






 这篇博客详细介绍了在sklearn中逻辑回归模型的样本权重调整方法,包括`sklearn.linear_model.LogisticRegression().fit()`和`sklearn.linear_model.LogisticRegression()`两个方法。通过调用方法和底层代码解析,阐述了如何在损失函数和梯度计算中应用sample_weight,并解释了`class_weight`参数如何平衡类别权重。此外,还讨论了`class_weight`与`sample_weight`的区别和联系。
这篇博客详细介绍了在sklearn中逻辑回归模型的样本权重调整方法,包括`sklearn.linear_model.LogisticRegression().fit()`和`sklearn.linear_model.LogisticRegression()`两个方法。通过调用方法和底层代码解析,阐述了如何在损失函数和梯度计算中应用sample_weight,并解释了`class_weight`参数如何平衡类别权重。此外,还讨论了`class_weight`与`sample_weight`的区别和联系。

一、sklearn.linear_model.LogisticRegression().fit() 方法
1.调用方法:
clf_weight = LogisticRegression().fit(X, y,sample_weight=sample_weight)2.底层代码:
def _logistic_loss_and_grad(w, X, y, alpha, sample_weight=None):
"""Computes the logistic loss and gradient.
Parameters
----------
w : ndarray of shape (n_features,) or (n_features + 1,)
Coefficient vector.
X : {array-like, sparse matrix} of shape (n_samples, n_features)
Training data.
y : ndarray of shape (n_samples,)
Array of labels.
alpha : float
Regularization parameter. alpha is equal to 1 / C.
sample_weight : array-like of shape (n_samples,), default=None
Array of weights that are assigned to individual samples.
If not provided, then each sample is given unit weight.
Returns
-------
out : float
Logistic loss.
grad : ndarray of shape (n_features,) or (n_features + 1,)
Logistic gradient.
"""
n_samples, n_features = X.shape
grad = np.empty_like(w)
w, c, yz = _intercept_dot(w, X, y)
#若权重为None,则赋值权重为n_samples的长的向量
if sample_weight is None:
sample_weight = np.ones(n_samples)
# Logistic loss is the negative of the log of the logistic function.
out = -np.sum(sample_weight * log_logistic(yz)) + .5 * alpha * np.dot(w, w)
z = expit(yz)
z0 = sample_weight * (z - 1) * y
grad[:n_features] = safe_sparse_dot(X.T, z0) + alpha * w
# Case where we fit the intercept.
if grad.shape[0] > n_features:
grad[-1] = z0.sum()
return out, grad_intercept_dot: Computes yz=y * np.dot(X, w),c是截距。
log_logistic:Compute the log of the logistic function, ``log(1 / (1 + e ** -x))``
expit:也称为logistic sigmoid函数,定义为expit(x)= 1 /(1 + exp(-x))。 它是logit函数的反函数。log_logsitic与expit具有相同的方式,expit更加普遍。
3.权重赋值解读
sklearn里的逻辑回归给每一个样本赋权是作用在“损失函数”上,在计算log_logistic(yz)时乘以sampleweighs使得每个样本赋予上相应的权重,最后进行加总求和。同时在计算梯度时,也会用到sample_weight,梯度本质上是多元函数求偏导,其中safe_sparse_dot(X.T, z0)计算此时的梯度。
二、sklearn.linear_model.LogisticRegression() 方法
1.调用方法
clf_class_weight = LogisticRegression(class_weight='balanced').fit(X, y)2.底层逻辑

