






我们无论在何时分析数据,第一件要做的事情就是观察它。对于每个变量,哪些值是最常见的?值域是大是小?是否有不寻常的观测?R中提供了丰富的数据可视化函数。
直方图通过在x轴上将值域分割为一定数量的组,在y轴上显示相应值的频数,展示了连续型变量的分布。
今天来学习绘制直方图。
目 录
1. 加载数据集
2. 简单茎叶图
3. 简单直方图
4. 美化图形
5. 添加正态分布曲线
6. 复杂直方图
6.1 堆叠直方图
6.2 非堆叠直方图
7. lattice绘制直方图
8. hist()函数
9. histStack()函数
10. Hist()函数
1. 加载数据集
本篇推文选用的是multcomp包的sbp数据集。
install.packages("multcomp") # 安装包
library(multcomp) # 加载包
data(sbp) # 加载内置数据集
View(sbp) # 预览数据集
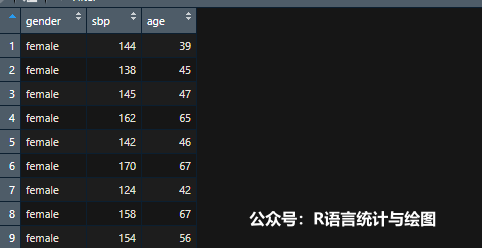
数据集包括3个变量(收缩压、年龄、性别),共69个观测对象。
2. 简单茎叶图
我们先绘制个茎叶图来观察血压的分布,使用stem()函数来绘制茎叶图。
stem(sbp$sbp)
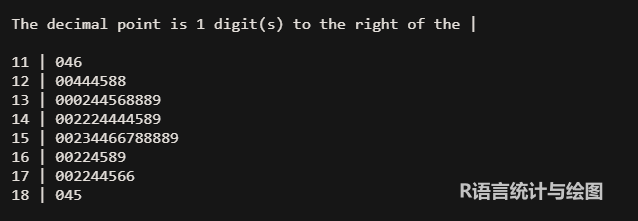
图上显示了数据集中所有的血压,血压都是三位数字,茎叶图的主干包含2位数字,图上左边的两位数字表示主干,"叶"包含每个数字的最后一位数字。第一行的3个数字为110、114、116。
图上血压分布基本近似对称,低血压患者数量和高血压患者数量大致相同。
