







MongoDB基础入门到高级进阶视频教程
【MongoDB】
六、Document 操作
在MongoDB中文档是指多个键及其关联的值有序地放置在一起就是文档,其实指的就是数据,也是我们平时操作最多的部分。
MongoDB中的文档的数据结构和 JSON 基本一样。所有存储在集合中的数据都是 BSON 格式。
BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
1. 新增文档
1.1 新增单一文档
1.1.1 insert函数
语法格式为:db.COLLECTION_NAME.insert(document)。
向test集合中插入单个文档。
db.test.insert({title:'北京尚学堂',description:'程序员的摇篮',url:'www.bjsxt.com',tags:['java','大数据','python'],'time':new ISODate('2020-01-01T10:10:10.000Z')})
1.1.2 save函数
向test集合中插入单个文档。
db.test.save({title:'百战程序员',description:'身经百战,高薪相伴',url:'www.itbaizhan.cn',tags:['javaWeb实战','数据库实战','微服务实战']})
1.1.3 insertOne函数
在MongoDB3.2以后的版本中,提供了insertOne()函数用于插入文档。
向test集合中插入单个文档。
db.test.insertOne({title:'尚学堂大数据',description:'培养大数据人才的摇篮',url:'www.bjsxt.com',tags:['hadoop','spark','Hbase']})
1.2 批量新增文档
1.2.1 insert函数
向test集合中批量插入多个文档
db.test.insert([{title:'java',tags:['JavaSE','JavaEE','JavaME']},{title:'ORM',tags:['Mybatis','Hibernate']},{title:'Spring',tags:['SpringMVC','SpringBoot','SpringCloud']}])
1.2.2 save函数
向test集合中批量插入多个文档
db.test.save([{title:'java',tags:['JavaSE','JavaEE','JavaME']},{title:'ORM',tags:['Mybatis','Hibernate']},{title:'Spring',tags:['SpringMVC','SpringBoot','SpringCloud']}])
1.2.3 insertMany函数
在MongoDB3.2以后的版本中,提供了insertMany函数用于插入文档。
语法格式:db.COLLECTION_NAME.insertMany([{},{},{},.....])
向test集合中批量插入多个文档
db.test.insertMany([{title:'java',tags:['JavaSE','JavaEE','JavaME']},{title:'ORM',tags:['Mybatis','Hibernate']},{title:'Spring',tags:['SpringMVC','SpringBoot','SpringCloud']}])
1.3 通过变量新增文档
Mongo Shell工具允许我们定义变量。所有的变量类型为var类型。也可忽略变量类型。变量中赋值符号后侧需要使用小括号来表示变量中的值。我们可以将变量作为任意插入文档的函数的参数。
语法格式:变量名=(<变量值>)
1.3.1 变量新增单一文档
定义变量
document=({title:'SpringCloud',tags:['Spring Cloud Netflix','Spring Cloud Security','Spring Cloud Consul']})
新增文档
db.test.insert(document);
db.test.save(document);
db.test.insertOne(document);
1.3.2 变量批量新增文档
定义变量
document=([{title:'SpringCloud',tags:['Spring Cloud Netflix','Spring Cloud Security','Spring Cloud Consul']},{title:'SpringBoot',tags:['Spring Boot']}])
新增文档
db.test.insert(document);
db.test.save(document);
db.test.insertMany(document);
2 查询文档
MongoDB是通过findOne()和find()函数来实现文档查询的。
2.1 基础应用
2.1.1 findOne函数
findOne函数用于查询集合中的一个文档。语法如下:
