







原文链接:Support Vector Machine Chinese Version
最新的版本在原文链接里可以找到。原博客会不断更新。这篇笔记主要梳理了吴恩达教授在斯坦福的CS229课程的内容,并结合了哥伦比亚大学几个教授相关笔记内容一并总结。
请注意: 本文是翻译的一份学习资料,英文原版请点击Wei的学习笔记:Support Vector Machine (SVM)
中文版将不断和原作者的英文笔记同步内容,定期更新和维护。
许多人认为支持向量机(SVM)是目前最好的分类器之一,也很容易在许多编程语言(如Python和Matlab)中实现。我将在这篇博客中讨论支持向量机的原理。另外,SVM中核函数的运用也允许了我们在高维度数据空间中应用SVM,因此核函数也会作为其中一个要点在文章中进行讨论。
1 直观理解与符号应用
通常,由于二元分类是多元分类中的最简单的情况,人们总是习惯从二元分类下手研究问题。关于二元分类,我们已经在先前的笔记中学过了一些概率模型,例如逻辑回归。至于SVM,它可以对随机空间维度中的点进行分类,并且可以通过使用确定性算法来解决问题。
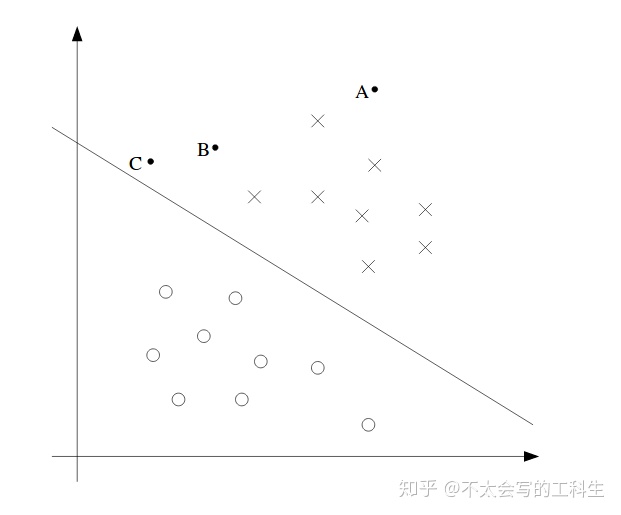
上述2D模型是一个简单的例子。从图中我们可以看到,在空间中有A,B和C点。A是最安全的点,因为它远离边界线(高维的超平面),而C是最危险的点,因为它接近超平面。边界线和点之间的距离称为间隔(margin)。
我们以 x 表示特征向量,以 y 表示分类结果,以 h 表示分类器。因此,SVM分类器可以表示为:
请注意,SVM和逻辑算法并不一样。在SVM中,w,b代替了原本的
2 函数间隔与几何间隔
函数间隔关于训练数据的表达:
当分类y为正数1时,我们希望
其中,m为训练样本的数量。
几何间隔:在几何间隔中,我们认为w和b的缩放倍数大小不应影响间隔的比例,因此需要对w和b进行关于w范数的归一化。一个几何间隔的表示可见下图:
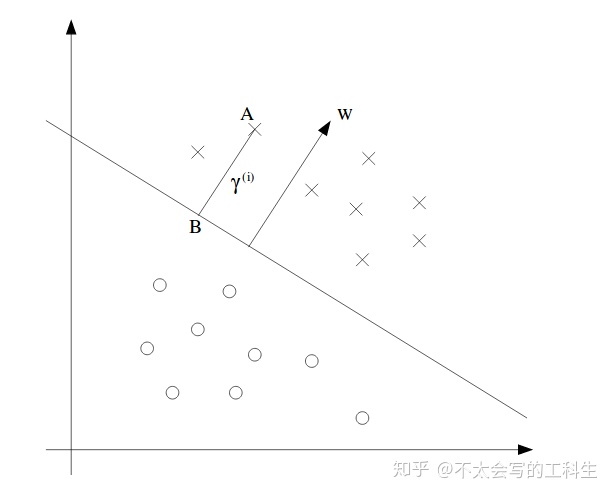
图中w也可以被称为支持向量。w与边界线相垂直,为了证明这一点,让我们在边界线上任取两点
于是,我们可以有:
类似地,为了找到A点的间隔,我们声明
解:
当然,这仅仅是结果(间隔)为正数的情况。对于负值样本,我们会得到一个负数的结果。所以为了统一这一点,我们将上面推演出的间隔乘以分类y(1或-1)。因此,我们将对于一个训练样本的几何间隔定义为:
如果
类似地,对于所有训练样本的几何间隔是:
3 最优间隔分类器
最重要的是,简单来说,我们的目标是最大化几何间隔,越大越好。
目前,我们假设数据是线性可分的。这个优化问题可以定义为:
第一个约束是确保每个训练样本都具有有效的几何间隔。第二点是为了确保几何间隔等于函数间隔。我们必须有第二个约束,因为
为此,我们可以将其转换为:
我们使用了函数间隔来表示几何间隔。这里我们用了最初预期的函数间隔,而不是几何间隔。 通过这样做,我们消除了
回想一下,通过缩放w和b,我们没有改变任何东西。我们使用这个事实来强制函数间隔
同样,我们有
4 拉格朗日对偶性
