






物体识别
物体识别主要包括物体的定位与分类。物体识别需要解决的主要问题是提高物体定位和分类的准确度,与此同时,需要提升整个过程的处理速度。最近发表的物体识别网络结构,如,R-CNN系列、R-FCN、YOLO、SSD等对此做出了很大的贡献,无论是准确性还是速度都得到了较大的提升。下面,对这些方法的主要思想以及网络结构进行简要介绍。
=======================================================
R-CNN
Region-based Convolution Network
基于region proposal的R-CNN系列目标检测方法是当前目标检测技术领域最主要的一个分支。
Structure
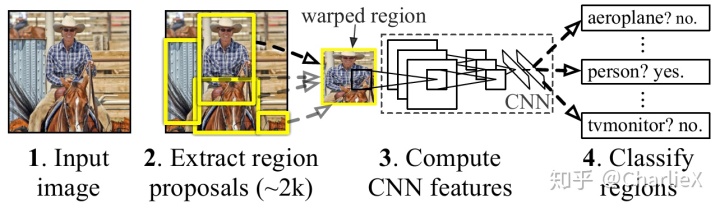
- 输入图像
- 通过相应算法(比如,selective search算法)提取大约2000个区域,然后将区域变换到统一的大小。
- 使用一个较大的卷积神经网络计算每一个区域的特征。
- 使用分类专用的线性SVM和边框回归算法对每一个区域进行分类。
Fixed-size constraint comes only from the fully-connected layers.
Region proposal
To generate category-independent regoin proposals.
Examples:
- Objectness
- Selective search
- Category-independent object proposals
- Constrained parametric min-cuts (CPMC)
- Multi-scale combinatorial grouping
- Regularly-spaced square crops with CNN
缺陷
- 训练过程是一个多通道的过程,这些通道没有进行特征的共享,也就是说每一个区域都需要进行一次特征的计算,而这些特种会有相当程度的重复。
- 训练过程是十分耗费存储空间与计算时间的。
- 物体检测过程是十分缓慢的。
=======================================================
Fast R-CNN
Structure
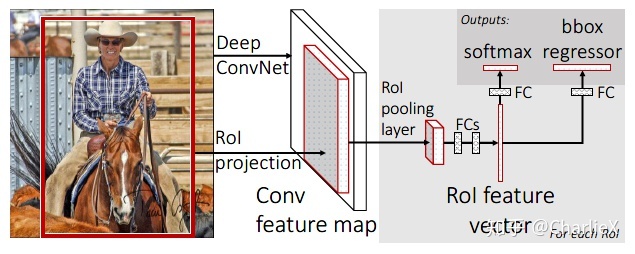
- 输入整个图像和目标所在的可能区域。
- 对整张图像进行特征的计算,得到feature map。
- 从feature map中通过pooling层对感兴趣区域提取一个固定长度的特征向量。
- 每一个特征向量输入到一系列的全连接层,最后并行产生分类的输出以及位置边框。
SPPnets
Spatial pyramid pooling networks
由于全连接网络需要一个固定尺度的输入,所以每个区域的特征需要通过一定的变换得到固定长度的向量。通常的做法是直接进行裁剪或者拉伸(crop/warp)

但是,直接的裁剪可能导致特征的丢失,而拉伸可能会导致图像的扭曲

Fast R-CNN创新性的使用了SPPnets池化层,它不仅可以产生固定尺度的特征向量,与此同时,还通过金字塔式的池化保持了空间信息。

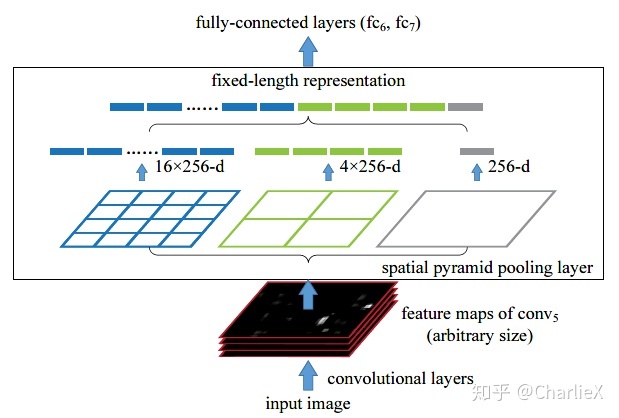
缺点
- 尽管特征得到了共享,但是候选框的选择性搜索也是十分耗时的。
=======================================================
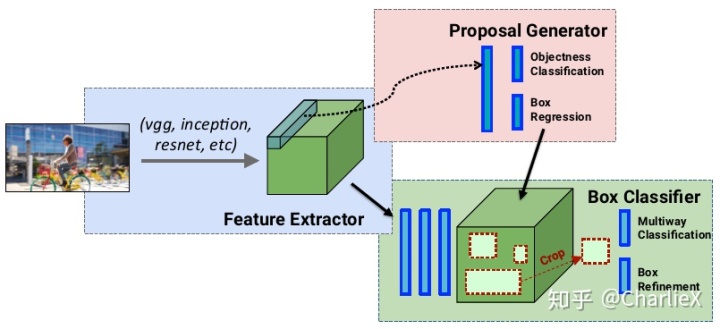
Faster R-CNN
Faster R-CNN is a single, unified network for object detection.