db.集合名称.findOne({
<query>},
{<projection>
});
参数解释:
- query:可选,代表查询条件。
- projection:可选,代表查询结果的投影字段名。即查询结果需要返回哪些字段或不需要返回哪些字段。
查询stu集合中第一个文档:
db.stu.findOne();
或
db.stu.findOne({});
查询stu集合中name字段为lisi的第一个文档:
db.stu.findOne({'name':'lisi'});
查询stu集合中第一个文档,且只显示name字段:
db.stu.findOne({},{'name':1});
查询stu集合中第一个文档,且不显示name和age字段:
db.stu.findOne({},{'name':0,'age':0});
注意:在projection中不能使用{'name':0, 'age':1}这种语法格式,这是错误的语法。projection只能定义要返回的字段或不返回的字段。_id字段是MongoDB维护的字段,是唯一可以在projection中独立使用的。如:{_id:0, 'name':1, 'age':1}
2.1.2 find函数
find函数用于查询集合中的若干文档。语法如下:
db.stu.find({<query>},{<projection>});
参数解释:
query:可选,代表查询条件。
projection:可选,代表查询结果的投影字段名。即查询结果需要返回哪些字段或不需要返回哪些字段。
查询stu集合中的所有文档:
db.stu.find()
或
db.stu.find({})
查询stu集合中所有name字段为lisi的文档:
db.stu.find({'name':'lisi'});
2.1.3 投影约束
在MongoDB中,_id字段是默认返回显示的投影字段。
查询stu集合中所有文档,且只显示name字段:
db.stu.find({},{'name':1});
查询stu集合中所有文档,且显示除name字段以外的其他字段:
db.stu.find({},{'name':0});
非_id字段,在投影约束中不能互斥,否则抛出异常。如:{"name":1, "age":0}抛出异常。
包含_id字段,在投影约束中可以和其他字段互斥约束,但是,_id字段必须为非投影显示约束(0),
如:{"name":1, "_id":0} 正确的。
包含_id字段,在投影约束中,如果和其他字段投影约束互斥,且_id字段投影约束为显示(1),会抛出异常,
如:{"_id":1, "name":0} 抛出异常。
常用方式: {"_id":0, "xxx":1} {"xxx":0}
总结:投影时,_id为1的时候,其他字段必须是1;_id是0的时候,其他字段可以是0;如果没有_id字段约束,多个其他字段必须同为0或同为1。
2.2 pretty函数
pretty函数用于格式化find函数查询结果。让查询结果更易查看。findOne函数自动附带格式化查询结果的能力。
语法:
db.stu.find().pretty();
2.3 单条件逻辑运算符
如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
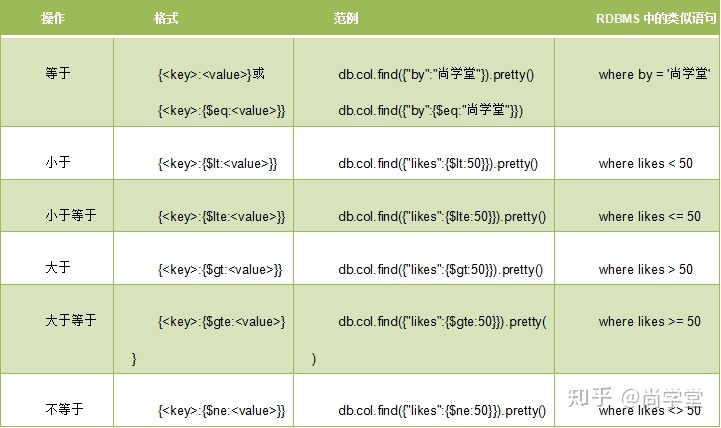
在MongoDB中字符串也可以比较大小。按照Unicode编码顺序比较大小。
日期可以比较大小: 过往 < 现在 < 未来。
2.4 多条件逻辑运算符
2.4.1 And条件
MongoDB 的 find() 和 findOne() 函数可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
查询stu集合中name字段为lisi,且age字段大于20的文档:
db.stu.find({'name':'lisi', 'age':{'$gt':20}});
2.4.2 Or条件
MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
db.集合名称.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
)
查询stu集合中name字段为lisi或age字段大于22的文档:
db.stu.find({'$or':[{'name':'lisi'},{'age':{'$gt':22}}]});
2.4.3 And和Or的配合使用
查询集合stu中name字段为zhangsan,或name字段为lisi且age字段为22的文档。
db.stu.find({$or:[{'name': 'zhangsan'},{'name':'lisi', 'age':22}]});
2.5 $type查询
在MongoDB中根据字段的数量类型来查询数据使用$type操作符来实现,具体使用法语:
db.集合名.find({属性名:{$type:类型值}}) //这里的类型值能使用Number也能使用alias
$type的有效值如下:
