






来自:CSDN,作者:Baldwin_KeepMind 链接:https://blog.csdn.net/shouchenchuan5253/article/details/105196154
一、我的真实经历
标题是我2019.6.28在深圳某500强公司面试时候面试官跟我说的话,即使是现在想起来,也是觉得无尽的羞愧,因为自己的愚钝、懒惰和自大,我到深圳的第一场面试便栽了大跟头。 我确信我这一生不会忘记那个燥热的上午,在头一天我收到了K公司的面试通知,这是我来深圳的第一个面试邀约。收到信息后,我激动得好像已经收到了K公司的Offer,我上网专门查了下K公司的面经,发现很多人都说他们很注重源码阅读能力,几乎每次都会问到一些关于源码的经典问题,因此我去网上找了几篇关于String、HashMap等的文章,了解到了很多关于Java源码的内容。看完后我非常的自信,心想着明天的所有问题我肯定都可以回答上来,心满意足的睡觉。 面试的那天上午,我9点钟到了K公司楼下,然后就是打电话联系人带我上去,在等待室等待面试,大概9:30的时候,前台小姐姐叫到了我的名字,我跟着她一起进入到了一个小房间,里面做了两个人,看样子都是做技术的(因为都有点秃),一开始都很顺利,然后问道了一个问题“你简历上说你熟悉Java源码,那我问你个问题,String类可以被继承么”,当然是不可以继承的,文章上都写了,String是用final修饰的,是无法被继承的,然后我又说了一些面试题上的内容,面试官接着又问了一个问题: “请你简单说一下substring的实现过程” 是的,我没有看过这一题,平时使用的时候,也不会去看这个方法的源码,我支支吾吾的回答不上来,我能感觉到我的脸红到发烫。他好像看出了我的窘迫,于是接着说“你真的看过源码么?substring是一个很简单的方法,如果你真的看过,不可能不知道”,到这个地步,我也只好坦白,我没有看过源码,是的我其实连简单的substring怎么实现的都不知道,我甚至都找不到String类的源码。 面试官说了标题上的那句话,然后我面试失败了。 我要感谢这次失败的经历,让我打开了新世界,我开始尝试去看源码,从jdk源码到Spring,再到SpringBoot源码,看得越多我越敬佩那些写出这优秀框架的大佬,他们的思路、代码逻辑、设计模式,是那么的优秀与恰当。不仅如此,我也开始逐渐尝试自己去写一些框架,第一个练手框架是“手写简版Spring框架--YzSpring”,花了我一周时间,每天夜里下班之后都要在家敲上一两个小时,写完YzSpring之后,我感觉我才真正了解Spring,之前看网上的资料时总觉得是隔靴搔痒,只有真正去自己手写一遍才能明白Spring的工作原理。 再后来,我手上的“IPayment”项目的合作伙伴一直抱怨我们接口反馈速度慢,我着手优化代码,将一些数据缓存到Redis中,速度果然是快了起来,但是每添加一个缓存数据都要两三行代码来进行配套,缓存数据少倒无所谓,但是随着越来越多的数据需要写入缓存,代码变得无比臃肿。有天我看到@Autowired的注入功能,我忽然想到,为什么我不能自己写一个实用框架来将这些需要缓存的数据用注解标注,然后用框架处理呢?说干就干,连续加班一周,我完成了“基于Redis的快速数据缓存组件”,引入项目之后,需要缓存的数据只需要用@BFastCache修饰即可,可选的操作还有:对数据进行操作、选择数据源、更新数据源、设置/修改Key等,大大提高了工作效率。第一次自写轮子,而且效果这么好,得到了老大哥的肯定,真的很开心。 那么现在我要问你三个问题:- 你看源码么?
- 你会看源码么?
- 你从源码中有收获么?