Two modules/subnetworks

- Deep fully convolutional network that proposes regions ->Proposal Generator
- Fast R-CNN detector ->Box Classifier
Structure
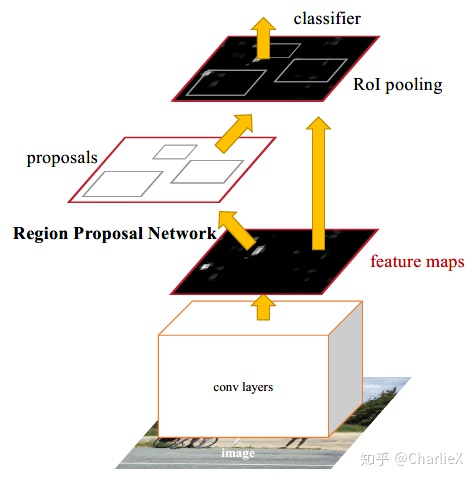
- 输入整个图像。
- 通过卷积层对整个图像进行特征计算,获得feature map。
- 在feature map上通过RPN网络(Region Proposal Networks)进行候选框的计算,得到候选框。
- 对每个候选框里的特征进行分类与位置的回归。
The RPN module serves as the 'attention', which tells the Fast R-CNN module where to look.
RPN结构
Region Proposal Networks
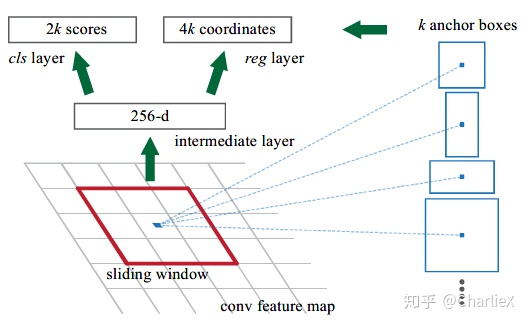
为了产生候选框,在通过卷积得到的共享的特征图上滑动一个小网络(Small Network),小网络的输入可以是任意大小,然后变换到一个低维的特征,在输出到并行的全连接网络分别进行分类与位置回归。
Input : An image of any size.
Output: A set of rectangular object proposals + objectness score.
Small network:
- Take an n*n spatial window as input.
- Each sliding window is mapped to a lower-dimensional feature.
- This feature is fed into two sibling fully-connected layers.
Anchor:
The k proposals are parameterized relative to k reference boxes, which we call anchors.
缺陷
- 针对特定区域的组件(Small Network)对一张图像应用上百次,这是十分耗时的。
=======================================================
R-FCN
Object Detection Region-based Fully Convolutional Networks
矛盾
Increasing translation invariance for image classification vs. repecting translation variance for object detection.