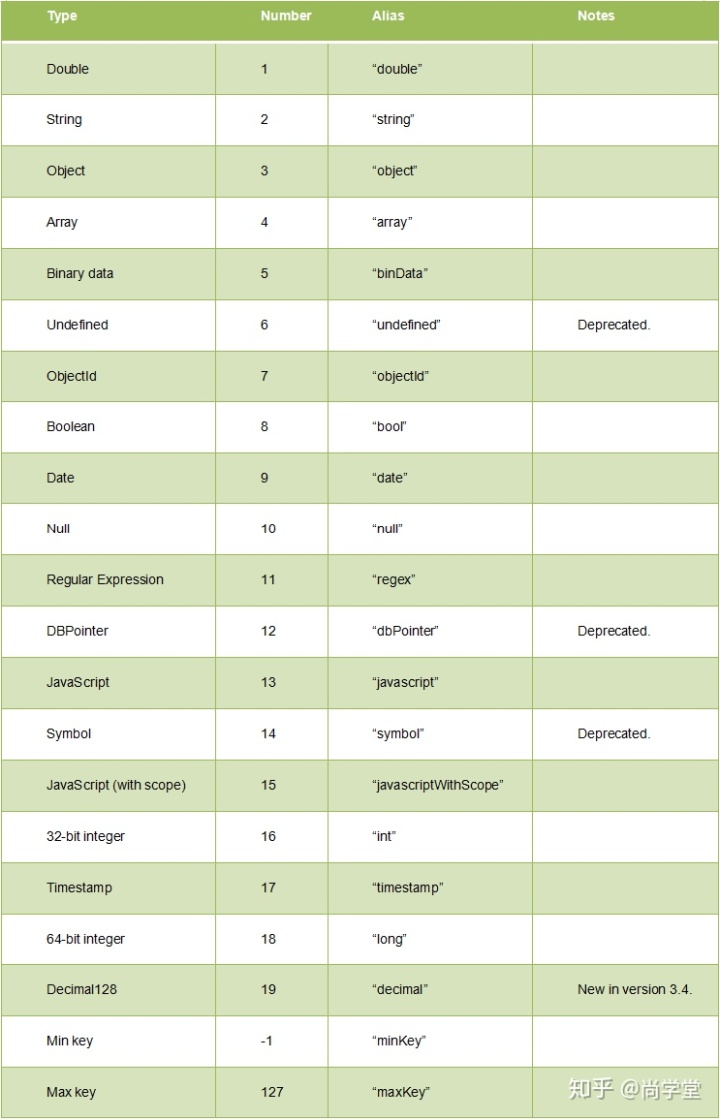
查询stu集合中name字段类型为字符串的文档:
db.stu.find({'name':{$type:2}});
或
db.stu.find({'name':{$type:'string'}});
2.6 正则查询
MongoDB中查询条件也可以使用正则表达式作为匹配约束。
语法:
db.集合名称.find({字段名:正则表达式});
或
db.集合名称.find({字段名:{$regex:正则表达式[, $options:正则选项]}});
正则表达式格式:/xxx/
正则选项:
- i - 不区分大小写以匹配大小写的情况。
- m - 对于包含锚点的模式(即^对于开始, $对于结尾),在每行的开头或结尾处匹配具有多行值的字符串(可解析单字段中的换行符n)。如果没有此选项,这些锚点将在字符串的开头或结尾处匹配。
- x - 设置x选项后,正则表达式中的非转义的空白字符将被忽略。需要$regex与$options语法
- s - 允许点字符(即.)匹配包括换行符在内的所有字符。需要$regex与$options语法
i,m,x,s可以组合使用。
查询stu集合中name字段以'z'开头的数据
db.stu.find({'name':/^z/});
或
db.stu.find({'name':{$regex:/^z/}});
查询stu集合中name字段以'n'结尾的数据
db.stu.find({'name':/n$/});
或
db.stu.find({'name':{$regex:/n$/}});
查询stu集合中name字段中包含'a'的数据
db.stu.find({'name':/a/});
或
db.stu.find({'name':{$regex:/a/}});
查询stu集合中name字段以'L'开头的数据,且忽略大小写
db.stu.find({'name':/^L/i});
或
db.stu.find({'name':{$regex:/^L/i}});
或
db.stu.find({'name':{$regex:/^L/, $options:'i'}});
查询stu集合中remark字段以'A'开头的数据,且忽略大小写,同时增加锚点
db.stu.find({'name':/^L/im});
或
db.stu.find({'name':{$regex:/^L/im}});
或
db.stu.find({'name':{$regex:/^L/, $options:'im'}});
查询stu集合中name字段已'z'开头、'n'结尾的数据
db.stu.find({'name':/^z.*n$/});
或
db.stu.find({'name':{$regex:/^z.*n$/}});
查询stu集合中name字段以'z'或'l'开头的数据
db.stu.find({'name':{$in:[/^z/, /^l/]}});
查询stu集合中name字段不以'z'开头的数据
db.stu.find({'name':{$not:/^z/}});
查询stu集合中name字段不以'z'或'l'开头的数据
db.stu.find({'name':{$nin:[/^z/, /^l/]}});
2.7 分页查询
在MongoDB中,使用函数limit()和skip()来实现分页数据查询。
2.7.1 limit函数
在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
语法:
db.集合名称.find().limit(查询数量);
查询stu集合中的前10条数据:
db.stu.find().limit(10);
不使用limit函数,默认查询集合中全部文档。如果limit函数不传递参数,也是查询集合中的全部文档。
2.7.2 skip函数
在MongoDB中使用skip()方法来跳过指定数量的文档,skip方法同样接受一个数字参数作为跳过的文档条数。
语法:
db.集合名称.find().[limit(查询数量).]skip(跳过数量);
查询stu集合第二条到最后一条的文档:
db.stu.find().skip(1);
或
db.stu.find().limit().skip(1);
假设每页查询文档数为2,现查询stu集合中第二页文档:
db.stu.find().limit(2).skip(2);
不使用skip函数,不会跳过任何文档,从集合的第一条文档开始查询。如果skip函数不传递参数,也是不跳过任何文档。
2.8 排序
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
语法:
db.集合名称.find().sort({key1:sortType1, key2:sortType2});
查询stu集合中全部文档,以age字段升序排列:
db.stu.find().sort({'age':1});
查询stu集合中全部文档,以age字段升序排列,如果age相同,则以name字段降序排列:
db.stu.find().sort({'age':1, 'name':-1});
3. 更新文档
MongoDB通过update函数与save函数来更新集合中的文档。
3.1 save更新文档
save()函数的作用是保存文档,如果文档存在则覆盖,如果文档不存在则新增。save()函数对文档是否存在的唯一判断标准是"_id"系统唯一字段是否匹配。所以使用save()函数实现更新操作,则必须提供"_id"字段数据。
save()函数的语法是:
db.集合名称.save(
<document>
);
参数document代表要修改的文档内容,要求必须提供"_id"字段数据。
使用save()函数实现更新操作:
db.test.save(
{
"_id" : ObjectId("5d0207e460ad10791be757d2"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "北京尚学堂",
"tags" : [
"mongodb",
"NoSQL"
],
"likes" : 100
}
)
3.2 update更新文档
update() 函数用于更新已存在的文档。
语法格式:
db.集合名称.update(
<query>,
<update>,
< upsert:boolean>,
< multi:boolean>
)
参数说明:
query : update的查询条件,类似sql update更新语法内where后面的内容。
update : update的对象和一些更新的操作符等,也可以理解为sql update查询内set后面的。
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入这个document,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。只有在表达式更新语法中才可使用。
在MongoDB中的update是有两种更新方式,一种是覆盖更新,一种是表达式更新。
覆盖更新:顾名思义,就是通过某条件,将新文档覆盖原有文档。
表达式更新:这种更新方式是通过表达式来实现复杂更新操作,如:字段更新、数值计算、数组操作、字段名修改等。
3.2.1 覆盖更新
通过update方法来更新一个完整的文档:
db.col.update(
{"title" : "MongoDB 教程"},
{
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "北京尚学堂",
"likes" : 100
}
)
3.2.2 表达式更新
语法:
db.集合名称.update(
<query>,
<doc_projection>,
<upsert>,
<multi>
);
doc_projection语法:
{
$表达式:{具体更新规则}
}
① $inc
- 用法:{$inc:{field:value}}
- 作用:对一个数字字段的某个field增加value
- 示例:将name为zhangsan的学生的age增加5
- 命令:db.stu.update({name:"zhangsan"},{$inc:{age:5}})
② $set
- 用法:{$set:{field:value}}
- 作用:把文档中某个字段field的值设为value,如果field不存在,则增加新的字段并赋值为value。
- 示例:把zhangsan的年龄设为23岁
- 命令:db.stu.update({name:"zhangsan"},{$set:{'age':23}})
③ $unset
- 用法:{$unset:{field:1}}
- 作用:删除某个字段field
- 示例:将zhangsan的年龄字段删除
- 命令:db.stu.update({name:"zhangsan"},{$unset:{age:1}})
④ $push
- 用法:{$push:{field:value}}
- 作用:把value追加到field里。注:field只能是数组类型,如果field不存在,会自动插入一个数组类型
- 示例:给zhangsan添加别名"xiaozhang"
- 命令:db.stu.update({name:"zhangsan"},{$push:{"alias":"xiaozhang"}})
⑤ $addToSet
- 用法:{$addToSet:{field:value}}
- 作用:加一个值到数组内,而且只有当这个值在数组中不存在时才增加。
- 示例:往zhangsan的别名字段里添加两个别名A1、A2
- 命令:db.stu.update({name:"zhangsan"},{$addToSet:{"alias":["A1","A2"]}})
注意:此处加入的数据是一个数据为A1和A2的数组对象。并不是将两个数据依次加入alias数组中。
⑥ $pop
- 用法:删除数组内第一个值:{$pop:{field:-1}}、删除数组内最后一个值:{$pop:{field:1}}
- 作用:用于删除数组内的一个值
- 示例:删除zhangsan记录中alias字段中最后一个别名