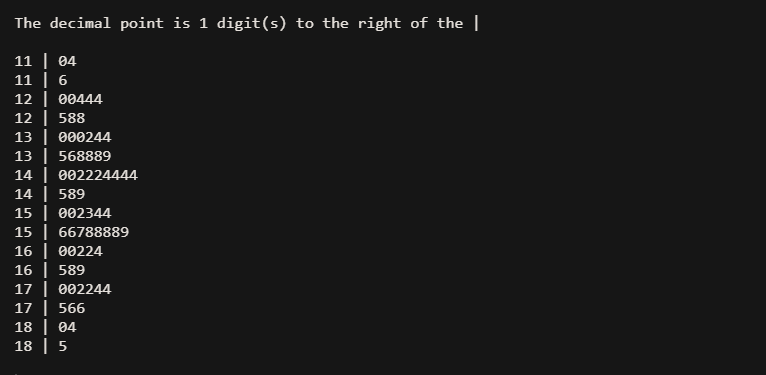
stem(sbp$sbp, scale = 2) # 改变茎宽
3. 简单直方图
我们先来绘制简单的直方图。
attach(sbp)
par(mfrow = c(2,2))
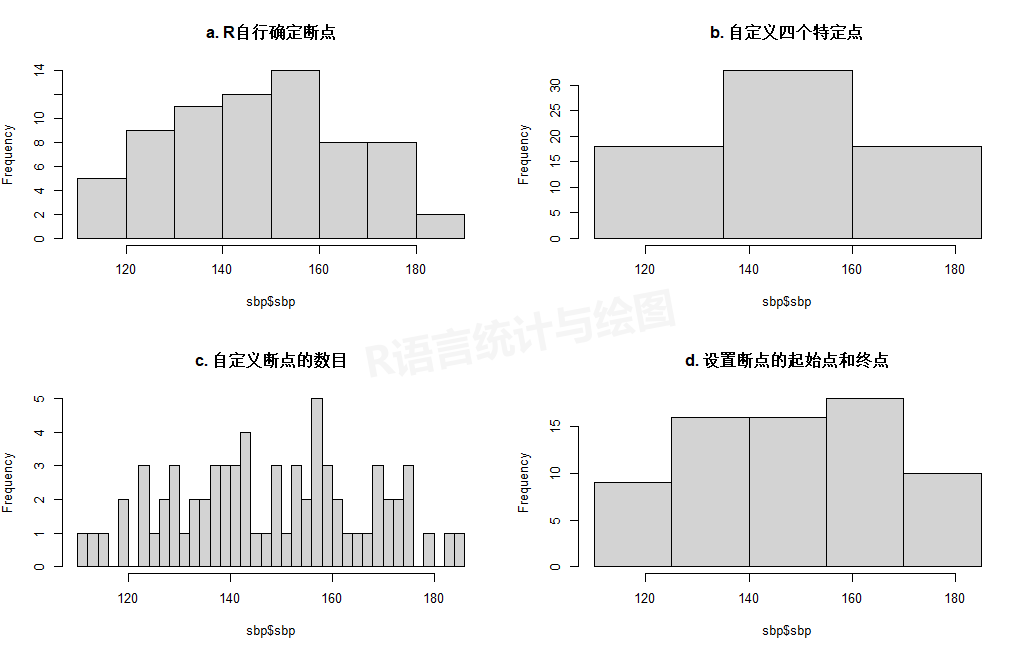
hist(sbp$sbp, main = "a. R自行确定断点")
hist(sbp$sbp, main = "b. 自定义四个特定点",
breaks = c(110,135,160,185))
hist(sbp$sbp, main = "c. 自定义断点的数目",
breaks = 30)
hist(sbp$sbp, main = "d. 设置断点的起始点和终点",
breaks = seq(110,190,15))
detach(sbp)
4. 美化图形
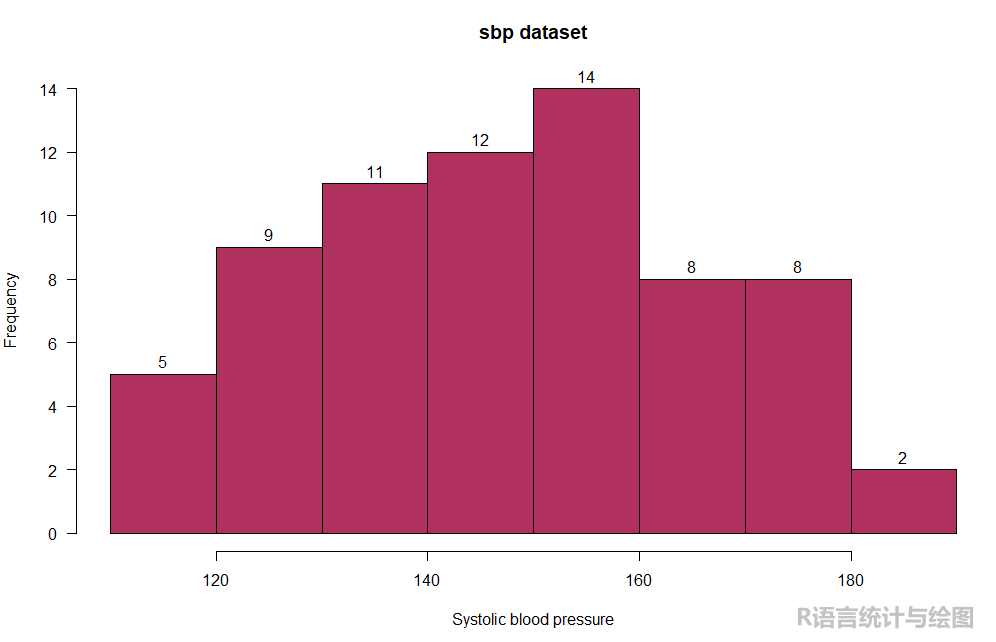
自定义一些参数来美化图形。
hist(sbp$sbp, # 绘图数据
main = "sbp dataset", # 设置图形标题
las = 1, # 翻转y轴上面的数字,使其直立而不是侧立
label = T, # 直方图上面添加数据标签
col = "maroon", # 设置直方图颜色
xlab = "Systolic blood pressure") # 添加x轴标签
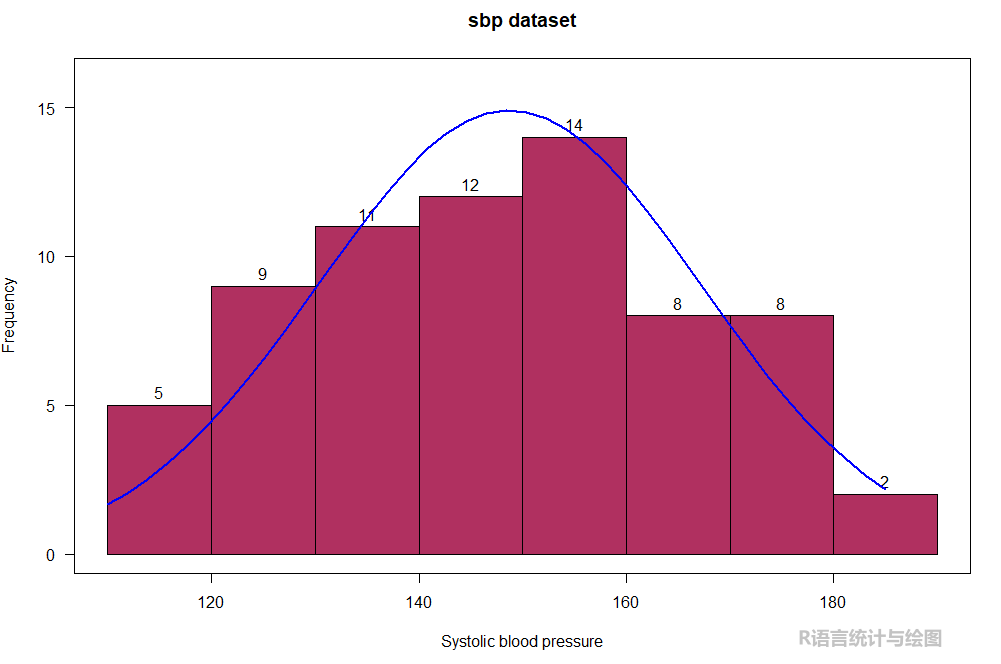
5. 添加正态分布曲线
x # 将绘图数据传递给x