Translation invariance
当卷积网络变深后最后一层卷积输出的feature map变小,物体在输入上的小偏移,经过N多层pooling后在最后的小feature map上会感知不到,also, 网络变深平移可变性变差。
Translation variance
ResNet的结构较深,平移可变性较差,检测出来的坐标会极度不准确。如果在ResNet中间添加ROI层提取出proposals,分类loss对proposal的位置变得敏感,also,ROI层给深层网络带来了平移可变性。
为了解决图像分类所需要的平移不变性和目标检测的平移可变性之间的矛盾,最近,又提出了R-FCN网络。
Two subnetworks
Architecture
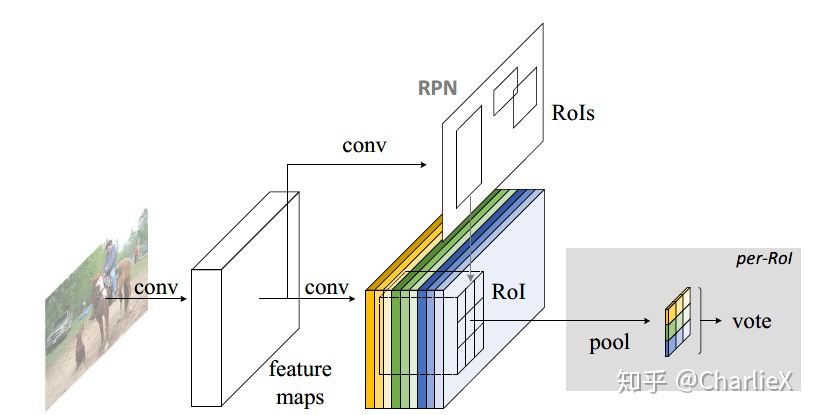
与以往不同的是,特征图的裁剪不是在候选框预测完成的时候进行,而是在预测之前的最后一层上进行。与此同时,R-FCN通过天剑添加Position-Sensitive Score Map 来加强结构的可变性。
Position-sensitive score maps
一系列的Position-Sensitive Score Map 由一些特殊的卷积层产生,并且在FCN的最顶层,施加一个Position-Sensitive RoI pooling layer来驱动这些信息。
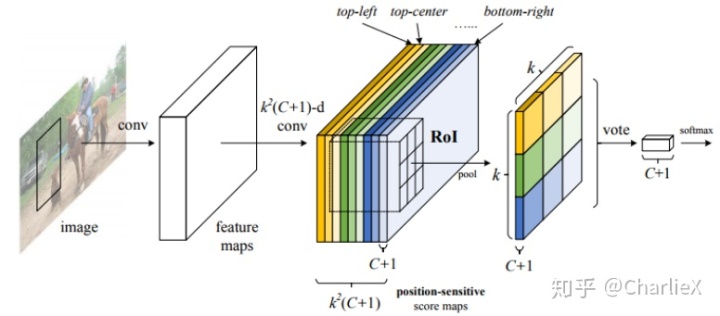
目标的分类->multiway calssfication
卷积生成k^2 * (C+1)维(层)的Position-sensitive score maps, 其中的C是要分类的类别数,加上1(背景分类);k为ROI Pooling中对ROI区域要划分的小格数,如k=3就是对ROI在长宽方向各三等分形成9个小区域。9个小区域并不是在所有k^2 * (C+1)维度上都做pooling,每个小区域只会在对应的(C+1)个维度上作pooling,如ROI左上角的区域就在前C+1个维度上pooling,左中位置的区域就在C+2到2C+2间的维度上作pooling,以此类推。pooling后输出的是C+1维度的k*k数据,每个维度上的k*k个数据再vote(相加)形成C+1个单点数据,代表C+1个类别的分类概率。
目标定位->box refinement
卷积生成k^2*4维(层)的Position-sensitive score maps, 其中的C是要分类的类别数,加上1(背景分类);k为ROI Pooling中对ROI区域要划分的小格数,如k=3就是对ROI在长宽方向各三等分形成9个小区域。k*k个小区域并不是在所有k^2*4维度上都做pooling,每个小区域只会在对应的4个维度上作pooling,如ROI左上角的区域就在前4个维度上pooling,左中位置的区域就在5到8间的维度上作pooling,以此类推。pooling后输出的是4维度的k*k数据,每个维度上的k*k个数据再vote(相加)形成4个单点数据,表示k*k个小区域的[dx,dy,dw,dh]4个偏移坐标。
About R-FCN
=======================================================
YOLO
You Only Look Once
YOLO(You Only Look Once)是一种单个的卷积网络,能够同时预测多个候选框以及相应的类别可能性。
Overall
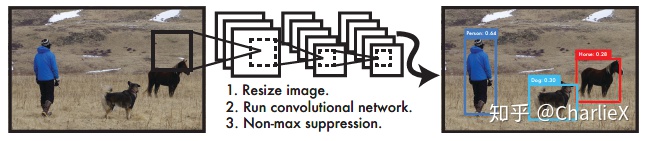
A single convolutional network simultaneously predicts multiple bounding boxws and class probablities for those boxes.