- 命令:db.stu.update({name:"zhangsan"},{$pop:{"alias":1}})
⑦ $pull
- 用法:{$pull:{field:_value}}
- 作用:从数组field内删除所有等于_value的值
- 示例:删除zhangsan记录中的别名xiaozhang
- 命令:db.stu.update({name:"zhangsan"},{$pull:{"alias":"xiaozhang"}})
⑧ $pullAll
- 用法:{$pullAll:value_array}
- 作用:用法同$pull一样,可以一次性删除数组内的多个值。
- 示例:删除zhangsan记录内的A1和A2别名
- 命令:db.stu.update({name:"zhangsan"},{$pullAll:{"alias":["A1","A2"]}})
⑨ $rename
- 用法:{$rename:{old_field_name:new_field_name}}
- 作用:对字段进行重命名。底层实现是先删除old_field字段,再创建new_field字段。
- 示例:把zhangsan记录的name字段重命名为sname
- 命令:db.stu.update({name:"zhangsan"},{$rename:{"name":"sname"}})
⑩ 更多案例
- 只更新第一条满足条件的记录:
db.col.update( { "count" : { $gt : 1 } } , { $set : { "test2" : "OK"} } );
- 更新全部满足条件的记录:
db.col.update( { "count" : { $gt : 3 } } , { $set : { "test2" : "OK"} },false,true );
- 如果没有符合条件的数据,则添加一条:
db.col.update( { "count" : { $gt : 4 } } , { $set : { "test5" : "OK"} },true,false );
- 如果没有符合条件的数据,则全部添加进去:
db.col.update( { "count" : { $gt : 5 } } , { $set : { "test5" : "OK"} },true,true );
- 只更新第一条记录:(等同第一个)
db.col.update( { "count" : { $lt : 10 } } , { $set : { "count" : 1} },false,false );
4. 删除文档
MongoDB是通过remove()函数、deleteOne()函数、deleteMany()函数来删除集合中的文档。
4.1 remove函数
语法格式是:
db.集合名称.remove(
<query>,
<justOne:boolean>
);
参数说明:
- query:要删除的文档条件,相当于SQL语法中的where子句作用。
- justOne:可选参数,布尔类型,代表是否只删除第一个匹配条件满足的文档。默认值为false,代表删除全部满足匹配条件的文档。
注意:此方法已经过时,官方推荐使用deleteOne()和deleteMany()函数来实现删除操作。且在4.0-版本中,remove()函数并不会真正的释放存储空间,需要使用db.repairDatabase()函数来释放存储空间。在4.2.1版本中,删除函数repairDatabase()。
4.1.1 删除全部
删除stus集合中的全部文档:
db.stus.remove({});
4.1.2 条件删除
- 删除stus集合中age字段为10的文档。
db.stus.remove({'age':10});
- 删除stus集合中age字段大于20的第一个文档。
db.stus.remove({'age':{'$gt':20}}, true);
- 删除stus集合中age字段小于50的全部文档。
db.stus.remove({'age':{'$lt':50}});
或
db.stus.remove({'age':{'$lt':50}}, false);
4.2 deleteOne函数
语法格式:
db.集合名称.deleteOne({<query>});
参数解释:
query:要删除的文档条件,相当于SQL语法中的where子句作用。
删除stus集合中name字段为zhangsan的第一个文档:
db.stus.deleteOne({'name':'zhangsan'});
4.3 deleteMany函数
语法格式:
db.集合名称.deleteMany({<query>});
参数解释:
query:要删除的文档条件,相当于SQL语法中的where子句作用。
删除stus集合中age字段大于10的所有文档:
db.stus.deleteMany({'age':{'$gt':10}});















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









