





也许我这个标题不大严谨,学渣念书就是小和尚念经,念了啥也不记得,只记得个名词了。我们在学统计学的时候好像到处都看到变量选择,为啥要做变量选择?在哪些情况下要做变量选择?做变量选择的效果好不好?姑且把这个标题这么写吧,似乎变量选择也不止出现在回归分析中。
对于最小二乘估计,我们不满意的原因通常有两个:
1,通常具有低偏差高方差,从而预测准确度不够好。我们有时候可以用shrinkage方法通过收缩一些变量的系数或者将其收缩为0,牺牲少许偏差而减少一些方差,使得预测准确度改善。
2,变量太多的话,我们希望取出其中最有影响的一小部分。
目录:
- 子集选择法
- Shrinkage Methods
子集选择法:
通过子集选择,我们仅保留选择的子集,而丢弃其他。用最小二乘法估计保留的变量的系数。子集选择法有多种不同的策略。
3.3.1 Best-Subset Selection

算法:the leaps and bounds procedure (Furnival and Wilson, 1974),适用于p为30到40个的情形。
注意大小为2的最佳子集不一定包含大小为1的最小子集包含的变量。
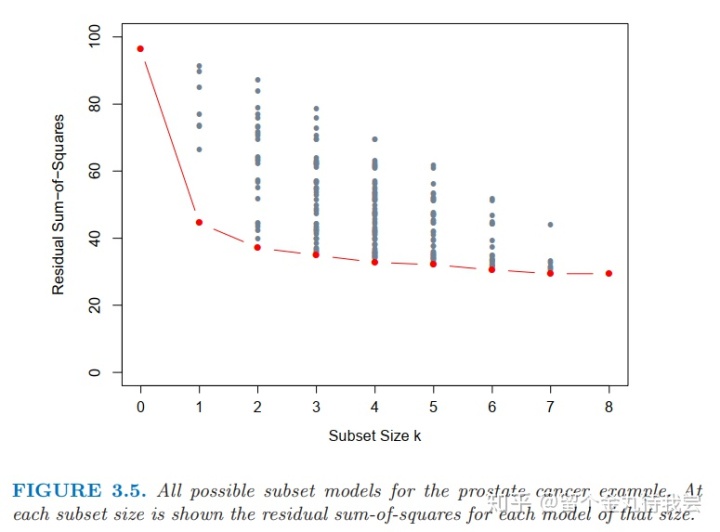
图3.5下边界中红色的线表示的是可以通过最佳子集进行选择的模型。这条曲线叫作最佳子集曲线,必然不断减小,因而不能用来选择k。
3.3.2 Forward- and Backward-Stepwise Selection
当变量个数p大于40个的时候,在其中搜索所有可能的子集变得不可行。因而可以考虑一个更好的搜索路径。

前向算法是个贪婪算法:产生了一系列的嵌套模型,因此有可能找到的并不是真正的最优的模型。
Backward-stepwise selection

注解:
1. 待删变量是所有变量中z值最小的变量。
2. 向后逐步删除法只适用于N>p的情形。而向前逐步选择法对此没有要求。
软件说明:R包中的step函数使用AIC法则来做出选择,在每一步添加或删除使得AIC得分最小的变量。
3.3.3 Forward-Stagewise Regression