二、看源码可以获得什么
1.快速查错、减少出错 在编码时,我们一般都发现不了RuntimeException,就比如String的substring方法,可能有时候我们传入的endIndex大于字符串的长度,这样运行时就会有个错误:String index out of range: 100public String substring(int beginIndex, int endIndex) {if (beginIndex 0) {//起始坐标小于0throw new StringIndexOutOfBoundsException(beginIndex);
}if (endIndex > value.length) {//结束坐标大于字符串长度throw new StringIndexOutOfBoundsException(endIndex);
}int subLen = endIndex - beginIndex;if (subLen 0) {//起始坐标大于结束坐标throw new StringIndexOutOfBoundsException(subLen);
}return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}if ((beginIndex == 0) && (endIndex == value.length)) return this;return new String(value, beginIndex, subLen);3.学习设计模式(针对新手)
好吧!我摊牌了,作为一个半路出家的程序员,我没有接受过系统化的教学,所有的都是自学,在之前我完全不了解设计模式,只知道有23种设计模式,最多知道单例模式。 不了解设计模式最主要的原因是当时没有实战经验,自己写的项目都是比赛项目,完全不用不上设计模式,基本上是能跑就行。我第一次接触设计模式是在log4j的工厂模式,当时是完全不懂工厂模式该怎么用,就是看着log4j的源码一步步学会了,然后自己做项目的时候就会有意无意的开始运用设计模式,下面是我项目中使用单例模式获取配置类的代码:import java.util.ResourceBundle;public class Configration {private static Object lock = new Object();private static Configration config = null;private static ResourceBundle rb = null;private Configration(String filename) {
rb = ResourceBundle.getBundle(filename);
}public static Configration getInstance(String filename) {
synchronized(lock) {if(null == config) {
config = new Configration(filename);
}
}return (config);
}public String getValue(String key) {
String ret = "";if(rb.containsKey(key))
{
ret = rb.getString(key);
}return ret;
}
}三、阅读源码的正确姿势
我们这里以一个热度非常高的类HashMap来举例,同时我非常建议你使用IDEA来阅读编码,其自带反编译器,可以让我们快速方便的看到源码,还有众多快捷键操作,让我们的操作爽到飞起。 1.定位源码 其实定位的时候也有多种情况: Ctrl+左键
 HashMap的put方法是重写了Map的方法,如果我们用Ctrl+左键,会直接跳到Map接口的put方法上,这不是我们想要的结果,此时我们应该把鼠标光标放到put上,然后按下Ctrl+Alt+B,然后就出现了很多重写过put方法的类。
HashMap的put方法是重写了Map的方法,如果我们用Ctrl+左键,会直接跳到Map接口的put方法上,这不是我们想要的结果,此时我们应该把鼠标光标放到put上,然后按下Ctrl+Alt+B,然后就出现了很多重写过put方法的类。
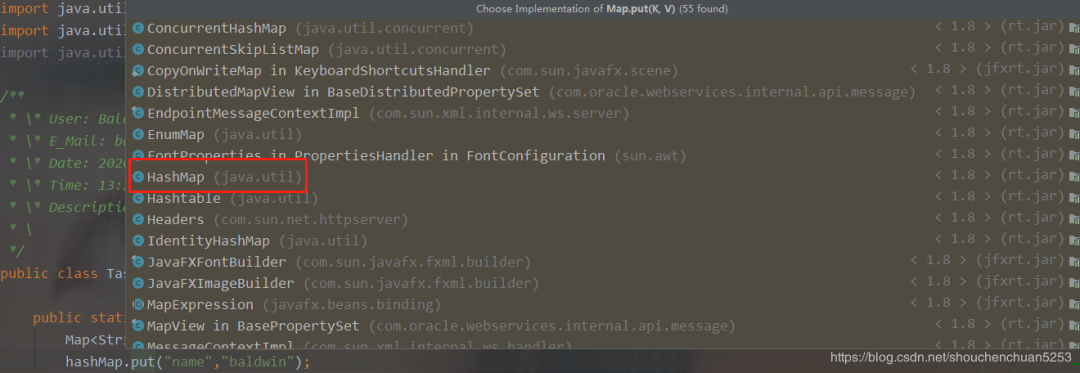 找到我们需要查看的类,左键点击就可以定位到put方法了。
2.查看继承关系
一个类的继承关系很重要,特别是继承的抽象类,因为抽象类中的方法在子类中是可以使用的。
上一步中我们已经定位到了HashMap源码上,现在拉到最上面,我们可以看到类定义的时候是有一下继承关系:
找到我们需要查看的类,左键点击就可以定位到put方法了。
2.查看继承关系
一个类的继承关系很重要,特别是继承的抽象类,因为抽象类中的方法在子类中是可以使用的。
上一步中我们已经定位到了HashMap源码上,现在拉到最上面,我们可以看到类定义的时候是有一下继承关系:
public class HashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable 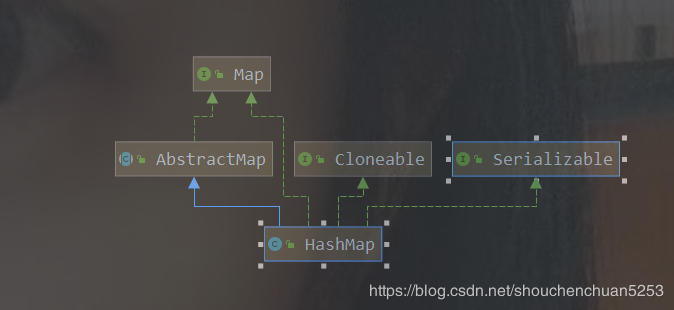 然后大致查看下AbstractMap抽象类,因为有可能等下会用到。
3.查看类常量
我们进到HashMap构造函数时,发现了以下代码:
然后大致查看下AbstractMap抽象类,因为有可能等下会用到。
3.查看类常量
我们进到HashMap构造函数时,发现了以下代码:
public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);
}//序列号private static final long serialVersionUID = 362498820763181265L;/**
* 初始容量,必须是2的幂数
* 1 < */static final int DEFAULT_INITIAL_CAPACITY = 1 <4; // 初始默认值二进制1左移四位 = 16/**
* 最大容量
* 必须是2的幂数 <= 1<<30.
*/static final int MAXIMUM_CAPACITY = 1 <30;/**
* 加载因子,构造函数中没有指定时会被使用
*/static final float DEFAULT_LOAD_FACTOR = 0.75f;/**
* 从链表转到树的时机
*/static final int TREEIFY_THRESHOLD = 8;/**
* 从树转到链表的时机
*/static final int UNTREEIFY_THRESHOLD = 6;/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/static final int MIN_TREEIFY_CAPACITY = 64;
这样,我们就对HashMap中常量的作用和意义有所理解了
4.查看构造函数 我们一般看一个类,首先得看这个类是如何构建的,也就是构造方法的实现: /**
* 构造一个空的,带有初始值和初始加载因子的HashMap
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);
} /**
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity 0)throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);
} static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);else {
Node e; K k;if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);break;
}if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))break;
p = e;
}
}if (e != null) { // existing mapping for key
V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);return oldValue;
}
}
++modCount;if (++size > threshold)
resize();
afterNodeInsertion(evict);return null;
} /**
* 继承于 Map.put.
*
* @param hash key的hash值
* @param key key
* @param value 要输入的值
* @param onlyIfAbsent 如果是 true, 不改变存在的值
* @param evict if false, the table is in creation mode.
* @return 返回当前值, 当前值不存在返回null
*/static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;
V value;
Node next;
Node(int hash, K key, V value, Node next) {this.hash = hash;this.key = key;this.value = value;this.next = next;
}
}●编号1276,输入编号直达本文
●输入m获取文章目录
程序员求职面试
分享程序员找工作经验
程序员笔试、面试题















 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