Reframe object detection as a single regression problem, straight from image pixels to bounding box coordinates and class probabilities.
Benefits
- Fast.
- Reason globally about the image, so make less background errors.
- Learn generalizable representations.
Unified model
- 将输入的图像分为SXS个网格。
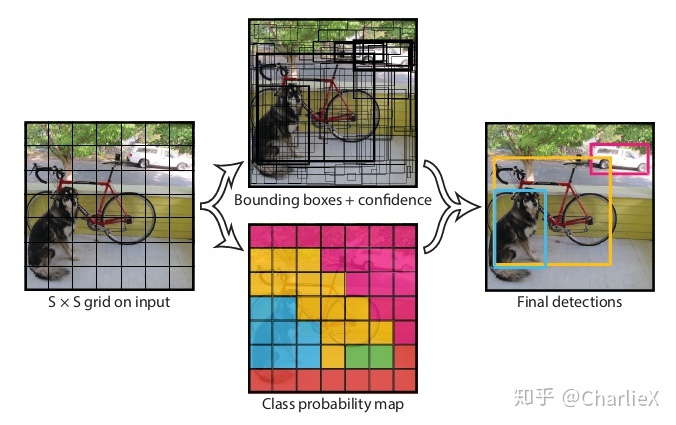
- 对每一个网格单元的B种类型的候选框进行预测,产生4个位置预测值x,y,w,h和1个confidence。
- 对每一个网格单元进行种类的预测,产生C个(C类)概率值。

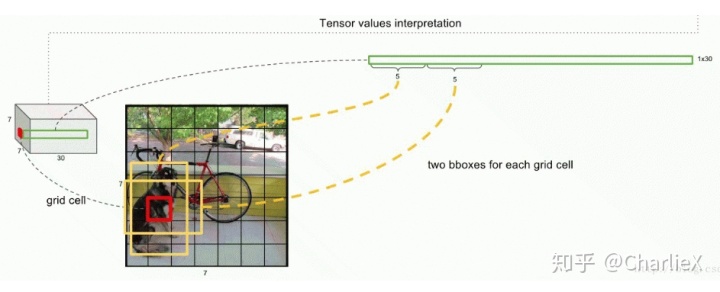
- 这些预测值编码形成一个大小S*S*(B*5+C)的张量。
- 用形成的张量进行位置的探测和种类的预测。
整体架构
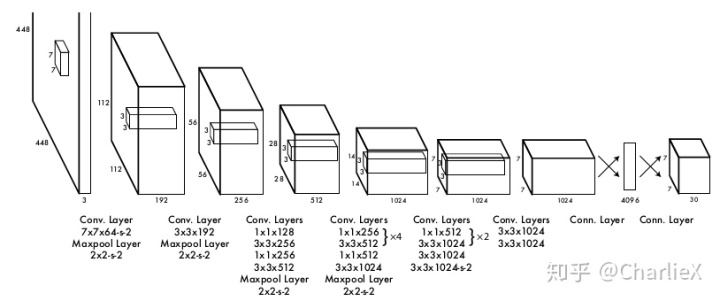
Detection network has 24 convolutional layers followed by 2 fully connected layers.
About YOLOv1
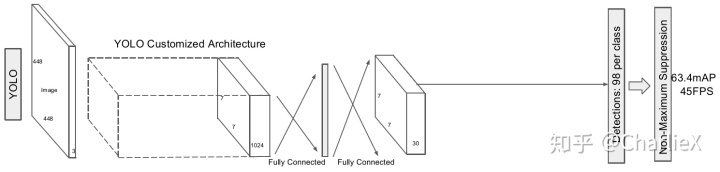
Drawback
- 对于小目标的训练不充分,检测效果差。
- 对于目标的尺度比较敏感,而且对于尺度变化较大的物体泛化能力比较差。
=======================================================
SSD
Single shot multibox detector
Overall
Architecture
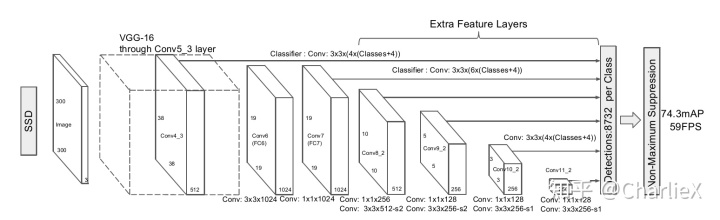
SSD(Single Shot multibox Detector)网络由两部分组成,基本网络(Base network )和辅助结构(Auxiliary structure)。
Base network -> standard architecture used for high quality image classification(裁掉分类层).
