





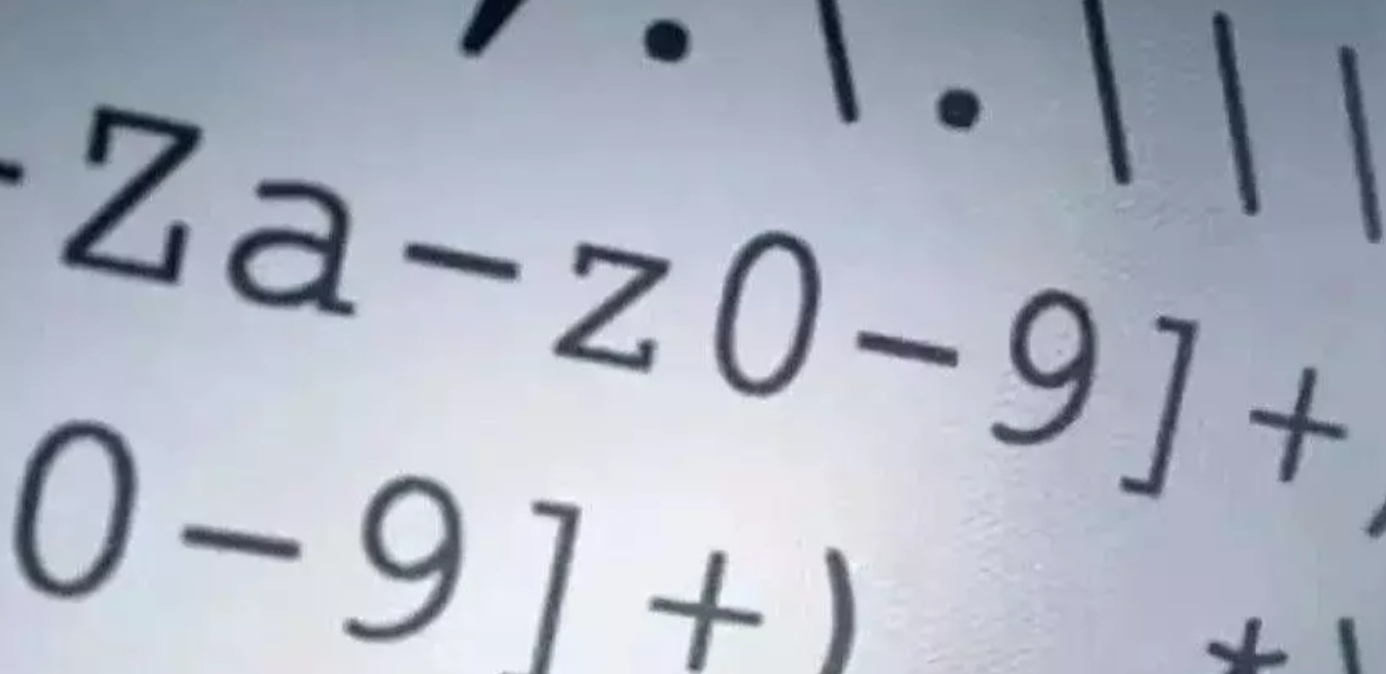
爬虫解析数据的方法有很多种,我们需要根据不同的格式选择相应的解析方法。其中,正则表达式是相对通用的一种方法。本篇将涉及内容有:
- 介绍一些简单的正则表达式的知识;
- 通过两款工具介绍正则分析的方法;
什么是正则
正则的英文是regularExpression,即正则表达式。正则最早起源于对人类神经网络的研究,后来被人们应用到了计算搜索算法中。那么具体啥是正则表达式呢?
