







在机器学习中,我们经常要把数据分成训练数据和测试数据,但是分的比例是多少呢?
当然可以80%的用作训练,20%用作测试,这样就是静态分配,简单,时间快
但是为了更高的准确率,我们还可以采用别的办法:
K折交叉验证
把数据平分成5份,,然后先以第一份为测试数据,后面的是训练数据,然后再依次类推
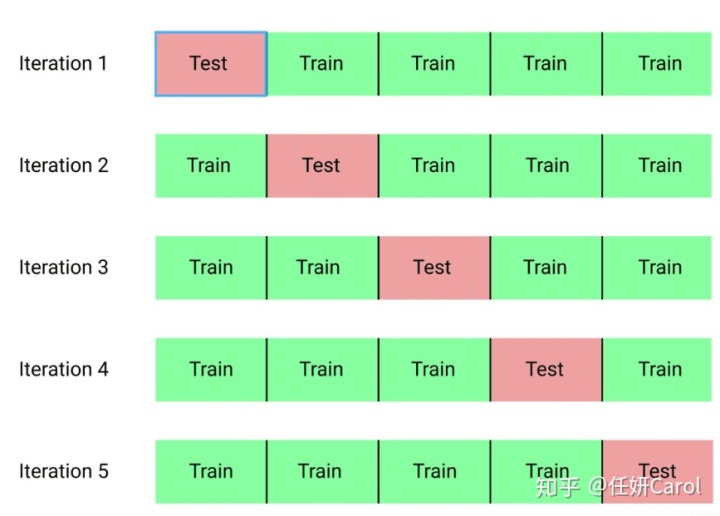
这样经过反复划分,可以求平均值
需要注意的是:K折交叉验证会平均的划分这些数据,但是如果你的数据是按照某种模式排列的(比方说前半部分都是来自sara的数据,后半部分都是来自lisa的数据,那么这样子的划分就会使准确率非常低。因为你用sara的数据来训练,却用lisa的数据来测试
GridSearchCV
我们在分析问题的时候,经常要调整参数,找到使用哪些参数才可以得到更好的效果。这样子其实是很费力的
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2369
2369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









