






第四章 SQL应用
1. DCL 数据控制语言
- grant
- revoke
2.DML
- insert
- update
建议:
1,将需要更新的数据的主键先查出来,然后按主键更新。
2,如果无法达到以上需求,需要将where 条件后的列,设置合理索引
3,减少更新范围
4,尽量不要跨多表更新- delete
建议:
1, 可以使用"伪删除",定期归档
2, 批量删除,推荐pt-archiver
3, delete比较频繁,建议定期做碎片整理 alter table t1 engine=innodb;delete truncate drop 区别?
drop直接删掉表;
truncate删除的是表中的数据,再插入数据时自增长的数据id又重新从1开始;
delete删除表中数据,可以在后面添加where字句。
(1)DELETE语句执行删除操作的过程是每次从表中删除一行,并且同时将该行的删除操
作作为事务记录在日志中保存以便进行进行回滚操作。TRUNCATE TABLE 则一次性地从表中
删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的。并且在
删除的过程中不会激活与表有关的删除触发器。执行速度快。
(2)表和索引所占空间。当表被TRUNCATE 后,这个表和索引所占用的空间会恢复到初
始大小,而DELETE操作不会减少表或索引所占用的空间。drop语句将表所占用的空间全释放掉。
(3) 一般而言,drop > truncate > delete
(4) 应用范围。TRUNCATE 只能对TABLE;DELETE可以是table和view
(5) TRUNCATE 和DELETE只删除数据,而DROP则删除整个表(结构和数据)。
(6) truncate与不带where的delete :只删除数据,而不删除表的结构(定义)drop语句将删除
表的结构被依赖的约束(constrain),触发器(trigger)索引(index);依赖于该表的
存储过程/函数将被保留,但其状态会变为:invalid。
(7) delete语句为DML(data maintain Language),这个操作会被放到 rollback segment中,事
务提交后才生效。如果有相应的 tigger,执行的时候将被触发。
(8) truncate、drop是DLL(data define language),操作立即生效,原数据不放
到 rollback segment中,不能回滚
(9) 在没有备份情况下,谨慎使用 drop 与 truncate。要删除部分数据行采用delete且
注意结合where来约束影响范围。回滚段要足够大。要删除表用drop;若想保留表而
将表中数据删除,如果于事务无关,用truncate即可实现。如果和事务有关,或
想触发trigger,还是用delete。
(10) Truncate table 表名 速度快,而且效率高,因为:truncate table 在功能上与
不带 WHERE 子句的 DELETE 语句相同:二者均删除表中的全部行。但
TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。DELETE 语句每
次删除一行,并在事务日志中为所删除的每行记录一项。TRUNCATE TABLE 通过释放存
储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
(11) TRUNCATE TABLE 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行
标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。
如果要删除表定义及其数据,请使用 DROP TABLE 语句。
(12) 对于由 FOREIGN KEY 约束引用的表,不能使用 TRUNCATE TABLE,而应使用不带 WHERE 子句
的 DELETE 语句。由于 TRUNCATE TABLE 不记录在日志中,所以它不能激活触发器。
- select
select select_list from where group by having order by limit where :
比较操作符 : = > < >= <= <>
逻辑连接符 : and or
模糊查询 : like
其他 : in not in beteween and group by + 聚合函数(sum,count,avg,max,min,group_concat)
5.7版本以后: SQL_MODE=only_full_group_by
- SQL_MODE 作用? 约束SQL行为,保证数据有意义。
例如:00不为日期,0不能为除数,都是表里自带的。 - select countrycode,count(name),name from city group by countrycode;
mysql> select countrycode,count(name),name from city group by countrycode;
ERROR 1055 (42000): Expression #3 of SELECT list is not in GROUP BY clause and
contains nonaggregated column 'world.city.Name' which is not functionally dependent
on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
mysql> select countrycode,count(name),group_concat(name) from city group by countrycode;展示(国家,城市数量,城市名称)从city表,以国家分组
这个时候国家和城市数量都可以一一对应,但是城市名称不是单一的,而是有城市数量那么多,一个表展示不开,所以only_full_group_by会报错
有一个版本是不会报错的,他只会展示第一个数据
group_by作用:1.排序 2.去重 3.数name数量