简言之,可理解为是描述一段文本组成规则的语言,它是由一系列普通与特殊字符组成的用于描述文本规则的表达式。比如,当我们想找出满足以#开头或包含有4位数字的文本,这时候就会用到正则表达式。
正则的用处有很多,下面来列举一些常见的场景:
- 在网站开发领域,如输入框表单验证,可用正则确认如昵称、邮箱、手机号码填写是否正确;
- 在爬虫数据领域,如HTML文本解析,可以利用正则获取某些元素的一部分数据;
- 编程开发工具,如代码搜索功能,通过正则,IDE为我们提供了更加强大的搜索能力;
- 运维操作领域,如Linux很多命令都支持正则,如Linux文本处理三剑客grep、sed和awk;
正则表达式适合多种场景、系统以及语言,已经是现代计算机科学中必不可少的部分。
测试工具
为了防止大家因平台和语言的差异导致的测试不便,下面会使用网页测试工具来演示正则。介绍两款工具
- 正则解析工具,主要是以图形化的语言解释正则表达式;
- 正则验证工具,功能强大且可以用来生成各种语言代码;
解析工具
该工具主要可以用来解释正则。它以友好的图形语言来展示正则的解析方式,工具地址https://regexper.com,下图就是某个正则的图像化表示。
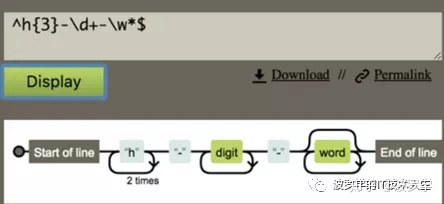
上面输入的正则是 ^h{3}-d+-w*$。我们来看看图形化的解析结果,依次解释如下:
- 以 Start of line 开始,表示行的起始位置;
- "h"必须出现3个,即本身一次加上2次循环;
- 接着出现1个 "-";
- digit,即数字,至少需要出现1个;
- 接着需要1个 "-";
- 任意次word(字符)
- 以 End of line 表示结束;
这种图形化的方式来展示正则的规则还是比较形象合理的,用另一种易于理解的图形语言解释不好理解的正则,这个思路还是很值得推荐的。
但是这里展示解释了正则,具体使用还需要经过文本测试才能放心。因此,我们还需要一款支持文本测试的工具。
验证工具
工具地址:
PHP, PCRE, Python, Golang and JavaScriptregex101.com支持文本测试,可以先点进去简单的玩一玩。
那么我们就使用这个工具进一步验证一下我们刚才写的正则吧。测试文本为 hhh-221-jjj。验证结果如下:
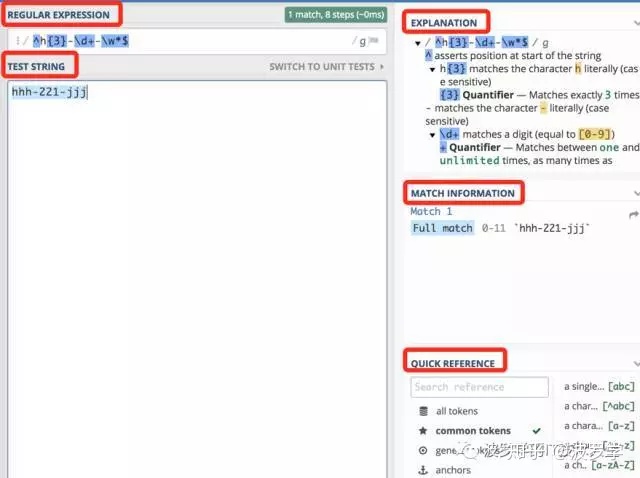
此处显示“hhh-221-jjj”选中着色,即为全部匹配,基本可以确定正则无误。不知道有没有觉得这个工具挺方便的,其实它还有很多功能,简单介绍一下它由哪些部分组成:
- REGULAR EXPRESSION:即正则编辑框,示例中尾部g表示全局模式,支持多种模式,如忽略大小写、多行模式,unicode模式等;
- TEST STRING:测试文本输入框,会对匹配文本着色,此处hhh-221-jjj被选中着色;
- EXPLANATION):说明正则含义,可理解为图形解析的文字版
- MATCH INFORMATION: 示例匹配文本的位置 即0-11,相应的文本就是hhh-221-jjj;
- QUICK REFERENCE:可快速查看正则的使用方法;