关于如何解决约束优化问题,让我们稍稍插入另一个话题。一般来说,我们通常使用拉格朗日对偶来解决这类问题。
我们考虑这样一个问题:
现在,我们可以将拉格朗日定义为:
其中
上述只有等式约束,同时我们可以推演到等式和不等式约束。所以我们定义Primal Problem为:
我们将广义拉格朗日定义为:
其中所有的
让我们定义primal problem的数量为:
在这个数量中,我们需要
如果所有条件都满足的话,我们将有:
为了与我们的primal problem相匹配,我们将最小问题定义为:
如果满足了所有约束,那么这将与primal problem相同。我们将primal problem的值定义为:
从不同的角度我们可以将以下定义为dual problem(对偶问题)的一部分:
为了再次与primal problem相匹配,我们将对偶最优化问题(dual optimization problem)定义为:
相同的,对偶问题的值为:
Primal 和 dual problem 的相关性为:
上述公式永远为真。要证明这一点,我们首先定义一个函数
也就是说,对于函数g的每个x,我们选一个能使f(x,y)最小化的y值。然后,我们可以说:
我们可以在两边各添加一个max运算符,以消除变量x:
这等同于:
以上便是证明的过程。
回到主题:关键是在某些条件下,它们是相等的。如果他们是相等的,我们可以专注于dual problem而不是primal problem。那么唯一的问题将是 - 它们何时相等。
我们假设f和g都是凸函数,h是仿射函数(当f有Hessian时,如果Hessian是正半正定则它是凸的。所有仿射都是凸的,仿射意味着线性。),对于一些w,函数g全部小于0。
从这些假设出发,primal的解
第三个等式被称为KKT dual complementarity condition。意思是如果
5 拉格朗日对偶和最优间隔分类器
让我们回到SVM的primal problem:
我们可以重新设定约束为:
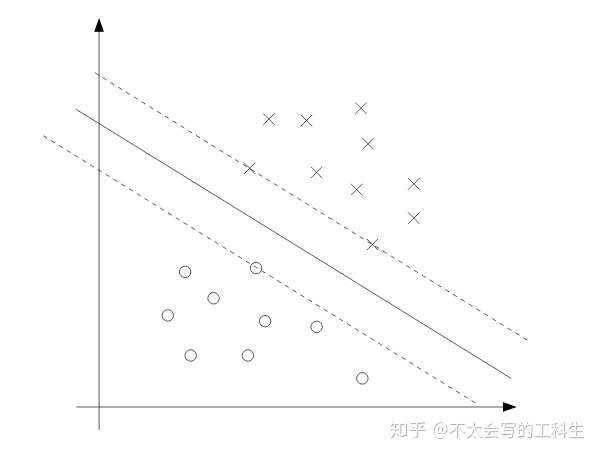
其中i包含所有训练样本。从KKT条件中我们可以看到,当函数间隔为1且
我们可以在下面的图片中看到这一点:虚线上的三个点是具有最小几何间隔的点,所以这些点的
仅有不等式约束的拉格朗日:
要找到这个问题的对偶形式(dual form)的话,我们需要在给定
对于 w:
这说明:
对于 b:
一个有用的公式:
我们将等式(3)带回到等式(1),得到:
我们需要注意
这是满足KKT条件的,可以自己尝试着去证明一下。这意味着我们现在要解决的是dual problem而不是primal problem。如果我们可以在这个dual problem中找到
想验证它的话很容易。基本上我们要做的就是,分别从正负两个类别中取出与超平面具有相同距离的点,也就是支持向量。由于它们的间隔是相同的,我们可以很好的用这个属性来解
等式(3)所表达的是:最优化的w是基于最优化的
如果大于零,我们预测1,小于零则预测-1。我们知道,由于约束,除了支持向量以外的所有
6 核函数
在房屋居住区域的例子中,我们可以使用特征
因此,我们可以在新的特征空间