Auxiliary structure -> to produce detections.
SSD网络中分为了6个stage,每个stage能学习到一个特征图,然后进行边框回归和分类。SSD网络以VGG16的前5层卷积网络作为第1个stage,然后将VGG16中的fc6和fc7两个全连接层转化为两个卷积层Conv6和Conv7作为网络的第2、第3个stage。SSD网络继续增加了Conv8、Conv9、Conv10和Conv11四层网络,用来提取更高层次的语义信息。
每个stage都能学习到一个特征图,然后用这些特征图共同进行边框的回归和物体的分类。
Multi-scale feature maps
额外的特征层(Extra feature layers)大小逐步的减小,允许更多尺度的特征的产生,SSD可以充分利用不同网络层的信息来模拟不同尺度下的图像特征来辅助预测。
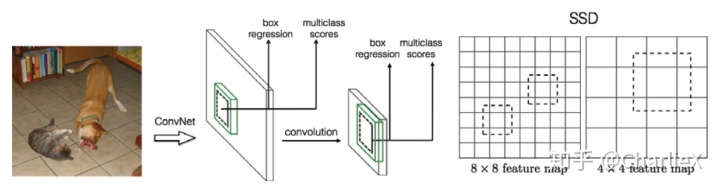
More default boxes
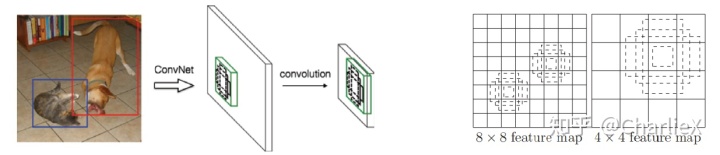
Compare

About SSD
=======================================================
参考文献:
- Girshick R, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2014:580-587.
- Huang J, Guadarrama S, Murphy K, et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors[J]. 2016:3296-3297.
- Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// International Conference on Neural Information Processing Systems. MIT Press, 2015:91-99.
- Girshick R. Fast R-CNN[J]. Computer Science, 2015.
- He K, Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 37(9):1904-16.
- Dai J, Li Y, He K, et al. R-FCN: Object Detection via Region-based Fully Convolutional Networks[J]. 2016.
- Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox Detector[C]// European Conference on Computer Vision. Springer, Cham, 2016:21-37.
- Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[J]. 2015:779-788.
=======================================================
附录:
迁移学习
Transfer learning,运用已经在大数据集上训练好的模型,比如Alexnet,Googlenet,VGGnet,ResNet等等。
数据集太小,直接进行训练很容易出现过拟合现象。先在一个大数据集中训练以提取比较准确的浅层特征,然后再针对这个训练过的网络利用我们的数据集进行训练,那么效果就会好很多。
Fine-tune
微调,迁移学习的一部分。
针对训练过的网络利用已有的较小数据集进行训练。
- 修改模型参数。修改最后一层的输出类别,将原来的输出类别修改为已有数据集的类别;确定要训练的层,将不需训练的层设为FALSE。
- 载入模型权重,仅载入不需训练的层的权重。
- 准备训练数据和测试数据。
- 模型重新训练与权重参数的存储。
Tensorflow, Finetuning, VGGNet
Example
- Unsupervised pre-training, followed by supervised fine-tuning.
- Supervised pre-training on a large auxiliary dataset (e.g. ILSVRC), followed by domain-specific fine-tuning on a small dataset (e.g. PASCAL).
PASCAL, pattern analysis,statistical modelling and computational learning. 训练集由一套图像组成:每个图像拥有一个对应的标注文件,给出了图像中出现的物体的bounding box和class label,该物体属于20类中的某一类。同一张图像中,可能出现属于多个类别的多个物体。主要用于分类、检测与分割。















 1050
1050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









