expansion的实现得很小心,实现不好的话面积会比实现好的大很多。
Key expansion的输入是Nk*32 bit的key,输出是(Nk+7)*128 bit的round key。可不可以key expansion和cipher/decipher同步迭代计算以节省round key的flop呢?首先,这对于cipher/decipher的pipeline实现来说是不行的,因为pipeline实现需要整个round key;其次即使使用迭代的cipher/decipher实现,也只有cipher可以配合迭代的key expansion,而decipher算法本身要求在第一次迭代需要知道key expansion最后一次迭代的round key,所以是行不通的。为了简便起见,我们使用(Nk+7)*128 个flop来存储round key。
如果简单地从key expansion算法映射成硬件的话,会造成很大的面积浪费。让我们重新看一下key expansion的伪代码,里面不停地使用上一次迭代出来的round key生成新一轮的round key,如果初始key 从0开始放,存储round key也是顺序递增的话,每次迭代都需要看本次迭代的序号取得上一次的round key,根据序号寻址的过程映射到硬件上就是一堆MUX。有没有办法省掉这堆MUX?有!我们可以把最初的key放在最末端(序号最大,依Nk来定),每次迭代的时候取上次的值都从最末端拿,运算出来的新的round key仍存储在最末端,而上一次的round key则移到了前面的位置。这样迭代到最后,round key就是从0开始的。这样每次迭代的代价就是进行128 bit的移位即可,而我们知道对每个bit移位在硬件上实现就是连线加一个MUX而已,对每一轮都是一样的,比单纯映射算法实现所需的MUX少了一个数量级。使用这种技巧可以针对key expansion省掉大约75%的面积。
那每个cycle更新几个round key呢?考虑到想用同一段代码实现不同Nk的key expansion,也考虑到组合逻辑的timing path,比较好的选择是4。对于Nk=4很直观,Nk=8则每次迭代使用2个cycle,Nk=6比较猥琐,我们得有一个本地counter好来看进行到哪个round了,好在迭代次数并不多,复杂度可控。
以Nk=4为例子,每一次的迭代过程如下图所示。

具体实现请参考KeyExpansion.scala。
2.2. Cipher
从Cipher算法的描述上我们可以看到运算的过程有迭代,自然而然我们可以想到可以使用复用硬件逻辑多cycle迭代来进行运算,这样的好处是省面积。然而有得必有失,多个周期才出一个结果牺牲的是throughput。如果throughput达不到指定要求的话,我们就应该要增加并行度了,比如实例化多个迭代方式的AES逻辑,或是使用pipeline。我的实现里既有迭代方式也有pipeline方式。选择什么方式实现、选择如何的并行度本身就要看各种约束:throughput,area等等。设计的过程就是根据各种约束对各种指标权衡取舍的过程,其中总会有某些方面的牺牲和妥协。
先来看一下迭代方式的实现。每次迭代的逻辑是共享的,这个时候就要记录迭代的次数,在最后一次的时候把MixColumn bypass掉。Block digram如下:

而pipeline方式的实现很直观,每个round使用一级pipeline,这个在正式设计中是可以调整的,比如多个round一级pipeline,以权衡latency和timing。这时候最后一级就可以冠冕堂皇地把MixColumn逻辑去掉了。

这个基本组件都有了之后,下面就是搭积木了,在顶层有个小状态机控制KeyExpansion和Cipher/InvCipher。完工。
设计Microarchitecture的同时就应该把细节记录到文档里,这个时候整个电路就在你脑子里了,各个模块的功能以及连接关系都应该很清楚了,写RTL只不过是把设计文档翻译成代码而已。
3. RTL
Chisel写的也是RTL?没错,Chisel描述的是精确的电路,并不是HLS语言,不会让工具随意发挥的。写Chisel和写Verilog一样,同样使用的是硬件思维,写的时候大脑里要有实际的电路。对于写可综合的电路,你自己想不出电路怎么实现,工具也是办不到的。
我的AES实现里只有在顶层的时候用了IO,其他地方都是用函数实现。Chisel里的函数不同于Verilog的函数,可以实现时序逻辑,比如:
object PipelineCipher {
def latencyCycles(Nk: Int): Int = Nk + 7 // latency: Nr+1
def busyCycles(Nk: Int): Int = 0 // ready for each cycle
def apply(Nk: Int)(text:UInt, expKey: Vec[UInt]): UInt = {
val pc = new PipelineCipher(Nk)(text, expKey)
val iniState = RegNext(pc.addRoundKey(0)(text)) //may be combined with next pipe
val iterState = Reg(Vec(pc.Nr, UInt(128.W)))
for (i <- 0 to pc.Nr-1) {
iterState(i) := pc.cipherIteration(i+1)(if (i==0) iniState else iterState(i-1))
}
iterState(pc.Nr-1)
}
}这里面的iniState和iterState就会被实现为Flop。调用PipelineCipher(...)将实现整个pipeline的cipher。调用的过程就调用一个函数那么简单,避免了Verilog里繁杂的连线。一个Chisel熟练工可以节省写RTL的时间,却无法省去IC设计里其他环节的时间,却会增加一些额外成本和风险,这也是Chisel无法大面积普及的一个重要原因。这些就不展开说了。
具体RTL代码请参考 https://github.com/yaozhaosh/chisel-aes。
4. Testbench
对于Testbench我并没有花很多时间来完善,仅是实现了一个direct test的功能,使用PeekPokeTester,用来和spec中的golden vector来比对。调试使用的方法也是通过打印来完成。如果写一个Verilator顶层可以dump wavefrom到vcd文件里,也是一种debug的手段。















 5018
5018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