h # 绘图数据
main = "sbp dataset", # 设置图形标题
las = 1, # 翻转y轴上面的数字,使其直立而不是侧立
label = T, # 直方图上面添加数据标签
col = "maroon", # 设置直方图颜色
ylim = c(0,16), # 设置y轴范围
xlab = "Systolic blood pressure") # 添加x轴标签
xfit40)
yfityfit 1:2])*length(x)
lines(xfit, yfit, col="blue", lwd=2) # 添加正态分布曲线
box() # 图形周围加个框框
6. 复杂直方图
6.1 堆叠直方图
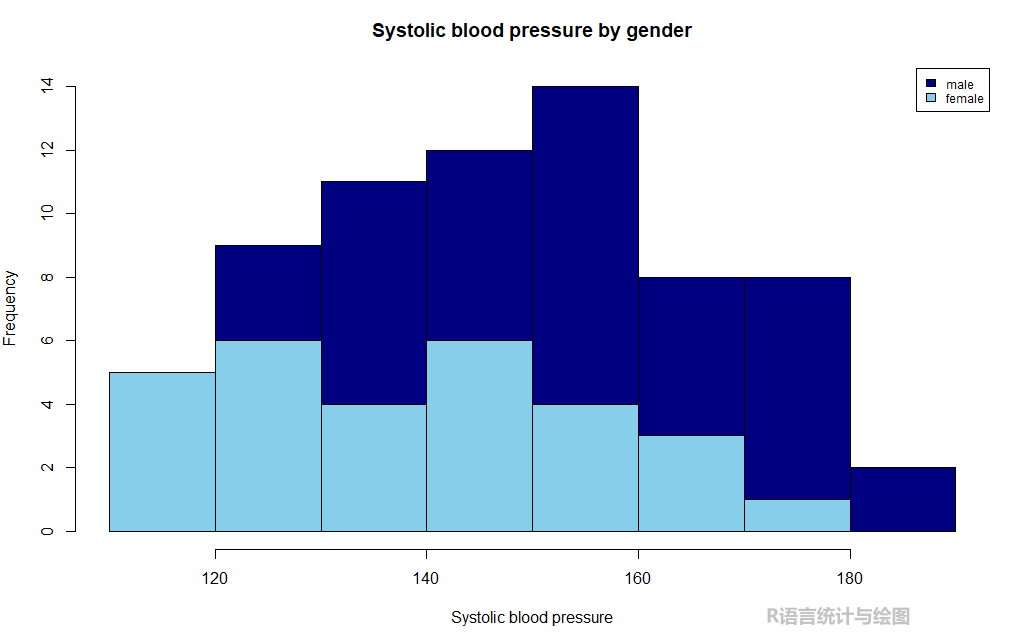
在上面的数据集中,有时候我们需要研究性别与收缩压之间的关系,想知道不同性别之间的血压分布是否相似还是不同。我们可以使用堆叠的直方图来显示数据分布,plotrix包的histStack()函数实现。
library(plotrix) # 加载包
library(multcomp) # 加载包
histStack(sbp$sbp, # 绘图数据
z = sbp$gender, # 分组变量
col=c("navy","skyblue"), # 设置直方图颜色
main = "Systolic blood pressure by gender", # 设置标题
xlab = "Systolic blood pressure", # 设置x轴标签
legend.pos = "topright") # 设置图例位置