@_deprecate_positional_args
def compute_class_weight(class_weight, *, classes, y):
"""Estimate class weights for unbalanced datasets.
Parameters
----------
class_weight : dict, 'balanced' or None
If 'balanced', class weights will be given by
``n_samples / (n_classes * np.bincount(y))``.
If a dictionary is given, keys are classes and values
are corresponding class weights.
If None is given, the class weights will be uniform.
classes : ndarray
Array of the classes occurring in the data, as given by
``np.unique(y_org)`` with ``y_org`` the original class labels.
y : array-like, shape (n_samples,)
Array of original class labels per sample;
Returns
-------
class_weight_vect : ndarray, shape (n_classes,)
Array with class_weight_vect[i] the weight for i-th class
References
----------
The "balanced" heuristic is inspired by
Logistic Regression in Rare Events Data, King, Zen, 2001.
"""
# Import error caused by circular imports.
from ..preprocessing import LabelEncoder
if set(y) - set(classes):
raise ValueError("classes should include all valid labels that can "
"be in y")
if class_weight is None or len(class_weight) == 0:
# uniform class weights
weight = np.ones(classes.shape[0], dtype=np.float64, order='C')
elif class_weight == 'balanced':
# Find the weight of each class as present in y.
le = LabelEncoder()
y_ind = le.fit_transform(y)
if not all(np.in1d(classes, le.classes_)):
raise ValueError("classes should have valid labels that are in y")
recip_freq = len(y) / (len(le.classes_) *
np.bincount(y_ind).astype(np.float64))
weight = recip_freq[le.transform(classes)]
else:
# user-defined dictionary
weight = np.ones(classes.shape[0], dtype=np.float64, order='C')
if not isinstance(class_weight, dict):
raise ValueError("class_weight must be dict, 'balanced', or None,"
" got: %r" % class_weight)
for c in class_weight:
i = np.searchsorted(classes, c)
if i >= len(classes) or classes[i] != c:
raise ValueError("Class label {} not present.".format(c))
else:
weight[i] = class_weight[c]
return weight3.权重解读
np.bincount(y):每个bin给出了它的索引值在x中出现的次数
# 我们可以看到x中最大的数为7,因此bin的数量为8,那么它的索引值为0->7
x = np.array([0, 1, 1, 3, 2, 1, 7])
# 索引0出现了1次,索引1出现了3次......索引5出现了0次......
np.bincount(x)
#因此,输出结果为:array([1, 3, 1, 1, 0, 0, 0, 1])
- 如果class_weight is none,则赋予weight为np.ones(classes.shape[0]),代表样本之间唯有类别权重;
- 如果class_weight ==‘balanced’,则会平衡类别之间的权重,公式为:
recip_freq = len(y) / (len(le.classes_) *
np.bincount(y_ind).astype(np.float64))
weight = recip_freq[le.transform(classes)]公式本质上为加权分配样本权重,样本数n与类别数classes的比例可以看作是若是均分,每个类别应该是多少样本,同时再用这个“均值”除以该类别下的实际样本量,若该样本量小于“均值”,意味着,该类别下的样本比平均分配下的样本数要小,则应该赋予更大的权重;若该样本量大于“均值”,意味着,该类别下的样本比平均分配下的样本数要大,则应该赋予更大的权重。这样分配之后每类的“样本数”应该等于样本数n与类别数classes比例(均值)。
- 若为用户自定义字典类型,先判断用户给到的字典里的class是否存在于y的类别中,若不存在则报错,否则将字典里class对应的weight_value赋值给weight列表。
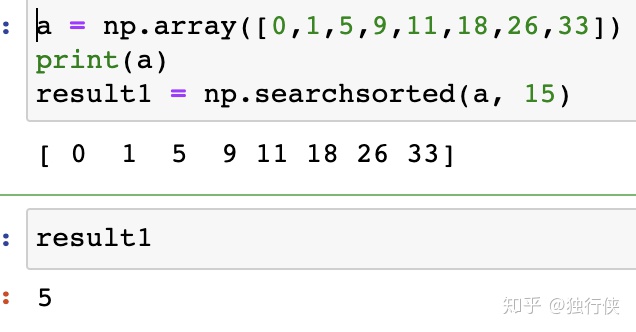
np.searchsorted(a, v, side='left', sorter=None):在数组a中插入数组v(并不执行插入操作),返回一个下标列表,这个列表指明了v中对应元素应该插入在a中那个位置上
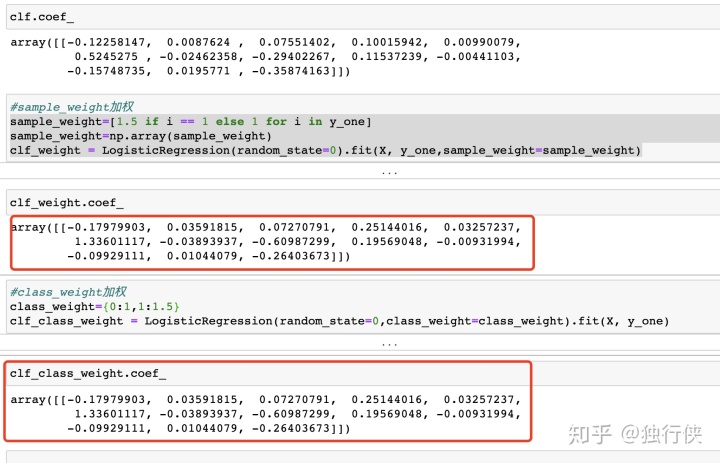
4.class_weight和sample_weight的区别和联系:
class_weight主要针对样本label的加权,而sampleweight则主要针对某些样本进行加权,不一定是按照label变量进行加权,可以是其他特殊的字段。若class_weight和sample_weight一起使用,则是class_weight*sample_weight的效果。若sample_weight是对label变量进行加权,则和calss_weight达到的效果一致。
5.而在statsmodel包中对逻辑回归没有权重计算,具体见下章。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