还有一些其他功能,比如多种编程语言的代码自动生成,还提供正则调试器,也可以将正则保存等;
这两个网页工具,大家或许更喜欢第二个。因为它和我们平时的使用习惯跟接近。不过,第一个工具可以很帮助我们将正则具象化;
示例体验
这里介绍两个例子,初步了解下正则表达式能处理什么场景,究竟有多强大。
搜索指定单词
假设爬去的html中包含如下文本:
My name is poloxue. I haven't a polo car and polo t-shirt我们需要检测其中是否含有polo,分析结果如下:
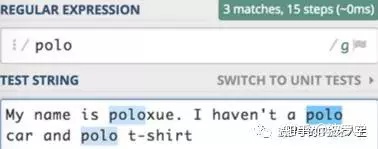
这里除了将polo搜索出来,poloxue也搜索了出来。这和我们的目标不一致。为达到目标,下面引入特殊符号b,我们可以将它称为元字符。b表示单词的分界符。继续看结果:
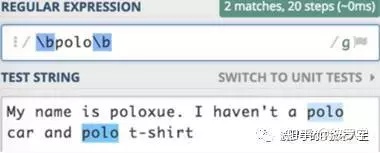
只选中了单词polo,我们的目标达成了。来看看图形解析结果:
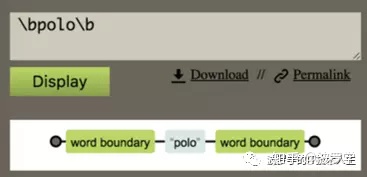
- word boundary 表示单词边界
- 接着是文本polo
我们在这里第一次使用了元字符。
搜索手机号码
从一段复杂的文本中,搜索所有的手机号码。在开始解题前,先了解下手机号码的规则:
- 11位数字
- 13 + 9位任意数字
- 15[012356789] + 8位任意数字
- 18[0256789]+8位任意数字
- 170[059]+7位任意数字
主要有四条规则。先写出满足所有条件的正则,如下:
b(13d{9}|15[0-35-9]d{8}|18[025-9]d{8}|170[059]d{7})b此处之所以使用b是为了防止类似153122108880123456也匹配成功。先来看看图形化结果:
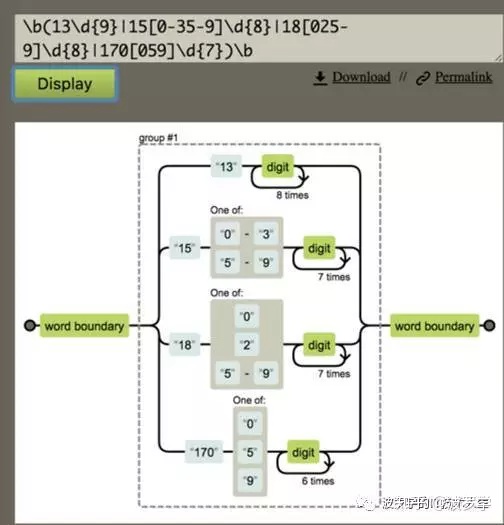
如描述的规则一样,这里主要四条路径。下面使用验证工具验证一下,假设有如下一段文本
A: What is your ID number?B: My ID number is 321323200210230023A: What is your mobile number?B: My mobile number is 15312210888工具测试结果如下:
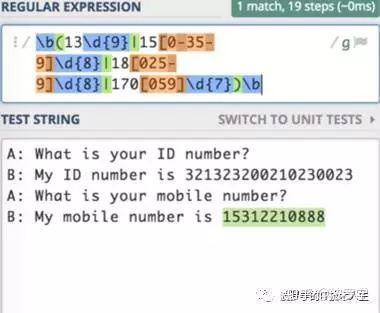
示例中用到了正则的很多特性,比如:
- 重复,由元字符{}指定某类字符重复重现的次数,如d{9}表示连续9个数字;
- 范围,由元字符[]指定字符范围,如[0-35-9]表示为0-3和5-9间九数任一字符;
- 分支,由元字符”|“实现,可理解为正则的“或”,文本匹配”|“分隔的任一正则即可;
- 分组,元字符()里的正则表示子正则,使用()是防止b非作用整体而是分支中的某部分;
元字符特性远不止于此,如果平时我们在使用正则时遇到一些难以理解的问题,就可以使用下前面介绍的两款工具来分析分析。















 1530
1530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