6.2 非堆叠直方图
如果我们不想使用堆叠的方式显示直方图,可以使用并排或者分开的方式排布。
可以使用RCmdrMisc包的Hist()函数来实现。
install.packages("RcmdrMisc") # 安装包
library(RcmdrMisc) # 加载包
library(multcomp) # 加载包
Hist(sbp$sbp, # 绘图数据
groups = sbp$gender, # 分组数据
main = "Systolic blood pressure by gender", # 添加标题
col = "navy ", # 设置颜色
xlab = "Systolic blood pressure") # 设置x轴标签
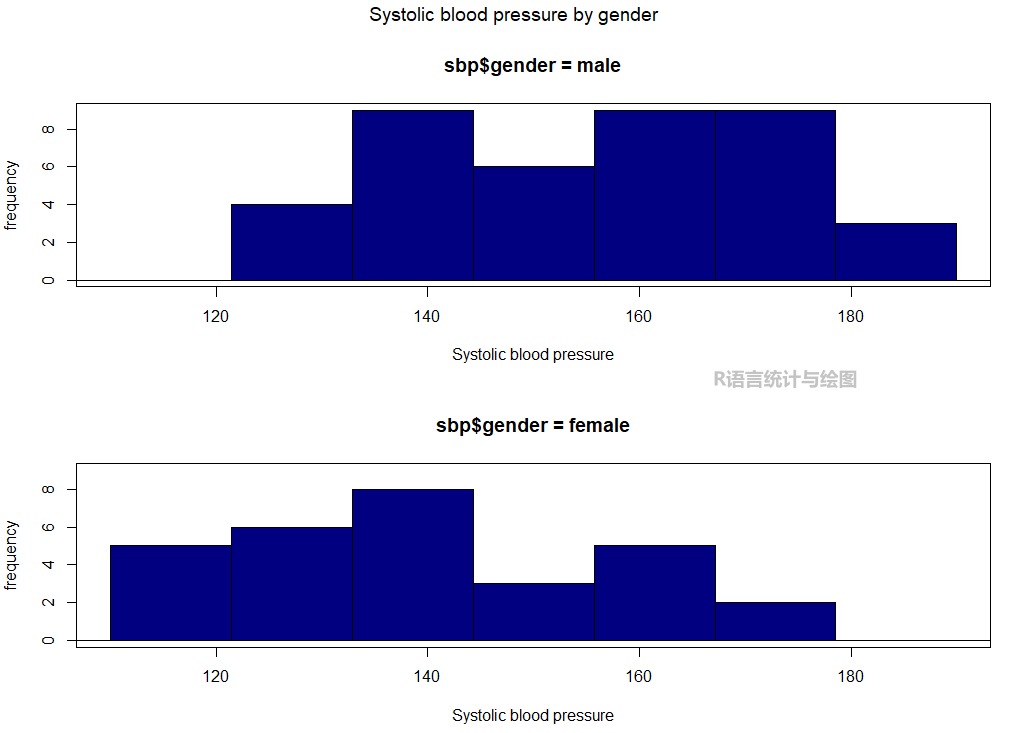
如上图所示,我们可以看出男性血压整体要比女性高些。
7. lattice绘制直方图
Hist()函数适用于少量的分组,当分组数量很大就不是很方便了,此时可以使用lattice包来绘制图形。
car包的Salaries数据集包含了2008-2009年美国一所大学教授们的9个月薪水数据,可以用来比较男性与女性薪水之间的差异。
install.packages("lattice") # 安装包
install.packages("car") # 安装包
library(lattice) # 加载包
library(car) # 加载包
head(Salaries) # 显示数据集前6行
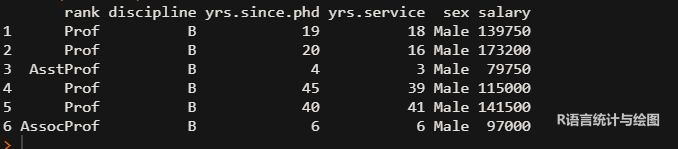
