





学术简报

Modeling and simulating of reservoir operation using the artificial neural
network, support vector regression, deep learning algorith
作者:
Di Zhang a , Junqiang Lin a,⁎, Qidong Peng a ,Dongsheng Wang b , Tiantian Yang c ,Soroosh Sorooshian c , XuefeiLiu a , Jiangbo Zhuang a
a State Key Laboratory of Simulation and Regulation of Water Cycle in River Basin,China Institute of Water Resources and Hydropower Research, Beijing, China
b China Renewable Energy Engineering Institute, Beijing, China
cDepartment of Civil and Environmental Engineering, Center for Hydrometeorology and Remote Sensing [CHRS], University of California-Irvine, Irvine, CA, USA
期刊/日期:Journal of Hydrology/2018
文案:聂盼盼排版:聂盼盼校核:潘仁伟Part.1
研究背景
近年来,人工智能模型在水库调度优化领域的研究发展迅速,但仍存在许多不足之处。首先,目前人工智能模型的研究主要集中在一个具体的案例问题(通常是单一的时间尺度或流态)上,缺乏对复杂操作场景(多尺度、多流态)模型的模拟效果的系统对比。其次,深度学习模型作为一种流行的人工智能模型,对时间序列问题有较强的解决能力,但该模型能否有效、准确地解决水库调度问题尚不清楚。第三,参数设置是人工智能建模的关键技术。然而,对不同模型参数的研究和综合比较研究却很少报道。
Part.2
研究方法和目的
本研究采用BP(back propagation)神经网络、支持向量回归 SVR(support vector regression) 技术和LSTM (long - short-term memory)三种人工智能模型,利用近30年的水库运行历史记录,分别按月、日、小时时间尺度模拟水库运行。本研究旨在总结参数设置对模型性能的影响,探讨LSTM模型在水库运行模拟中的适用性。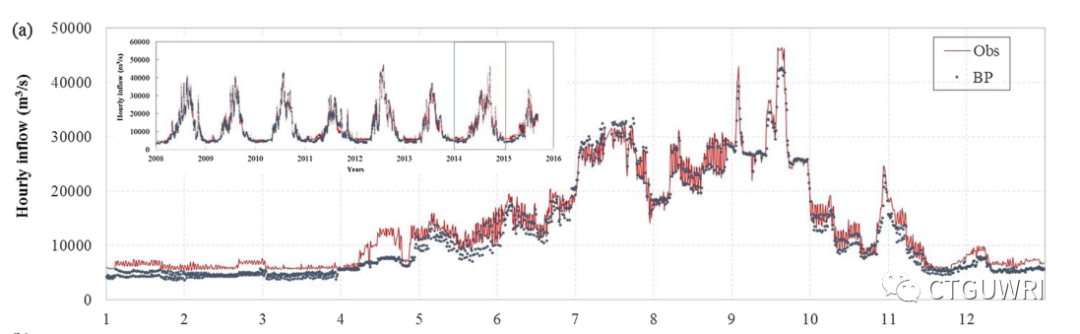
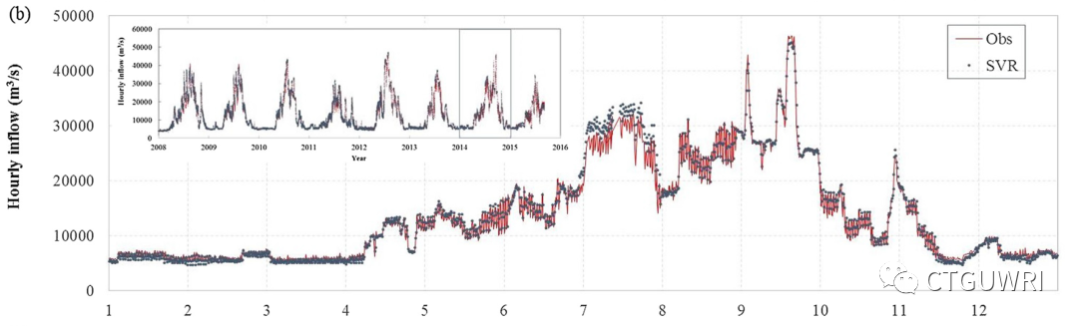
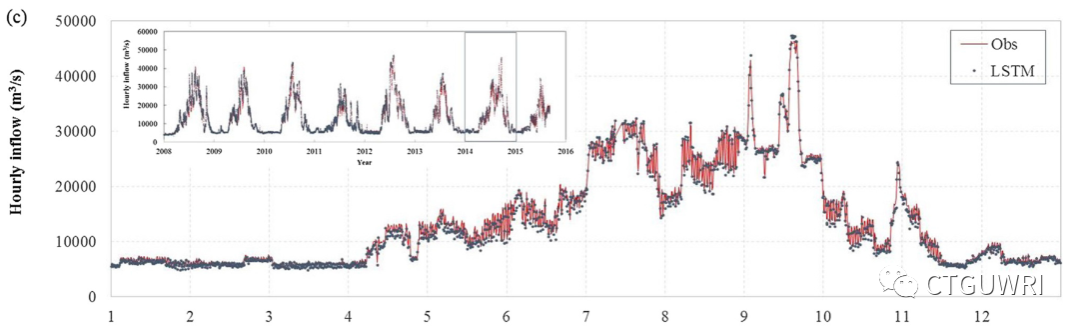
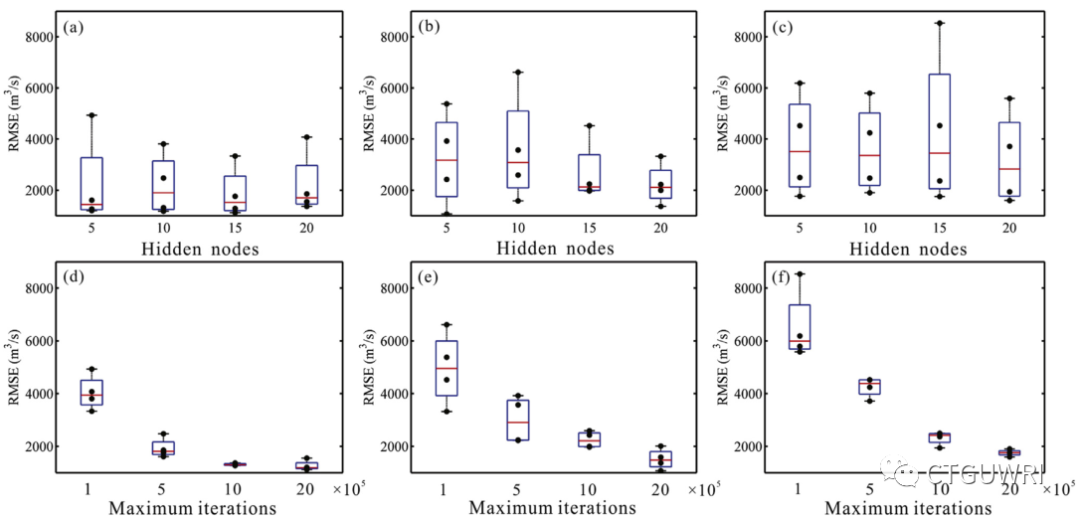
图2 BP神经网络的性能随隐节点数和最大迭代次数的变化而变化。(a)和(d)为每月统计结果;(b)和(e)表示每日统计结果;(c)和(f)表示每小时统计结果
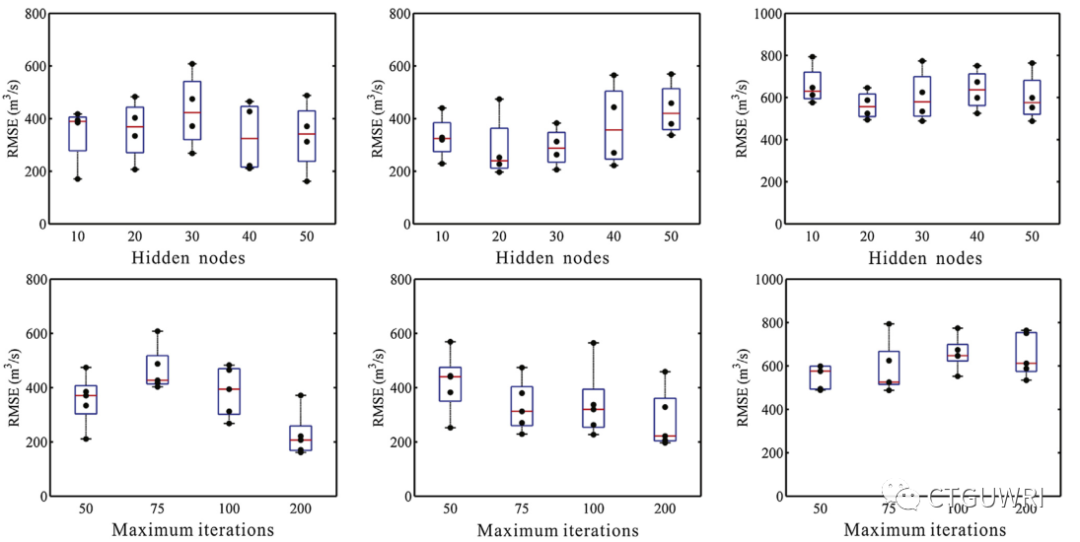
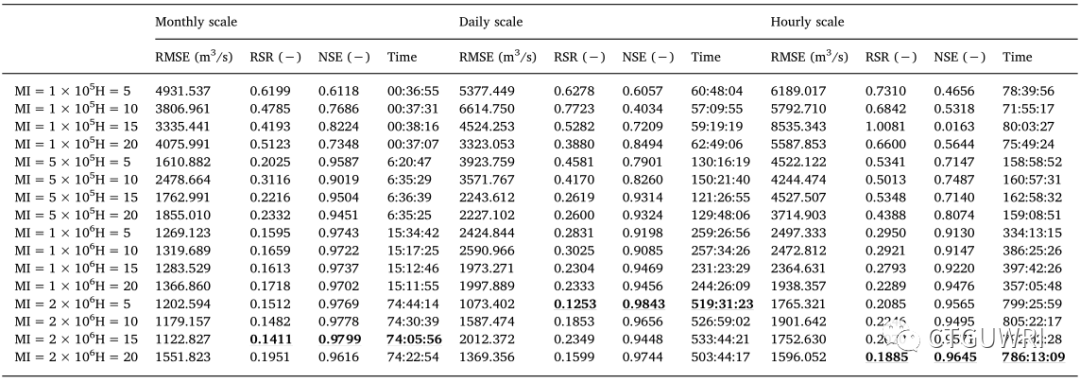
