






 本文详细介绍了Go语言中Map的实现原理,包括map的数据结构、bucket数据结构以及总体数据结构图。重点讲解了bucket内部如何存储键值对,以及在扩容时如何使用oldbuckets和nevacuate进行数据迁移。通过对hash桶的理解,阐述了Go Map的高效查找和存储机制。
本文详细介绍了Go语言中Map的实现原理,包括map的数据结构、bucket数据结构以及总体数据结构图。重点讲解了bucket内部如何存储键值对,以及在扩容时如何使用oldbuckets和nevacuate进行数据迁移。通过对hash桶的理解,阐述了Go Map的高效查找和存储机制。

大家在面试过程中经常会被问到hashmap的底层数据结构和算法过程。本文主要和大家探讨下go语言中的map对象的底层数据结构和算法,让大家能够理解map对象是一个什么样的存在?它为什么能够高效?
大家都知道golang中Map由链式哈希表实现,底层是hash实现,数据结构为hash数组 + 桶 + 溢出的桶链表,每个桶存储最多8个key-value对
链式哈希表从根本上说是由一组链表构成。每个链表都可以看做是一个“桶”,我们将所有的元素通过散列的方式放到具体的不同的桶中。插入元素时,首先将其键传入一个哈希函数(该过程称为哈希键),函数通过散列的方式告知元素属于哪个“桶”,然后在相应的链表头插入元素。
map的数据结构
为了彻底搞清楚map的数据结构,我从go的开源项目中找到了map的底层定义的代码如下
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
代码地址如下: https://github.com/golang/go/blob/master/src/runtime/map.go
基础概念介绍
- unsafe.Pointer 它表示任意类型且可寻址的指针值,可以在不同的指针类型之间进行转换
- 任何类型的指针值都可以转换为 Pointer
- Pointer 可以转换为任何类型的指针值
- uintptr 可以转换为 Pointer
- Pointer 可以转换为 uintptr
- uintptr:uintptr 是 Go 的内置类型。返回无符号整数,可存储一个完整的地址。后续常用于指针运算
- map存储的元素对计数,len()函数返回此值,所以map的len()时间复杂度是O(1)
- 记录几个特殊的位标记,如当前是否有别的线程正在写map、当前是否为相同大小的增长(扩容/缩容?)
- hash桶buckets的数量为2^B个
- noverflow 溢出的桶的数量的近似值
- hash0 hash种子
- buckets 指向2^B个桶组成的数组的指针,数据存在这里
- oldbuckets 指向扩容前的旧buckets数组,只在map增长时有效
- nevacuate 计数器,标示扩容后搬迁的进度
- extra 保存溢出桶的链表和未使用的溢出桶数组的首地址
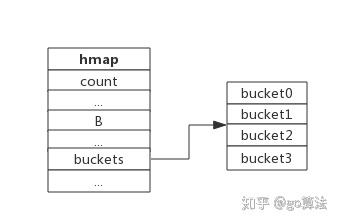
桶指针指向桶的首地址,可通过桶首地址及偏移量查询所有的桶,通过每个桶可查找到对应的键值。hmap.B=2, 而hmap.buckets长度是2^B为4. 元素经过哈希运算后会落到某个bucket中进行存储。查找过程类似。bucket很多时候被翻译为桶,所谓的哈希桶实际上就是bucket
bucket数据结构
更加源码译文可知:bucketCnt=8,一个桶只能存放8对k/v, 低8位用来寻找桶,高8位用来寻找元素
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
- tophash存储桶内每个key的hash值的高字节
- tophash[0] < minTopHash表示桶的疏散状态
- 当前版本bucketCnt的值是8,一个桶最多存储8个key-value对
- 特别注意:
- 实际分配内存时会申请一个更大的内存空间A,A的前8字节为bmap
- 后面依次跟8个key、8个value、1个溢出指针
- map的桶结构实际指的是内存空间A
哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈希值的高位存储在该数组中,以方便后续匹配。
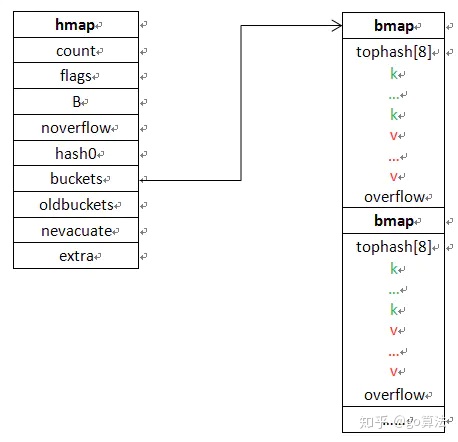
总体数据结构图
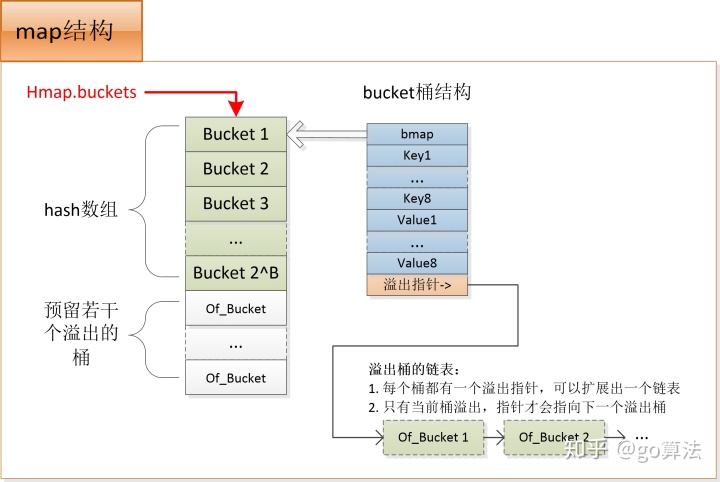
map底层创建时,会初始化一个hmap结构体,同时分配一个足够大的内存空间A。其中A的前段用于hash数组,A的后段预留给溢出的桶。于是hmap.buckets指向hash数组,即A的首地址;hmap.extra.nextOverflow初始时指向内存A中的后段,即hash数组结尾的下一个桶,也即第1个预留的溢出桶。所以当hash冲突需要使用到新的溢出桶时,会优先使用上述预留的溢出桶,hmap.extra.nextOverflow依次往后偏移直到用完所有的溢出桶,才有可能会申请新的溢出桶空间。
当需要分配一个溢出桶时,会优先从预留的溢出桶数组里取一个出来链接到链表后面,这时不需要再次申请内存。但当预留的桶被用完了,则需要申请新的内存给溢出桶。
参考资料
https://www.cnblogs.com/JoZSM/archive/2019/11/02/11784037.html https://www.jianshu.com/p/17f49e562f7b https://my.oschina.net/renhc/blog/2208417?nocache=1539143037904#comments















 3850
3850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