数据集中包含了等级(rank)和性别(sex)两个分组变量,还有薪水这个连续变量,现在根据这两个分组变量来生成一组直方图。
histogram(~ Salaries$salary | Salaries$rank * Salaries$sex,
type = "count", main = "Faculty Salaries by Rank & Gender")
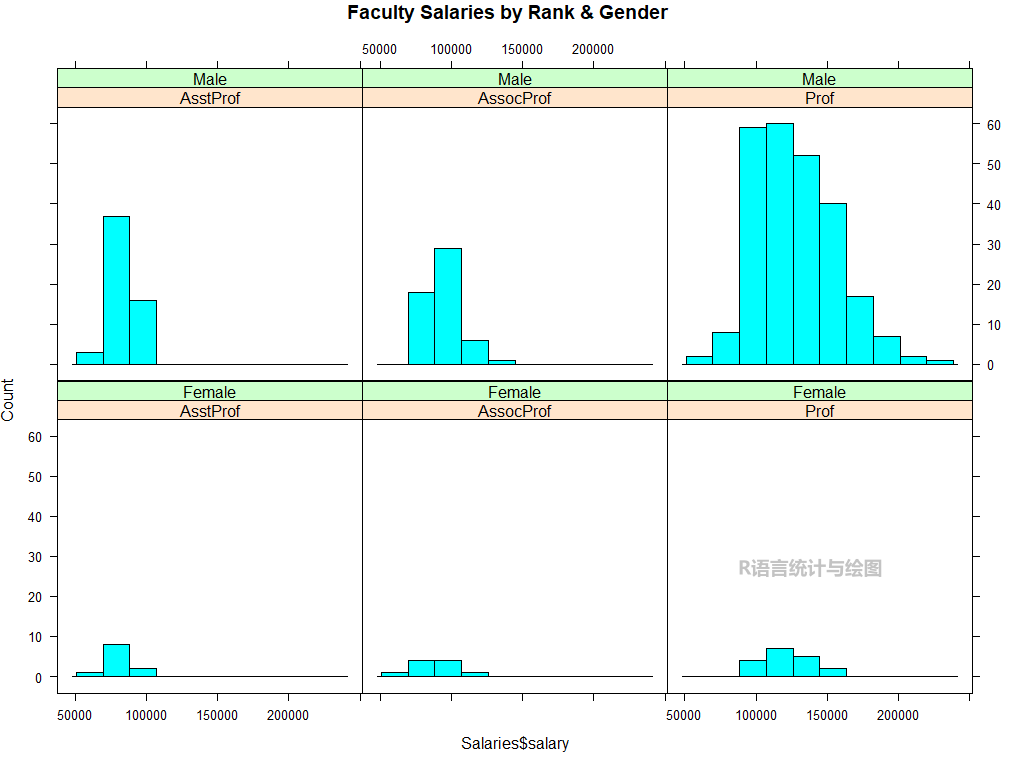
如上图所示,我们试着分析以下上面的数据,首先,图形上面为男性,下面为女性,可以知道研究数据集中男性数量比女性要多;
图形左边为副教授或助理教授,右边为教授,数据集中教授人数又要多很多。
最后看薪水,各个职位的男性和女性的薪水分布的中位数差不多,但在教授和副教授中,男性薪水最高。
8. hist()函数
hist(x, breaks = "Sturges",
freq = NULL, probability = !freq,
include.lowest = TRUE, right = TRUE,
density = NULL, angle = 45, col = "lightgray", border = NULL,
main = paste("Histogram of" , xname),
xlim = range(breaks), ylim = NULL,
xlab = xname, ylab,
axes = TRUE, plot = TRUE, labels = FALSE,
nclass = NULL, warn.unused = TRUE, ...)