3.元数据获取
例子:
- 统计业务数据库对象信息
select table_schema,table_name from information_schema.tables where table_schema not in ('mysql','sys','information_schema','performance_schema');效果
+--------------+-----------------+
| table_schema | table_name |
+--------------+-----------------+
| oldboy | stu |
| oldboy | student |
| world | city |
| world | country |
| world | countrylanguage |
+--------------+-----------------+
5 rows in set (0.01 sec)- 统计系统中所有非InnoDB
select table_schema,table_name ,engine from information_schema.tables where table_schema not in ('mysql','sys','information_schema','performance_schema') and engine != 'innodb';- 将所有非InnoDB表替换成InnoDB
alter table world.t1 engine=innodb;
select concat("alter table ",table_schema,".",table_name," engine=innodb;") from information_schema.tables where table_schema not in ('mysql','sys','information_schema','performance_schema') and engine != 'innodb' into outfile '/tmp/alter.sql';报错:
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv
option so it cannot execute this statement解决:
[root@master ~]# cat /etc/my.cnf
[mysqld]
user=mysql
basedir=/data/app/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
secure-file-priv=/tmp
[mysql]
socket=/tmp/mysql.sock- 统计每个业务库的总数据量
select table_schema,sum(INDEX_LENGTH+DATA_LENGTH)/1024 from information_schema.tables where table_schema not in ('mysql','sys','information_schema','performance_schema') group by table_schema;- 数据字典信息统计
select table_schema,table_name ,group_concat(column_name) from information_schema.columns where table_schema not in ('mysql','sys','informmation_schema','performance_schema') group by table_schema, table_name;第五章节 索引及执行计划
- 索引是什么? 相当于一本书中的目录。可以加速查询 。
- MySQL索引类型
Btree 平衡多叉树(b-treeb+treeb++tree),适合于范围查找
HASH 散列索引 ,适合于等值查询
RTREE
Fulltext - Btree查找算法介绍
下图
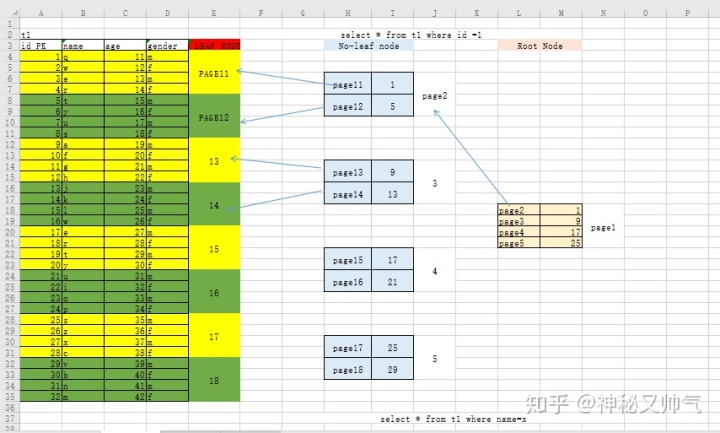
- B+Tree在MySQL中的应用
4.1 聚簇索引 (Clustered index) extent 区、簇:连续的 64个 pages(16KB),默认大小1MB
IOT表:聚簇索引,就是将表中数据组织存储在多个区中
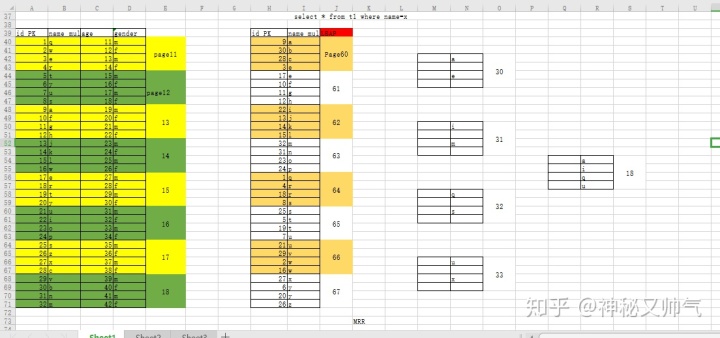
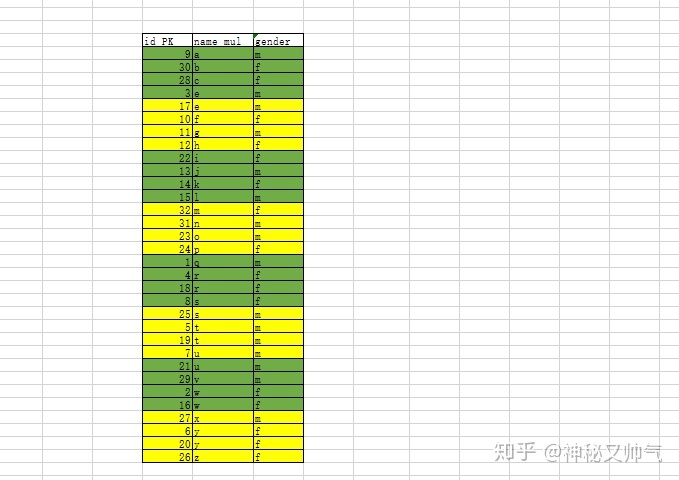
生成前提:
1. 如果建表时,显示设置了主键(PK),主键列为聚簇索引结构,组织存储数据。
2. 如果没有主键,自动按照第一个不为空的UK(唯一键unique),作为聚簇索引,组织存储数据。
3. 如果都不满足,会生成一个6字节隐藏的ROW_ID,作为聚簇索引,组织存储数据。
一般建议建表时,显示设置主键。
叶子节点:原表数据所在的数据页,就是聚簇索引的叶子节点
枝节点 :存储下层叶子节点id的范围+指针
根节点 :存储下层枝节点id的范围+指针
4.2 辅助索引 普通列的索引构建。
叶子节点: 提取 辅助索引列+ID主键值,根据辅助索引列排序,生成叶子节点。
枝节点 : 提取叶子结点辅助索引列值范围+指针
根节点 :提取枝结点辅助索引列值范围+指针
按照辅助索引列条件查询时,首先扫描辅助索引树,得到ID值,然后回到聚簇索引扫描,中查找数据据行。
什么叫回表? 回到聚簇索引查找的动作被称之为回表查询。
4.3 索引树高度的影响因素
(1) 数据行太多,例如2000w+
分表 归档 分库分表
(2) 列值长度 前缀索引
(3) 数据类型 简短的、合适的。
4.4 回表问题
带来的问题: IO 次数 、 IO吞吐量、 随机IO
如何减少回表
不回表: 如果需要查询的值都在辅助索引里有,就不需要回表了。
少量回表: 通过合适的联合索引。 精细化查询条件
提前压测:
