







 最近有这样一需求,需要获取12123交管查询网站上的全国每个城市对应的城市id和车牌代码。最初的想法是直接用Python写个爬虫,遍历每个城市,然后用Xpath提取DOM节点数据就好了。然而在实际操作中发现城市id的DOM节点如果用简单的获取网页数据的爬虫是取不到id值的,这个城市id值必须用浏览器打开的方式去访问,然后网站的js脚本再动态的将城市id插入DOM节点。于是乎想到了用自动化测试工具来...
最近有这样一需求,需要获取12123交管查询网站上的全国每个城市对应的城市id和车牌代码。最初的想法是直接用Python写个爬虫,遍历每个城市,然后用Xpath提取DOM节点数据就好了。然而在实际操作中发现城市id的DOM节点如果用简单的获取网页数据的爬虫是取不到id值的,这个城市id值必须用浏览器打开的方式去访问,然后网站的js脚本再动态的将城市id插入DOM节点。于是乎想到了用自动化测试工具来...
最近有这样一需求,需要获取12123交管查询网站上的全国每个城市对应的城市id和车牌代码。最初的想法是直接用Python写个爬虫,遍历每个城市,然后用Xpath提取DOM节点数据就好了。然而在实际操作中发现城市id的DOM节点如果用简单的获取网页数据的爬虫是取不到id值的,这个城市id值必须用浏览器打开的方式去访问,然后网站的js脚本再动态的将城市id插入DOM节点。于是乎想到了用自动化测试工具来做,使用selenium库来操作webdriver,驱动Chrome浏览器进行自动化操作。
由于这个网站有一点特殊,并没有在同一个页面中有全部城市的id和车牌代码,每个城市都是一个单独的二级域名链接。并且城市id使用js动态加载,所以这里就用蠢一点的方法,自动获取到每个城市的链接,然后用浏览器自动化模式去逐个访问再Xpath提取出内容。
当然,这里的重复劳动力交给计算机就好,我们只需要把程序写好。
使用Chrome浏览器打开12123的城市列表选择页面 http://m.12123.com/city.html
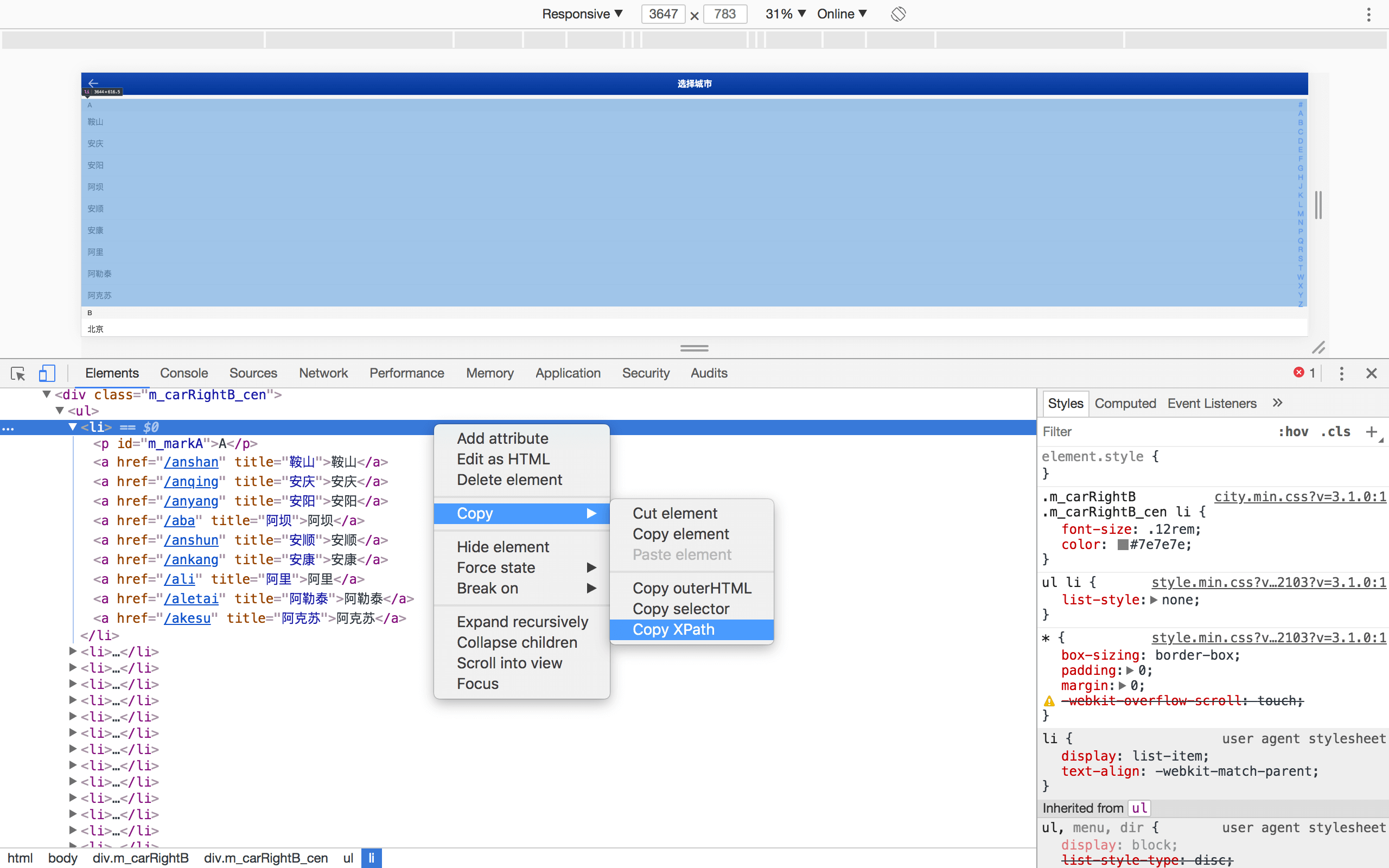
右键,审查元素,发现所有的城市都在ul 的 li标签下。
只需要把li的元素Xpath拷贝出来,提取到城市列表后遍历每个列表的链接,再用浏览器自动化去访问每个城市的链接,最后用相同的方法提取出数据即可。
拷贝出来的Xpath如下
1/html/body/div[2]/div[3]/ul/li
用Xpa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7546
7546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









