







微信公众号:qiongjian0427
运行环境:anaconda—jupyter notebook
Python版本:Python3
流程
(1) 收集数据:公众号。
(2) 准备数据:解析tab键分隔的数据行。
(3) 分析数据:快速检查数据,确保正确解析数据,使用createPlot()函数绘制树形图。
(4) 训练算法:使用createTree()函数。
(5) 测试算法:编写测试函数验证决策树可以正确分类给定的数据。
(6) 使用算法:储存树的数据结构,以便下次使用
代码
隐形眼镜数据集是非常著名的数据集,它包含了很多患者眼部状况的观察条件以及医生推荐的隐形眼镜类型。
隐形眼镜类型包括硬材质(hard)、软材质(soft)以及不适合佩戴隐形眼镜(no lenses)。
特征有四个:age(年龄)、prescript(症状)、astigmatic(是否散光)、tearRate(眼泪数量)
fr=open('lenses.txt')
lenses=[inst.strip().split('t') for inst in fr.readlines()]
lensesLabels=['age','prescript','astigmatic','tearRate']
lensesTree=createTree(lenses,lensesLabels)运行结果:
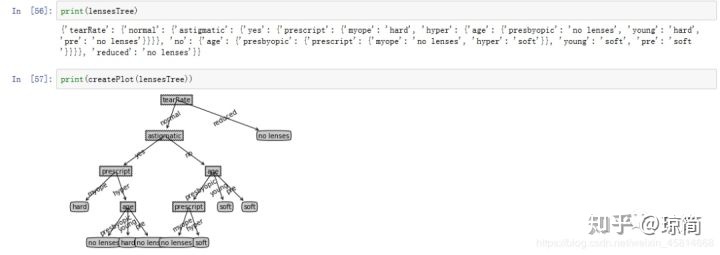
决策树可能会产生过多的数据集划分,从而产生过度匹配数据集的问题。
可以通过裁剪决策树,合并相邻的无法产生大量信息增益的叶节点,消除过度匹配问题。
决策树小结
决策树分类器就像带有终止块的流程图,终止块表示分类结果。
开始处理数据集时,我们首先要测量集合中数据的不一致性, 也就是熵,然后寻找最优方案划分数据集,直到数据集中的所有数据属于同一分类。
ID3算法无法直接处理数值型数据,可以用于划分标称型数据集。
构建决策树时,我们]通常采用递归的方法将数据集转化为决策树。
Matplotlib的注解功能可以将存储的树结构转化为容易理解的图形。
Python语言的pickle模块可以储存决策树的结构。
隐形眼镜的例子表明决策树可能会产生过多的数据集划分,从而产生边度匹配数据集的问题。我们可以通过裁剪决策树,合并相邻的无法产生大量信息增益的叶节点消除过度匹配问题。
其他的决策树的算法最流行的是C4.5和CART。后面会学到CART。
end.















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