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='test' --query="select * from test.t100w where k2='780P'" engine=innodb --number-of-queries=2000 -uroot -p123456 -verbose
5.索引管理
- 查询索引
mysql> desc city;
mysql> show index from city;- 建索引
mysql> ALTER TABLE city ADD INDEX i_name(name)
mysql> ALTER TABLE city drop INDEX i_name;- 基础管理
mysql> alter table city add index i_name(name(10));
mysql> ALTER TABLE city ADD INDEX i_name(name);
mysql> ALTER TABLE city drop INDEX i_name;
mysql> show index from city;6.执行计划查看及分析
6.1 介绍
查看优化器生成最终执行计划,评估SQL执行会不会有问题。
6.2 获取
mysql> desc select * from test.t100w where k2='780P';结果
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | t100w | NULL | ALL | NULL | NULL | NULL | NULL | 997335 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+6.3 分析
table : 语句操作的哪张表
type : ALL 、index、range、ref、eq_ref、const(system )
ALL : 全表扫描。
index : 全索引扫描
range : 索引范围扫描,> < >= <= like or in between and ,例外情况: 主键的不等值
ref : 辅助索引常量查询 =
eq_ref :多表连接在非驱动表上的关联条件是主键或唯一键。
const(system): 主键或者唯一键的常量查询。index和range一般是不符合标准的。
possible_keys : 有可能的索引
key : 最终使用的索引
rows : 需要扫描的行数
Extra : 额外信息 using filesort
7.联合索引应用细节
7.1 联合索引遵循“最左原则”?
- 建立联合索引要选择,重复值少的列放在最左侧
id name age gender ......20个列 a b c
alter table add index idx(a, b , c ); - 查询条件中必须要包含最左列 条件,才能使用联合索引
7.2 辅助索引覆盖长度
全部覆盖
idx(a, b , c );
select * from t1 where a=? and b=? and c=?
select * from t1 where b=? and a=? and c=?
select * from t1 where c=? and b=? and a=?
select * from t1 where c=? and a=? and b=?
select * from t1 where a=? and b=? and c > 部分覆盖
select * from t1 where a=? and b=?
select * from t1 where a=? and c=?
select * from t1 where b=? and a=?
select * from t1 where c=? and a=?
select * from t1 where a=? and b>? and c=?
select * from t1 where a>? and b=? and c=?不覆盖:
select * from t1 where b=? and c=?可以通过format=json,查看 "used_key_parts": 来获取走的哪些索引值
mysql> desc format=json select * from t100w where num=279106 and k1 >'dd' and k2='VWtu' ;8.建立索引的原则(DBA运维规范)
(1) 必须要有主键,无关列。
(2) 经常做为where条件列 order by group by join on, distinct 的条件(业务:产品功能+用户行为)
(3) 最好使用唯一值多的列作为索引,如果索引列重复值较多,可以考虑使用联合索引
(4) 列值长度较长的索引列,我们建议使用前缀索引.
(5) 降低索引条目,一方面不要创建没用索引,不常使用的索引清理,percona toolkit(xxxxx)
(6) 索引维护要避开业务繁忙期,建议用pt-osc
(7) 联合索引最左原则9.不走索引的情况(开发规范)
(1)没有查询条件,或者查询条件没有建立索引
(2)查询结果集是原表中的大部分数据,应该是15-25%以上。
(3)索引本身失效,统计信息不真实(过旧)
现象:
有一条select语句平常查询时很快,突然有一天很慢,会是什么原因
select? --->索引失效,统计数据不真实
innodb_index_stats
innodb_table_stats
mysql> ANALYZE TABLE world.city;
(4)查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等)
例子:
错误的例子:select * from test where id-1=9;
正确的例子:select * from test where id=10;
算术运算
函数运算
子查询
(5) 隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误.
(6) <> ,not in 不走索引(辅助索引)
(7) like "%_" 百分号在最前面不走














 1791
1791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