三种模型和三种时间尺度的计算速度有显著差异。总的来说,不同模型之间时间消耗等级为BP神经网络>SVR>LSTM模型。BP神经网络是运行时间最长的模型,随着不同最大迭代(MI)的增加,所消耗的时间会增加。
表2 采用不同核函数的SVR在不同时间尺度上的统计性能,采用不同的结构参数(r)、惩罚系数(C)和多项式度(d)(粗体和下划线的值表示在同一时间范围内的最佳统计数据)
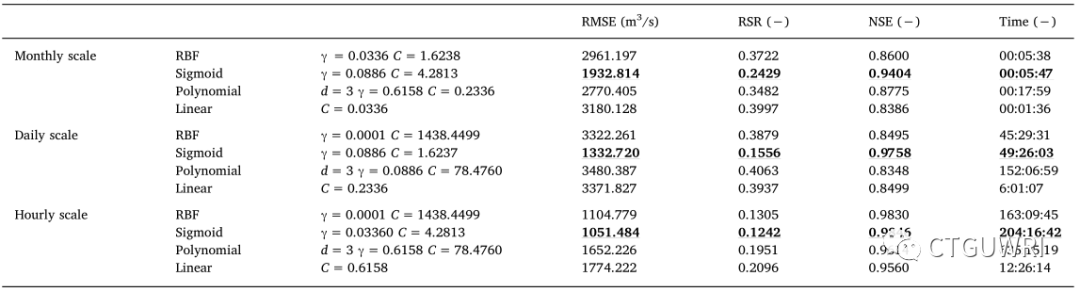
| 时间尺度 | 模拟精度 | |||
| 1 | 2 | 3 | 4 | |
| 月 | Sigmoid | Polynomial | RBF | Linear |
| 日 | Sigmoid | RBF | Linear | Polynomial |
| 小时 | Sigmoid | RBF | Polynomial | Linear |
Part.3
研究结论
(1)对于BP神经网络和LSTM模型,应优先考虑最大迭代次数对模型性能的影响;对于SVR模型,核函数的选择影响模拟性能,应该优先选择sigmoid核函数和RBF核函数;
(2) BP神经网络和SVR适合模型从少量数据中学习水库调度规则;
(3) LSTM模型能够有效降低其他AI模型所需的时间消耗和内存存储,在模拟低流量工况和运行高峰期出流曲线方面表现出良好的能力。
原文链接
https://www.sciencedirect.com/science/article/pii/S0022169418306462


你在看这篇文章吗?















 6009
6009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