开始类似于前向逐步回归,从截距项为
与前向逐步回归不同,将系数加到该变量的当前系数上去的时候,没有对任何其他变量做调整。
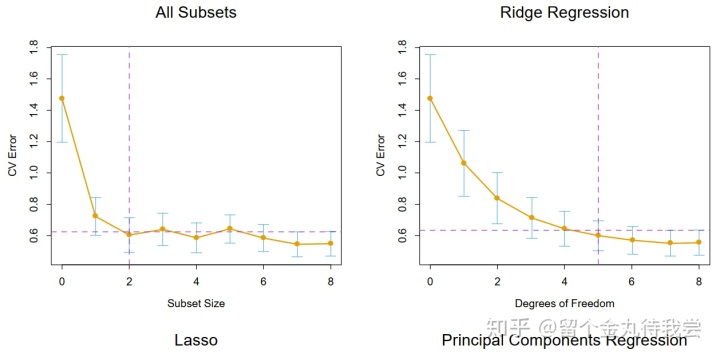
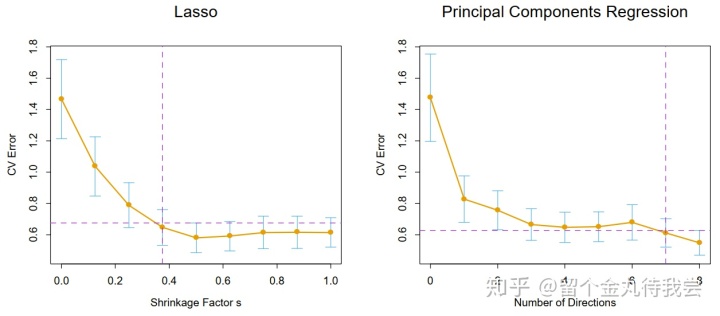
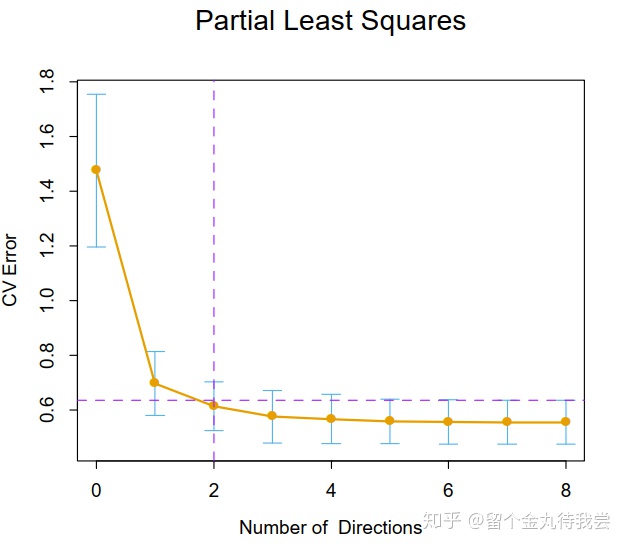
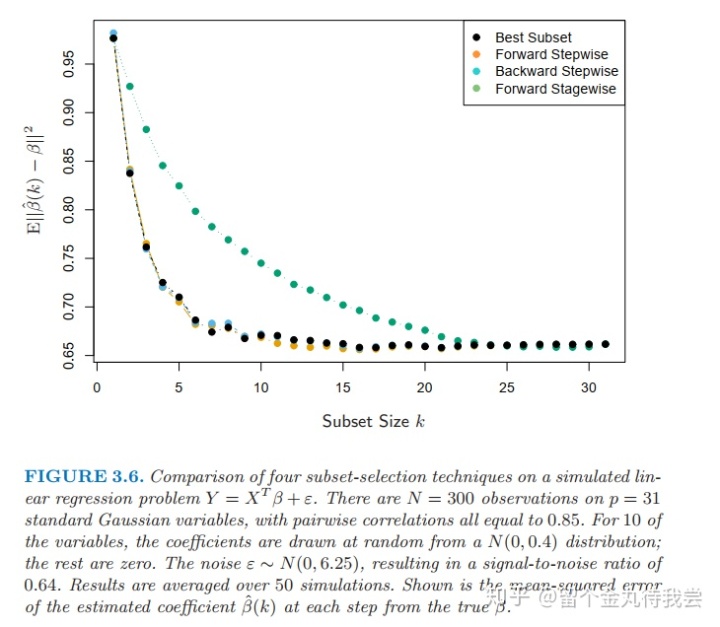
交叉验证用于训练集,选择复杂参数是训练过程的一部分。
Shrinkage Methods
3.4.1 Ridge Regression
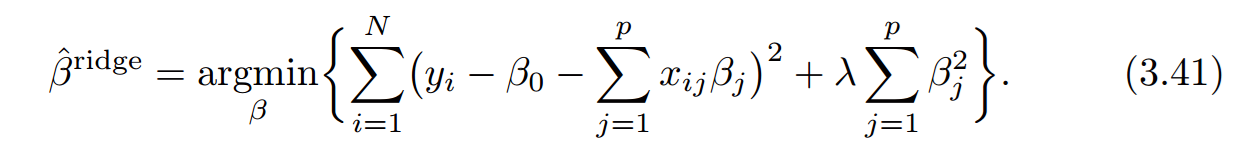
λ ≥ 0 is a complexity parameter,把回归系数向0压缩以及朝彼此的方向压缩。λ越大,压缩的越厉害。
(3.41)的等价形式:

注解:
1. (3.41)与(3.42)中的λ与t有一一对应的关系。
2. 适用情况:当回归模型中有许多互相相关的变量的时候,则回归系数可能被很糟糕的估计,而且方差会特别大。
3. 对于变量的不同标度下估计的结果不同,因此在解(3.41)前要先对自变量标准化处理。
4. 注意到截距项β0并没有被惩罚。惩罚截距项会使得结果依赖y的原点的选择,也就是说对yi加一个常数c,并不会简单的导致预测量增加同样的量c.
5. 用ybar来估计β0。
6.因此对自变量进行中心化。因而假定自变量为p维(而不是p+1)
将(3.41)写成矩阵形式为;
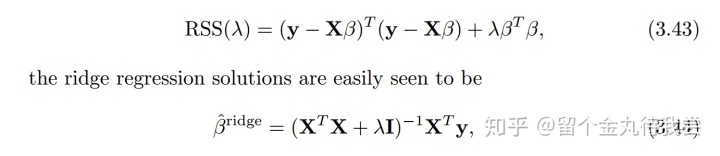
从奇异值分解的角度看岭回归:
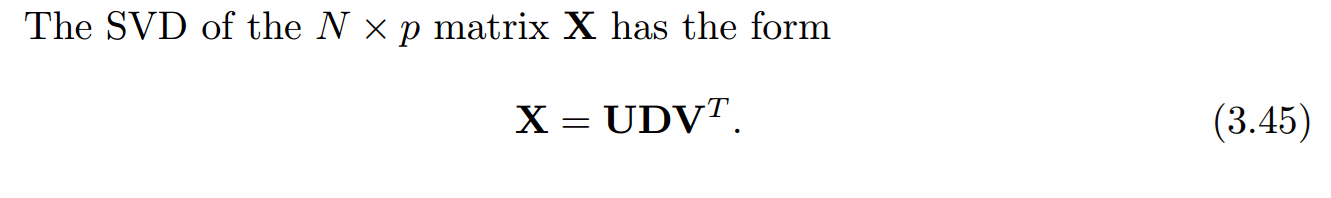



岭回归的自由度:

When k = p the value of λ that solves df(λ) = p is seen to be λ = 0.
k = p, p - 1, p - 2, · · · , 1
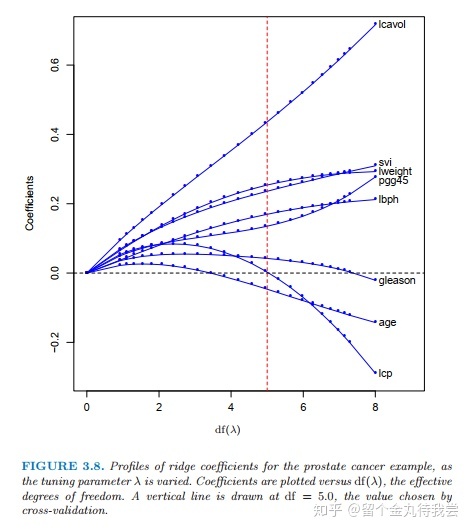
3.4.2 The Lasso

