






本系列主要围绕集成学习中的bagging、boosting思想,涉及常用的算法思路与对比。纯干货,可用作面试笔记,旨在完整体现整个算法思路与实用推导过程。
一、bagging的基本思路
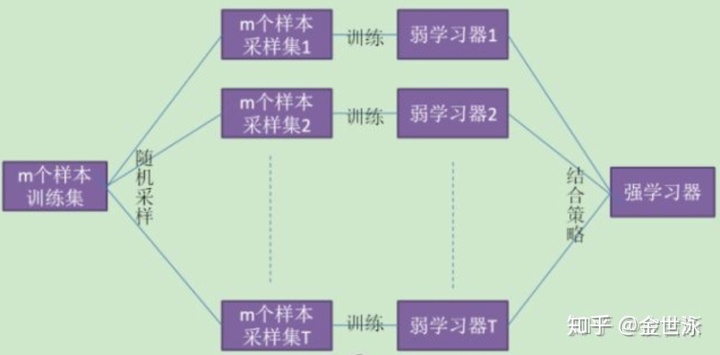
bagging的思路是训练k个独立的基学习器,对于每个基学习器的结果进行结合(加权或者多数投票)来获得一个强学习器。故在此有三个问题需要解决:
- 如何构造独立的弱分类器
- 如何构造基学习器
- 结合策略是什么
在此我们一一进行解答。
1. 如何构造“独立”
想要获得泛化能力强的集成,就需要集成中的个体学习器经可能地独立,但独立很难构造,故我们经可能地使基学习器之间差异较大。
在此bagging使用了boostrap的思想,从m个样本的训练集中有放回地抽取m次,获得第一个样本集,用于训练第一个基学习器,以此类推可获得k个样本集供基学习器训练。由于训练数据不同,我们获得的基学习器会有很大的差异。
使用boostrap还有另一个好处:虽然我们希望基学习器之间的差异经可能地大,但每个个体学习器的能力也不能太差,因而我们希望所有的基学习器总体上能经可能地用到所有数据,来进行有效的学习。我们希望不同的样本集之间是交叠的,boostrap恰好满足了这一点。
2.基分类器的选取
bagging要求基分类器对样本分布敏感,常用的基分类器为决策树、神经网络。KNN、线性分类器由于过于“稳定”不适合作为基分类器。
- 树的节点分裂随机选择特征子集带来随机性,设定层数来控制泛化;
- 神经网络通过调整神经元数量、连接方式、网络层数、初始权值引入随机性;
2. boostrap带来的“包外估计”
由于使用了boostrap进行训练集的抽取,由于其抽泣方法的特性,会有约0.368的样本未被抽到,此部分样本称为包外样本(记作oobs),可用作测试集,此部分的测试结果称为“包外估计”,为真实误差的无偏估计。(无偏估计待证明)
使用oobs进行泛化误差的包外估计,在二分类情况(取值{+1, -1}):
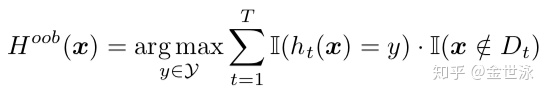
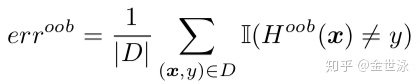
obbs估计等价于k折交叉验证,使用obbs作为测试集能大幅减少计算。
3. 结合策略
对于分类问题,我们使用多数表决;对于回归问题,我们使用平均法。
结合策略是bagging方法控制方差的根源所在!使用多数表决或平均法能有效控制方差
当然也有其他的结合策略。在此,可以,但没必要!
二、 bagging的优势
1.bagging关注于减小预测方差,随着基学习器数量的增加,理论上可以使分类误差降为0。
记每个基分类器的分类误差
总数为T个的集成学习器总分类误差
由Hoeffding inequality,且总分类误差在T取+∞时趋近于0:
2.bagging支持并行计算
三、bagging的算法伪代码(仅作记录)

四、随机森林——bagging的代表
1. 随机森林的优点
- 有效运行于大数据集:来自boostrap的样本随机选取
- 能处理高维特征,且无需降维:来自特征的随机选取
- 能评估各个特征在分类问题上的重要性:来自决策树
- 能够获取到内部生成误差的一个无偏估计:由包外估计提供,来源是boostrap
- 对异常值不敏感:来自boostrap的样本随机选取
- 能够很好地处理缺省(待探究原因):来自决策树
2. 随机森林的缺点
- 容易受噪声影响而过拟合:主要是回归时使用均方误差作为损失函数,易受噪声影响是均方误差的通病
- m取值影响较大
3. 随机森林的训练过程(两个随机)
样本集N,共N个样本;特征集M,共M个特征
(1)样本集N中以boostrap方法抽取k个训练集,每个训练集样本个数为n(第一个随机,随机有放回抽取),且分类误差取决于:
- 每棵树的分类能力:单棵树分类能力越强,分类误差越小
- 树之间的相关性:树之间的相关性越小,分类误差越小
(2)对每个训练集,抽取M个特征中的m个特征(随机无放回抽取):
- M较大时:
;
- M较小时,在M中取L个特征(L<k),用[-1, +1]上的均匀分布来构建权重对L个特征进行线性组合,构成k个特征;
- m越小,相关性越小、分类能力越差;
- 是随机森林唯一的超参(在不考虑树本身的超参前提下),可以使用obb error(out of bag error)进行选择
(3)对某n个样本的训练集,m个特征的特征集进行决策树训练
- 只训练二叉树:减少计算量;方便模型构建
- 无需剪枝:满足差异性;减少计算量
(4)分类问题使用多数表决作为结合策略,回归问题使用取平均机制
4. 一些面试问题
- m = n时,RF等价于CART树
- m越小,模型方差减小,偏差增大,趋近欠拟合;m越大,模型方差增大,偏差减小,趋近过拟合
5. RF调参
RF调参分两部分:一是bagging框架的调参,二是决策树调参
- 调参过程中的主要评判标准:oobs error和AUC
- 详见:scikit-learn随机森林调参小结 - 刘建平Pinard - 博客园















 4401
4401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