## 部分参数解释
x # 用来绘制直方图的数字向量
breaks # 规定直方图的组距
# 可以为向量,用来定义直方图条形之间的断点
# 也可以是函数,用来计算断点向量
# 也可以直接就是一个数值,用来表示条形的数量
freq # 逻辑词,如为TRUE,则绘制频率分布直方图;
# 如为FALSE,则绘制概率密度、成分密度直方图
right # 逻辑词,如为TRUE,则直方图为左开右闭区间
density # 数字,表示直方图中阴影线的密度,默认不绘制阴影线
angle # 阴影线的斜率,用度数表示
col # 填充直方图的颜色,默认不填充颜色
border # 直方图边框的颜色
main # 图形标题
xlim、ylim # 限制x轴和y轴的范围
xlab、ylab # 指定x轴和y轴的标签
axes # 逻辑词,如为TRUE,则绘制坐标轴
labels # 逻辑词和字符串,在直方图上面添加数据标签
9. histStack()函数
histStack(x,z,breaks="Sturges",col="rainbow",
right=TRUE,main="",xlab=NULL,legend.pos=NULL,cex.legend=0.75,...)
## 部分参数解释
x # 用来绘图的定量数据
z # 指定分类变量,用来绘制堆叠直方图
breaks # 设置x值断点的数目
col # 设置图形的颜色,可以是字符串,也可以是包含颜色的向量;
right # 逻辑词,指定直方图数据右边是开区间还是闭区间
main # 指定图形标题的字符串
xlab # 指定x轴标签的字符串
legend.pos # 指定图例的位置
cex.legend # 指定图例的大小
10. Hist()函数
基于base包中hist()函数的封装,功能更为强大。
Hist(x, groups, scale=c("frequency", "percent", "density"), xlab=deparse(substitute(x)),
ylab=scale, main="", breaks = "Sturges", ...)
## 部分参数解释
x # 要绘制直方图的数字向量
groups # 分组创建直方图的因子
scale # 垂直轴的缩放比例:频率(默认);百分比;密度。
xlab,ylab,main # x轴、y轴标签、图形标题
breaks # 设置x轴断点
参考资料
- Graphing Data with R. John Jay Hilfiger著
- [美]Robert I. Kabacoff著. R语言实战(第2版)[M].王小宁等译. 北京:人民邮电出出版社.2016.
- hist()函数帮助文件
- histStack()函数帮助文件
- Hist()函数帮助文件
相关文章
这个浏览器插件可以智能查询SCI论文被引情况
R语言统计与绘图:ROC曲线上32种截断值的计算
R语言统计与绘图:ROC曲线的统计计算
R语言统计与绘图:可视化ROC曲线的置信区间
R语言统计与绘图:绘制平滑ROC曲线
R语言统计与绘图:绘制不同坐标轴置信区间的森林图
R语言统计与绘图:绘制多个置信区间的森林图

分享、点赞、在看,一键三连!















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