定义上讲,给定一个映射函数我们可以将核函数声明为:
这里我们可以使用核函数,而不是映射函数本身,其原因可以在cs229课程的原笔记中找到,由于内容比较细节这里就不再过多赘述。简而言之,核函数在计算上复杂度较低,并且可以用于高维度或无限维度映射中。所以我们可以在高维空间中进行训练而无需计算映射函数
原笔记中有一个例子证明了核函数的效率之高。你需要知道的是,计算映射所需要的时间复杂度是呈指数的,而计算核函数需要的时间复杂度是线性的。
换句话说,核函数是用来计算两个样本(x 和 z)之间的远近的,它呈现了相似性的概念。在流行的核函数中,有一个被称为高斯核函数,其定义如下:
我们可以使用它来训练SVM,它对应的是无限维度特征映射函数
接下来,我很想讨论下关于核函数有效性的事情。
我们定义拥有m个点的核矩阵为
(1)对称矩阵:
(2)半正定矩阵:
Mercer定理:设
核函数方法不仅在SVM中有运用,它在任何有内积的情况下都是用途颇广的。因此,我们用核函数替换内积,以便在更高的维度空间中使用。
7 正规化与无法分割问题
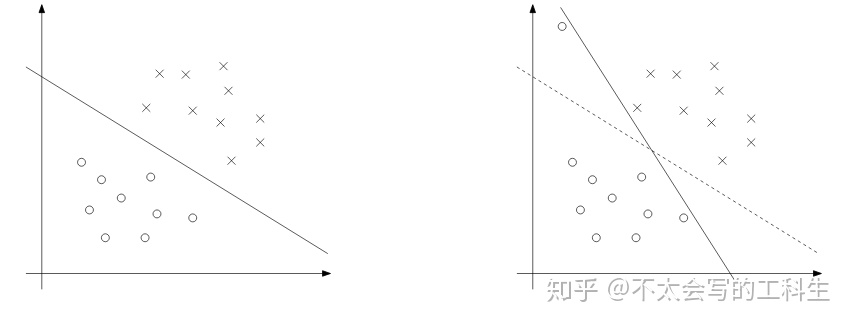
尽管将x映射到更高维度的空间增加了可分离的机会,但情况可能并非总是如此。一个异常值的出现也是非常棘手的,我们不会想把这种异常值放入训练集的。下图演示了这种情况:
为了使算法也适用于非线性情况,我们将用到正则化:
正规化将惩罚对于函数间隔小于1的样本,C将确保大多数样本的函数间隔至少为1。这表明了:
(1) 我们希望w小,这样间隔就会大。
(2) 我们希望大多数样本的函数间隔大于1。
拉格朗日为:
其中
注意,
还需要注意的是,由于两个最近的点的间隔都已改变,这里的最优b不再与之前相同。在下一节中,我们将找到一个合适的算法来解决问题。
8 序列最小优化算法(SMO)
John Platt的SMO(顺序最小优化)算法的出现是用来解决SVM中的dual problem的。
8.1 坐标上升法
一般来讲,最优化问题
可以通过梯度上升和牛顿法来解决。另外,我们也可以使用坐标上升法:
for loop until convergence:
for i in range(1,m):
alpha(i) = argmin of alpha(i) W(all alpha)总的来说,我们将除
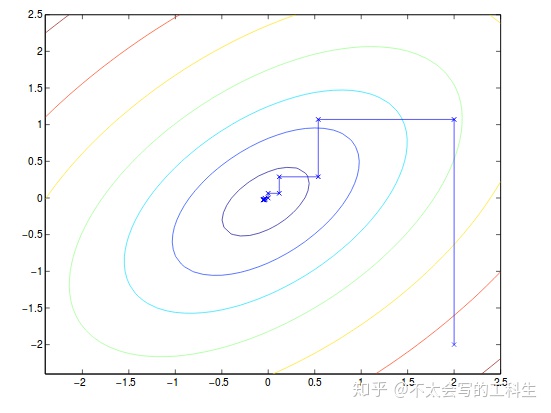
这里请注意,收敛的路径始终与x或y轴平行,因为它每一次只更新一个变量。
8.2 序列最小优化算法(SMO)
我们不能在SVM的dual problem中做与上面相似的事情,因为只改变一个变量可能会违反约束:
这表示一旦我们确定剩余部分的
我们使右边保持不变:
在图中可以表示为:
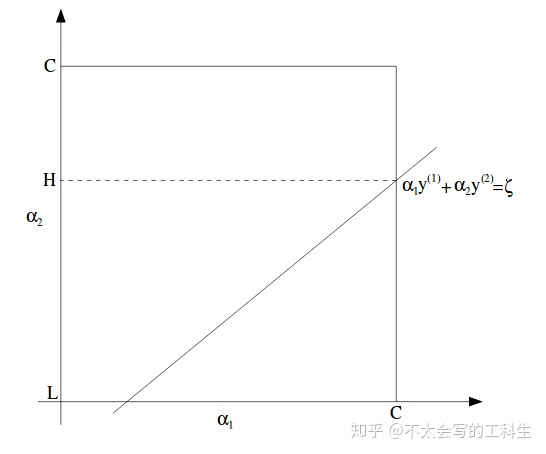
在此图中,L和H是
这里注意,尽管
我们可以重写上面的等式:
那么W将会是:
我们将所有其他
最后,我们将















 1440
1440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