等价的拉格朗日形式:
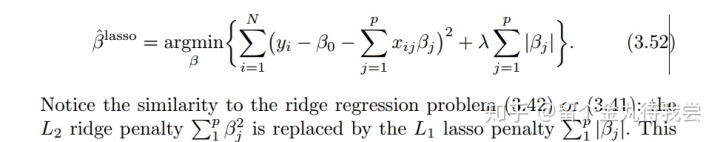
注解:
1. 惩罚项使得解并不是y的线性变换。解没有closed form的表达式。
2. 计算lasso是个quadratic programming problem。与ridge regression的computational cost相同。随着λ变化,得到解的整个路径的有效算法是可行的。
3. 使得t充分小,可以使得一些变量的系数恰好等于0。
4. t应该adaptively chosen,从而拿来最小化expected prediction error的估计量。
5. the standardized parameter指的是:
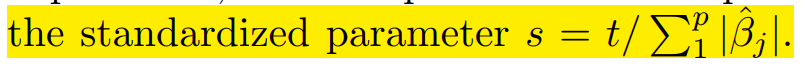

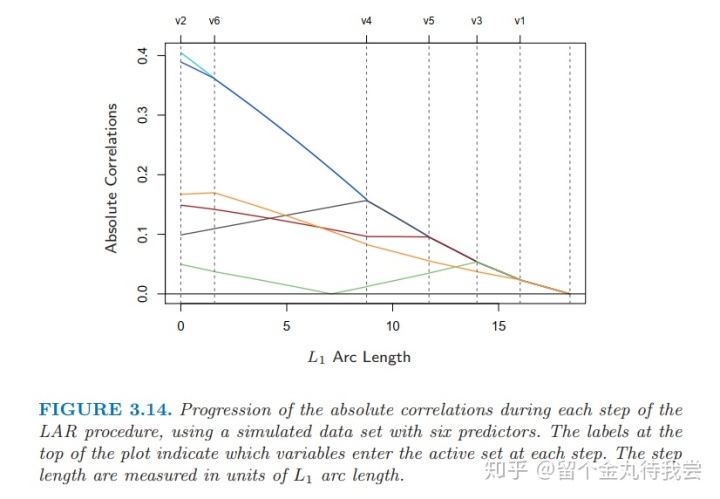
3.4.4 Least Angle Regression

注解:
1. 最小角回归可以看成是“democratic”版的逐步向前回归。
2. LAR与lasso有关联。
3. 逐步向前回归每步加入一个变量,识别出最优的变量加入到活跃集中,然后更新当前的最小二乘拟合,使得包含进活跃集中的所有变量。
1. 第一步,识别出与因变量最相关的自变量。
2. 把这个变量的系数连续的向最小二乘法的系数移动,使得该变量与当前残差的相关系数在绝对值的水平下递减。
3. 当有其他变量与当前残差的相关系数tied,此过程停止。

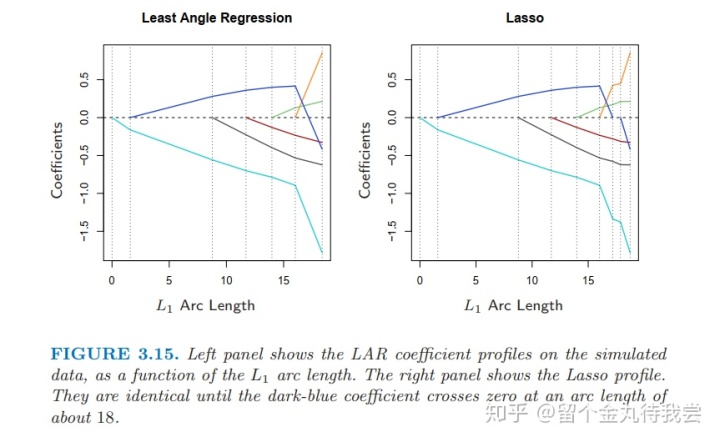

Algorithm 3.2 with the lasso modification 3.2a is an efficient way of computing the solution to any lasso problem, especially when p
为什么LAR与Lasso这么相似呢?


LAR and Lasso的自由度:

















 1095
1095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









